Dstaevops Data - practical data cases
National language Support (NLS), data representations
data representation patterns as operational constructs.

National Languages, why is it critical?
There are a lot of questions to answer:
📚 Information data is describing?
⚙ Relationships data elements?
🎭 Who is using data for what proces?
⚖ Inventory information being used ?
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.
Contents
| Reference | Topic | Squad |
| Intro | data representation patterns as operational constructs. | 01.01 |
| data interfaces | Encoding used for transcoding. | 02.01 |
| encoding choice | Considerations choosing encodings. | 03.01 |
| functions & data | Functions and data representions. | 04.01 |
| BK dates & markers | Dates time and other logical keys. | 05.01 |
| What next | Data representations - Executing & Optimisations. | 06.00 |
| | Following steps | 06.02 |
Progress
- 2020 week 06
- Page as new getting filled although an old topic.
- The dates topic had to wait for completion, the patterns for lineage, process cycle was required to do first.
Duality service requests

sdlc: Has strict standards set by the organisation on encoding, artefact contexts and unit measures. Although by use of several software tools discrependancies are possible.
bianl: using business artefacts and/or having defined events describing the value stream (assembly line) process is:
giving different ways to model information.
gives requirements to the tooling configuration

bpm tiny: I an small organisation there is no need having split up in smaller units.
The language setting between systems and data representations not a problem having priority.
bpm big: Splitting up big environments into smaller ones will make those more manageable. It will have impact on the informations that needs to be shared.
Language settings and data representations mismatches will get problematic and needs standardiesed to get an overall usage.

Encoding used for transcoding.
Integration of process servers and data servers is an infrastructure alignments of settings (scripts) and configurations (text files).
SAS is an example with their nice available documentation. Other products / tools are not different in this.
Drivers & for accessing data located externally
In this concept of drivers the data server is indicated as "Server" and the requesting machine the "Client".
No matter for what role that requesting machine will handle and no matter what kind of name are used for that.
For someone not used to that: a processing server with a lot of local data is the client.
The figure from -(Programming Documentation SAS/ACCESS for Relational Databases- :
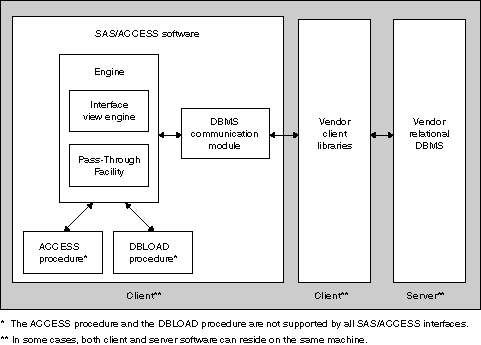 Each SAS/ACCESS interface consists of one or more data access engines that translate Read and Write requests from SAS into appropriate calls for a specific DBMS.
The following image depicts the relationship between a SAS/ACCESS interface and a relational DBMS.
Each SAS/ACCESS interface consists of one or more data access engines that translate Read and Write requests from SAS into appropriate calls for a specific DBMS.
The following image depicts the relationship between a SAS/ACCESS interface and a relational DBMS.
These relationship shows three configuration places:
- Third party vendor default settings
In a user session there are user default as option
- Third party Vendor client settings as default
sometimes possible overwritten by user options
- Client settings where in this case the SAS system is the client
The places to change a SAS configuration setting are overwhelming.
When doing a file transfer storing in a location managed by he filesystem of the OS (operating system) the language setting of the OS is added as an additional component.
Configuring the vendor client software is also done at the OS level.
⚙ ⚖ The result is managing four locations to with language settings. When the client are duplicated, server are clustered the number of machines increases rapidly.

Considerations choosing encodings.
The number of bytes is variable (1-4) when using Unicode utf-8. Classic single byte representation does not have that variability.
SAS is an example with their nice available documentation. Other products / tools are not different in this.
SAS 9.4 NLS, SAS viya - utf8 mandatory
from: An Introduction to SAS Viya 3.4 Programming:
The CAS server supports only UTF-8 encoding. UTF-8 is variable-width, multi-byte encoding. One UTF-8 character can be 1?4 bytes in length.
If your SAS or SAS Viya session encoding is not UTF-8, then the data that is read to a CAS table must be transcoded to UTF-8.
You can set your SAS or SAS Viya session to UTF-8 in order to avoid the transcoding of data.
If you want to change your session encoding, see SAS Viya 3.4 Administration: General Servers and Services.
If your SAS or SAS Viya session is not UTF-8, the data must be transcoded to UTF-8 when it is loaded to a caslib.
When double-byte character set (DBCS) characters and some single-byte character set (SBCS) characters are transcoded to UTF-8, they require additional bytes to represent a character.
The beste decision would be using utf8 in all sessions and all data sources. That would imply a migration of almost anything and changing the mindset of developers and users.
The history of a single byte characterset still is the default.
Default SAS Session Encoding Values:
Operating
Environment | Default
ENCODING= Value |
Description |
| z/OS | OPEN_ED-1047 | OpenEdition EBCDIC cp1047-Latin1 |
| UNIX | Latin1 | Western (ISO) |
| Windows | WLatin1 | Western (Windows) |
💣 These are single byte classic encodings.
Windows and Unix are supporting utf-8, z/OS not.
sorting not consistent using different encodings.
From: National Language Support (NLS): Reference Guide (SAS)
Overview of Collating Sequence:
The collating sequence is the order in which characters are sorted. For example, when the SORT procedure is executed, the collating sequence determines the sort order
(higher, lower, or equal to) of a particular character in relation to other characters.
The default collating sequence is binary collation, which sorts characters according to each character´s location in the code page of the session encoding.
(The session encoding is the default encoding for a SAS session. The default encoding can be specified by using various SAS language elements.)
The sort order corresponds directly to the arrangement of the code points within the code page.
Binary collation is the fastest type of collation because it is the most efficient for the computer.
However, locating characters within a binary-collated report might be difficult if you are not familiar with this method.
For example, a binary-collated report lists words beginning with uppercase characters separately from words beginning with lowercase characters.
It lists words beginning with accented characters after words beginning with unaccented characters.
Therefore, for ASCII-based encodings, the capital letter Z precedes the lowercase letter a. Similarly, for EBCDIC-based encodings, the lowercase letter z precedes the capital letter A.
You can request an alternate collating sequence that overrides the binary collation. To request an alternate collating sequence, specify one of the following sequences:
- a translation table name
- an encoding value
- linguistic collation
💣 Having a sort done remotely (in database) but in a different encoding or unknown defined sort definiton order, the result is an unsorted dataset.
Resorting of a dataset that is ordered in some way will run faster than a random one. It will cost some time and resorces but is saver to do when the ordering matters.

Functions and data representions.
The number of bytes is variable when using unicode. Al kind of classic functions based on 1 byte = 1 character will have to be replaced by nultibute support ones.
SAS is an example with their nice available documentation. Other products / tools are not different in this.
string manipulation and comparison
From: National Language Support (NLS): Reference Guide (SAS)
⚠ All kind of classic functions based on 1 byte = 1 character will have to be replaced by multibyte support ones.
SAS provides string functions and CALL routines that enable you to easily manipulate your character data. Many of the original SAS string functions assume that the size of one character is always 1 byte. This process works well for data in a single-byte character set (SBCS). However, when some of these functions and CALL routines are used with data in a double-byte character set (DBCS) or a multi-byte character set (MBCS) such as UTF-8, the data is often handled improperly, and the string functions produce incorrect results.
To solve this problem SAS introduced a set of string functions and CALL routines, called K functions, for those string manipulations where DBCS or MBCS data must be handled carefully. The K functions do not make assumptions about the size of a character in a string. SAS String Functions shows the level of I18N compatibility for each SAS string function. I18N is the abbreviation for internationalization.
Compatibility indicates whether a program using a particular string function can be adapted to different languages and locales without program changes.
decimal point / comma, conventions
The (CSV) comma seperated approach is confusing because of different use in langauges by the decimal point convention using the comma.
⚠ This was en is a common failure with CSV files, interpretation of the data is not clearly defined. A tab delimited file for CSV files is more reliable.
Older systems are transporting it s int
SAS/ACCESS? 9.4 for Relational Databases: Reference
DB2 DECPOINT= option. The decpoint-value argument can be a period (.) or a comma (,). The default is a period (.).
There is for every interface a chapter "Data Types for .. ".
Every column in a table has a name and a data type. The data type tells ... how much physical storage to set aside for the column and the form in which the data is stored.
This section includes information about Oracle data types, nulls, default values, and data conversions.
There is an important note:
💣
When you read values that contain more than 15 decimal digits of precision from a database into SAS, the values that SAS reads are rounded to meet this condition.
When you use a large numeric value in a WHERE clause, this rounding can cause unexpected results, such as not selecting desired rows.
For noncomputational purposes, such as storing ID values or credit card numbers, you can read the data in as character data.
It is better to use always character data when it is an ID value.
The transfoming of data is based on defined SAS formats for a variable. The default conversion has an overwrite option.
read: DBSASTYPE=
you can use this option to override the default and assign a SAS data type to each specified DBMS column.
write:
use DBTYPE= to override the default data type chosen by the SAS/ACCESS engine.
Numerics - floating
From: SAS Language Reference: Concepts / Numerical Accuracy in SAS Software:
💣
For any given variable length, the maximum integer varies by host.
This is because mainframes have different specifications for storing floating-point numbers than UNIX and PC machines do.
The reason behind is not by caused by software byt by the hardware more specific how the processor handles floating instrcutions.
CAUTION: Use the full 8 bytes to store variables that contain real numbers.
date & time
From: SAS Language Reference: Concepts / About SAS Date, Time, and Datetime
💣
SAS uses SAS date values, which are ordinal numbers, to calculate dates. SAS date values represent the number of days between January 1, 1960, and a specified date.
and ⚠
SAS uses the Julian format (ordinal date) definition of dates.
We are normally using a gregorian calendar, the difference is in the leap-years. Java based fucntions SAS Visual analytics use the gregorian one.
Interfacing wiht any dbms or others system is not using the same ordinal numbers, there is a convesion.

Dates time and other logical keys.
🔰 Events are date time (UTC) specific in split second, used as markers. Not suitable for labels, indexes.
🔰 Reporting, analytics (financial) using aggregation goes by: date, week, month, quarter, year. Detail classifications at daily´s is adequate enough.
🔰 For day of week and time of day with process flow variation analyses a time classification is needed.
Value stream & recurring financial events
The product flow with an assembly (having parts from suppliers) up to delivery is obvious recognized when physical.
When the product is administrative the same steps and same flow is applicable. Other words are possible used for same kind of roles.

Figure: Not the assembly line of toyata.
Even when the products are physical there is a lot of administrative work.
When the products are adminitrative there is a lot of administrative work on the administrative product. Just think of an insurance policy or a banking account.
Date types generic usage
Events are marked by a date-time date and possible an time stamp. Issues are:
- The technical representation as data is not standardized.
- The goal and use of an event is not standardized.
- financial, date stamps in YYYYMMDD (background iso8601)
- marketing, date stamps and region, customer attributes, sales person
- product assembly date stamps, time stamps HHMM worker, machines
When international date - time stamps are involved any conversions will need adjustments to agree on.
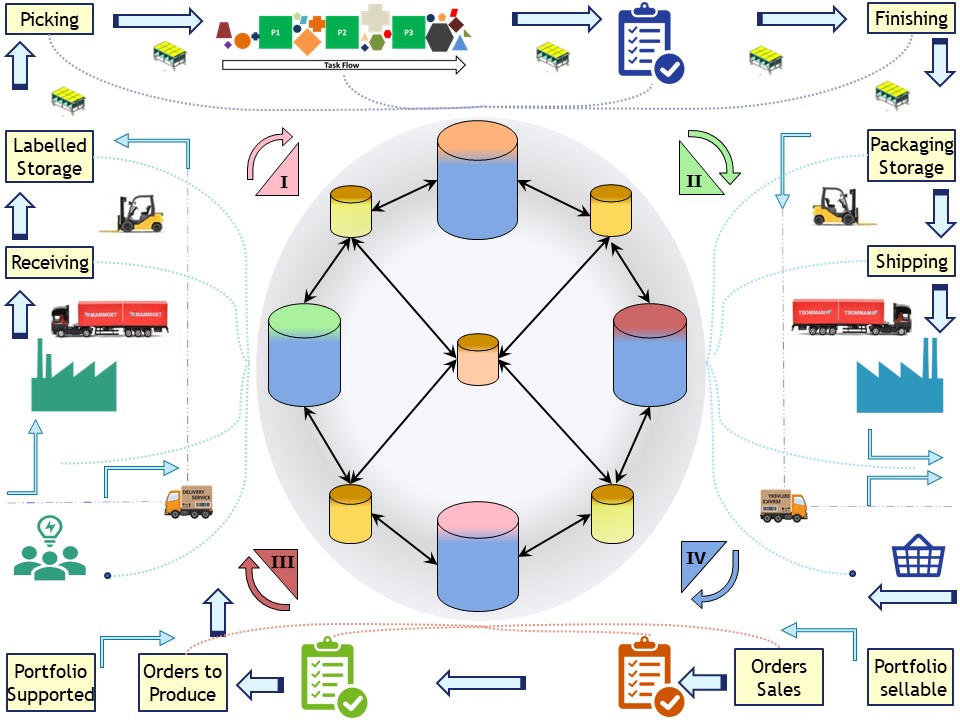
When the process is the consolidation of financial business reports of a holding, the same figure (below) is applicable.
The primary process is around the borders.
Administrations: inner circle vertical (manufacture/control), horizontal (in/out)
Business analytics support are the diagonals that are coordinate in a central view.
Date stamp YYYYMMDD
In this way using the characters 0123456789 for year (YYYY), month (MM), day(DD) it is a well recognize western calendar date.
Using a character format type in the basic Latin1 utf8 will cost 8 bytes, an Unicode 32 store (DBMS specific) 32 bytes.
DBMS systems are having the integer type that is a good candidate. SAS is only having character types and floating numbers.
Doing data transport between systems it will work well with characters. For integrity: avoidance of any binary type is good practice.
The character implementation is the best choice.
Using the character type with the digits has the advantages of:
- easy substring manipulation
- avoiding the character to binary number conversion and back
- Partitioning the dataset - table on date stamps easy to implement
Time stamp HHMM, shift, zzzz
A time stamp using characters 0123456789 for HHMM using 4 bytes (16 with utf32) is similar. It is only needed analysing what is happening during a day.
A shift class indicator is an additional classificiation.
Global timezones are more complicated.
timeanddate.com summertime wintertime country differences in 15 minutes. The date can get another value when converted to another location.
Avoiding this details by doing an definiton on meanings when doing classifications and aggreations makes more sense.

Data representations - Executing & Optimisations.
Pattern: Design & build environments setting the encoding.
Which encoding language is chosen for used components and how this is interacting with other systems is a fundamental decision to make.
Trying to change this later is having a big impact.
Pattern: Design & build Data flows using appropriate data representations.
Which data in what technical representation including numbers, characters, text, temporal and geospatial should have strict data governance guidelines.
Trying to adjust this later when technical conflicts and information loss is happening is a mission impossible.
Pattern: use standarized event date keys with appropiate representation.
Using dates with financial report goal the level of detail by date usually sufficënt. The moment of payment is a detailed event in the base operational record.
Use: YYYYMMDD in a 8-character 0123456789 representation.
Using dates datetimes in a native formats of any used tool will add unnecessary complexity for conversions when used with business keys.
Those native format functions will work well when used on measurements (facts).
Pattern: use standarized event in time keys with appropiate representation.
Using time keys and a shift indication, day of week will be appropiate when wanting tot analyse the variations during hours in the value stream flow.
Use: HHMM in a 4-character 0123456789 representation.
Using time s datetimes in a native formats of any used tool will add unnecessary complexity.

History as memories.
Processing information was done in old times with technical limitations of those times. There is no reason to do things as always has been done.
🚧 The single byte character thinking to get abandoned for seeing bytes and characters different.
🚧 Assuming identifiers like bank account number and license plate number are really numbers in the way of using hollerith cards is an idea to get rid of. There are more historical data representation causing problems these days.
🚧 Working with business keys based on summarized date events using technical details of a sepecific DBMS.
Dependicies other patterns
This page is a pattern on scheduling.
Within the scope of metadata there are more patterns like exchaning information (data) , building private metadata and securing a complete environment.
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.