
Command & Control Realisations
W-1 Command & Control - acting on situations
W-1.1 Contents
⚙ W-1.1.1 Global content

The data explosion. The change is the ammount we are collecting measuring processes as new information (edge).
📚 Information requests.
⚙ measurements monitoring.
🎭 Agility for changes?
⚖ solution & performance acceptable?
🔰 Too fast ..
previous.
⚙ W-1.1.2 Local content
| Reference | Squad | Abbrevation |
| W-1 Command & Control - acting on situations | |
| W-1.1 Contents | contents | Contents |
| W-1.1.1 Global content | |
| W-1.1.2 Local content | |
| W-1.1.3 Guide reading this page | |
| W-1.1.4 Progress | |
| W-1.2 Floor plans, ordered dimensions | C6autist_02 | I_Floor |
| W-1.2.1 Context information technology: master data | |
| W-1.2.2 Definitions products, goods, services: master data | |
| W-1.2.3 Services orientation at information technology | |
| W-1.2.4 Roles tasks levels in Information Services | |
| W-1.3 Steering roles tasks | C6autist_03 | C_Tasks |
| W-1.3.1 Technical "how to" for understanding steering | |
| W-1.3.2 The what to start operational steering | |
| W-1.3.3 Understanding the data flow, data lineage | |
| W-1.3.4 Roles tasks levels supporting Information Services | |
| W-1.4 Culture building people | C6autist_04 | H_Culture |
| W-1.4.1 Project management, the change challenges | |
| W-1.4.2 Project into Programme into Portfolio (3P) | |
| W-1.4.3 Managing flow in activities, portfolios | |
| W-1.4.4 CPO, CPE, Managing living viable systems | |
| W-1.5 Sound underpinned theory, foundation | C6autist_05 | C_Theory |
| W-1.5.1 Chosen colours and shapes for the floor plans | |
| W-1.5.2 The viable system, conscious decisions | |
| W-1.5.3 The viable system, autonomic technology | |
| W-1.5.4 Mediation: Technical autonomy vs organisational control | |
| W-1.6 Maturity 0: Strategy impact understood | C6autist_06 | CMM0-SIM |
| W-1.6.1 Determining the position, the situation | |
| W-1.6.2 Individual logical irrational together | |
| W-1.6.3 Value stream VaSM vs Viable system ViSM | |
| W-1.6.4 Flexibility in architecture, engineering, design | |
| W-2 Command & Control working on gaps for solutions | |
| W-2.1 Understanding ICT Service Gap types | C6authow_01 | PT_GAP |
| W-2.2.1 Understanding the technical design processes | |
| W-2.2.2 Understanding technical performance choices | |
| W-2.2.3 Data governance, knowing wat is going on | |
| W-2.2.4 Data governance, knowing who is acting at what | |
| W-2.2 Floor plans, understanding ICT operating value streams | C6authow_02 | ✅-TechSec |
| W-2.2.1 Technology quality & risk rating | |
| W-2.2.2 Information process: Identities, Access, incident response | |
| W-2.2.3 Safety Monitoring for anamolies by open source issues | |
| W-2.2.4 Safety Monitoring for anamolies known internal processes | |
| W-2.3 Information systems: Actuators - Steers | C6authow_03 | C_Steer |
| W-2.3.1 Communicating a shared value, mission for understanding | |
| W-2.3.2 Communications, variety & velocity and regulators | |
| W-2.3.3 Communications, variety & velocity within systems | |
| W-2.3.4 Product vs Service provider & Top-down vs Bottom-up | |
| W-2.4 Roles tasks in the organisation | C6authow_04 | C&C_PT |
| W-2.4.1 Team member and organic system roles | |
| W-2.4.2 The ignored Engineer executing everything | |
| W-2.4.3 Mediation technology: functionality - functioning | |
| W-2.4.4 Interactions in the organic viable system | |
| W-2.5 Sound underpinned anatomy of a viable system | C6authow_05 | ✅-Morphing |
| W-2.5.1 Fundaments of activities processes (0-1-2, 4-5) | |
| W-2.5.2 Operational deliveries, functioning portfolio (1-2) | |
| W-2.5.3 Changing products, services, functionality portfolio (2-3) | |
| W-2.5.4 Autonomic compliancy control & conscious decisions (3-4) | |
| W-2.6 Maturity 3: Enable strategy to operations | C6authow_06 | CMM3-SIM |
| W-2.6.1 SIMF-VSM Safety with Technology at Technology | |
| W-2.6.2 SIMF-VSM Uncertainties imperfections at processes, persons | |
| W-2.6.3 Dichotomy: generic approaches vs local in house | |
| W-2.6.4 SIMF-VSM Multidemensional perspectives & revised context | |
| W-3 Command & Control planning for innovations | |
| W-3.1 Information processing in the information age | C6autsll_01 | I_Vuca |
| W-3.1.1 Master data, understanding information | |
| W-3.1.2 Volatile master metadata and information chains | |
| W-3.1.3 Strategy conflicts: safe platforms, business applications | |
| W-3.1.4 Strategy conflicts solution: change to systems thinking | |
| W-3.2 Floor plans, optimizing value streams | C6autsll_02 | ✅-AppSec |
| W-3.2.1 Information quality & risk rating | |
| W-3.2.2 Chain of Information change & Master data Context | |
| W-3.2.3 Information knowledge qualities by product, service | |
| W-3.2.4 Information impact by product, service | |
| W-3.3 Why to steer in the information landscape | C6autsll_03 | C_Bani |
| W-3.3.1 Understanding information: data, processes, actions, results | |
| W-3.3.2 Understanding goals with needed associated change | |
| W-3.3.3 Activities in the organisation for the organisation | |
| W-3.3.4 6C-Control is not specific it is very generic | |
| W-3.4 Visions & missions boardroom results | C6autsll_04 | C_Vision |
| W-3.4.1 How to Structure engineering the enterprise | |
| W-3.4.2 Learning structuring the enterprise by examples | |
| W-3.4.3 Beliefs, social networks influencing the enterprise | |
| W-3.4.4 The closed loop in structuring the enterprise | |
| W-3.5 Sound underpinned theory, improvements | C6autsll_05 | ✅-fractals |
| W-3.5.1 A structured enterprise, the organic cycle | |
| W-3.5.2 The structured enterprise, backend and frontend | |
| W-3.5.3 A structured enterprise, the hidden organisatonal synapse | |
| W-3.5.4 Primary and indispensable secondary processes in the whole | |
| W-3.6 Maturity 5: Strategy visions adding value | C6autsll_06 | CMM5-SIM |
| W-3.6.1 SIMF-VSM Safety with Information at Technology | |
| W-3.6.2 Structuring viable systems with competing dichotomies | |
| W-3.6.3 People authoritative leader "PAL" - Operational Units "OUs" | |
| W-3.6.4 A generic context of the 6C in viable systems | |
| W-3.6.5 Following steps | |
⚖ M-1.1.3 Guide reading this page
Avoiding the tooligan trap.
What's a 'Tooligan'?
How often do you find yourself falling in love with a tool and then finding a problem so that you can use it?
Whenever I learn something new, I often want to go and try it out and test it on the peeps or systems that I work with, so I start with the tools and look for a problem.
I see this in many organisations and teams that I have worked with.
I was talking to a friend expressing my frustration about the number of tools they used that didn't seem to solve any problem but were just there for the sake of a tool.
- 😲 "Ah," he said, "Tooligans!"
- "What? " I asked "Yes, 'Tooligans'! They have a problem, so they buy a tool or implement a new tool to solve it.
But sometimes they don't understand the real problem and if the tool will solve it."
- "That's exactly it!" I exclaimed, "Tools are everywhere, and the problems are still there."
As humans, we are innately tool makers and users.
Tools can help us express our ideas better, allow us to create beautiful things and solve real problems.
- How do we know we have the right tool for the job?
- How do we know that it will solve the problem for us?
- How do we know if it will improve things or have the opposite effect?
We might want to ask a different question:
- What tools must we use to apply our practices effectively?
- And from there, the next logical question is, what are our practices?
- What are the things that we do to get things done around here?
This is a great question, but probably not the first one to ask.
👉🏾 How will we know what we do is getting us what we want?
Before deciding what we will do, we might want to ask…
- What are the principles that are important to apply to get work done?
- What do we want to leverage to reach more of what we value?
And so before we decide how to shift the system, we must understand what we value.
- Practices (what we do)
Deciding on what we value can help us understand what to optimise for, for example. We optimise for speed because we think that will enable us to get 'X' done faster.
- Tools (what we use)
- Principles
Human work systems behave in specific ways, and some patterns and levers influence how a system works for better or worse.
Principles remain true regardless of context, so understanding which principles can be leveraged can help shift a system positively.

What are the system's needs?
This brings us to possibly the first question we want to ask:
👉🏾 "What problems are we solving here?"
When we look at things this way, we use a model that I love, The Spine Model.
The Spine Model encourages us to start with understanding the system of work and the Needs of that system or the problem we are trying to solve.
It asks us to identify what we Value and what we want to optimise for.
- Once we know what we like to optimise, we can look for Principles and levers that apply.
- Once we know what we value/want to optimise and what principles are necessary, we can decide what to do.
- What Practices will we use?
- Then, finally, we can choose the tools that will support all of this.
Let's walk an example through and see.
- Problem: A team is having trouble keeping track of their busy work.
They don't know who is busy with what and where it is in their process. It also takes a long time for things to get delivered, and they don't know why.
hey want to be able to see what is going on so that they can make improvements and be faster.
- Needs: Visibility of the work and the process of how work flows.
- Values:
- Transparency,
- Speed.
- Principles:
- Visualisation of the work and process to create transparency,
- Work In Progress Limits to help with speed and delivery,
- Feedback loops to help with improvements and alignment,
- Metrics to know if improvements are happening.
- Practices:
- Visualise the work and the flow of work,
- Get together daily to sync, Weekly to plan, and every two weeks to improve,
- Measure lead time and cycle time and look for improvements.
- Tools:
We have many options now, but using a checklist for our practices and principles can help us decide and ensure that the tool gives us as much of what we need as possible.
We can also start very low-tech with a physical board or wall if we are collocated with something fast, cheap, and effortless that we can iterate over instead of something rigid, expensive and challenging to implement.
Getting the tooligans into the system's needs
"If you want a straight spine, you have to start at the top, at Needs and work down iteratively."
😱 I have seen so many organisations do the opposite.
They start with a tool (Jira, Pivotal Tracker, Microsoft Azure, etc.), and then that tool defines their practices.
😲 Those practices shape the principles that apply and determine what optimisations are possible.
More often than not, the original problem remains, and sometimes, the cycle continues with the following tool.
“The value of the Spine Model is to enable thinking and communication, heterodoxy.”
😉 The Spine Model can help us put our critical thinking hats on and ensure we are solving the right problem.
It's about communication and shared understanding, which can save us time and money on useless tools and unsolved problems in the long term.
👉🏾 When I find myself being a "tooligan", I remind myself to begin with Needs.
⚒ M-1.1.4 Progress
done and currently working on:
- 2020 week 05
- Setting wiht the mind for a technology approach.
- Splitting page into more logical parapgraphs.
- 2024 week 47
- Web content redesign with Jabes being pivotal started for this page.
- The goal for command & control has become more clear by:
- Knowing what the conceptual gaps in command & controls are from theoretical perspectives
- Insight needed for improvements according Gemba, using the shop-floor
- The old content integrating and moving to the technical system serve area where applicable.
- 2024 week 50
- Getting to the possible realisations is not easy.
- The goal for command & control:
- Using the viable system 3d system model according Gemba, shop-floor
- Details for sophisticated technical details in information safety and information quality
- The logical growth path for introducing into an existing system by the floor levels
- The first chapters W-1.1 to W-1.6 getting an aligned idea for content draft level.
- 2024 week 51
- Getting to the possible realisations is not easy.
- Processed the VSM theory with some tweaks, hopefully as improvements.
- Updates in the text W-1.1 to W-1.6 for alignment
- Adding the principles for an infomations processing systems in a VSM setting
- Chapters W-2.1 to W-2.6 got an idea in content draft level.
- 2025 week 1
- Chapters W-3.1 to W-3.6 got an idea in content draft level.
- Thia page is in draft ready for the time being.
Planning to do & changes:
- The Vism is only the operational part, this one was build up from a simple 9 plane.
The strategy part is missing for the higher level system-5 and system-4.
- The replication will mirror some things
- The replication will focus on the other dichotomy
- Chief Product officer as central nerve:
- must be technically strong, Customer oriented
- organizational influence, cooperation
- mental toughness is crucial, Cost awareness

W-1.2 Floor plans, ordered dimensions
Building any non trivial construction is going by several stages.
These are:
- high level design & planning
- detailed design & realisation
- evaluation & corrections
Non trivial means it will be repeated for improved positions.
Before any design, tools are needed for measuring what is going on.
Without knowing the situation or direction there is no hope in achieving a destination by improvements.
⚖ W-1.2.1 Context information technology: master data
Functional data governance 101.
There is no options in avoiding accountability.
Foundation managing information processes products services for data, information is functional about:
- The context purpose: 📚 it is describing.
- Who is using and when: 🎭 access control and monitoring
- Reliability availability: 👁 Transactional integirty, optional system recovery
- Relationships: ⚙ between logical elements (meta context plan)
- An inventory: ⚖ What is really being important & used
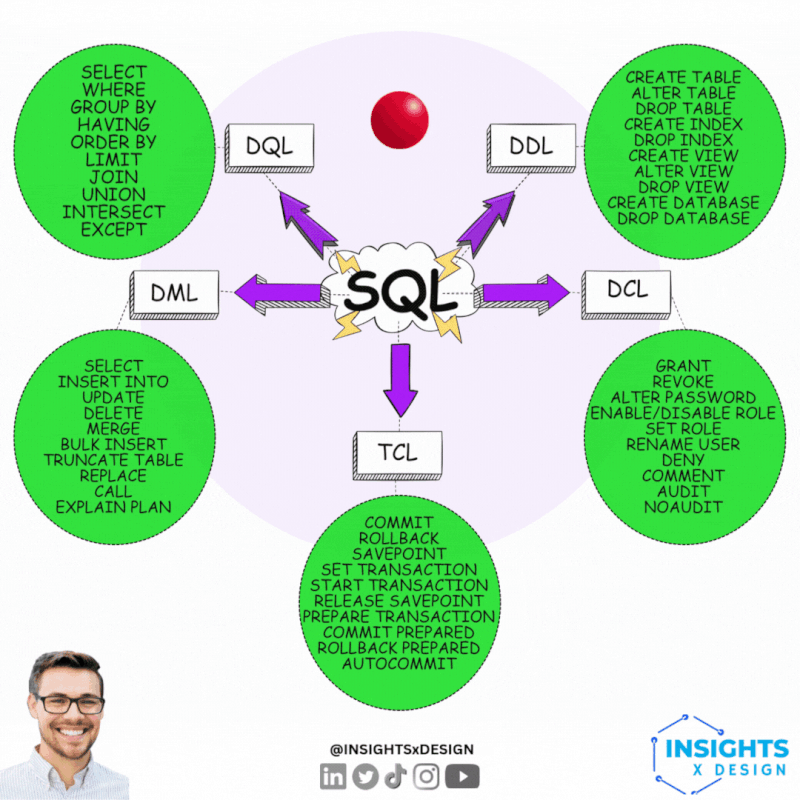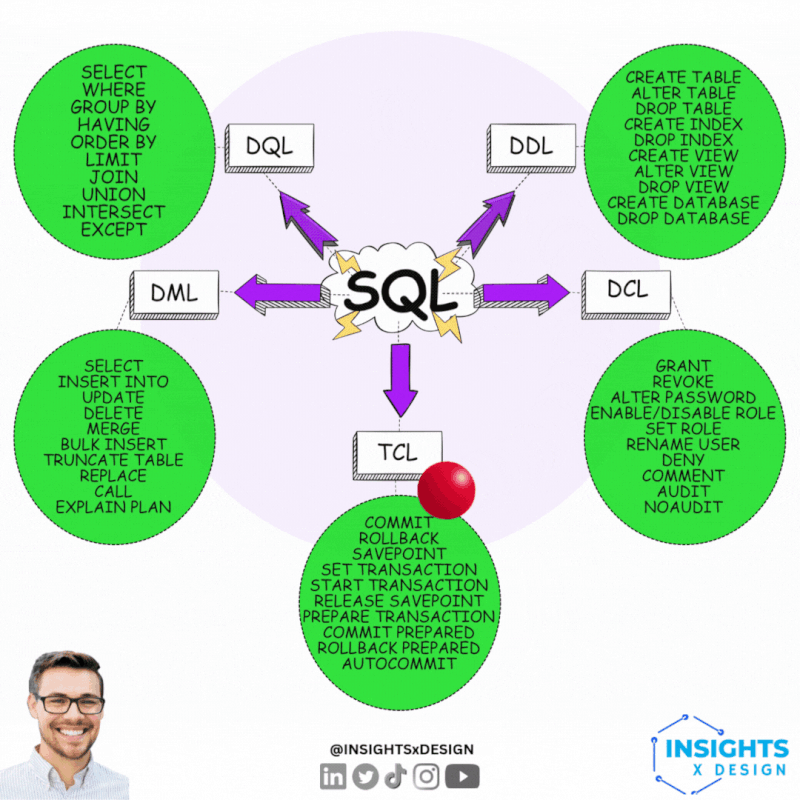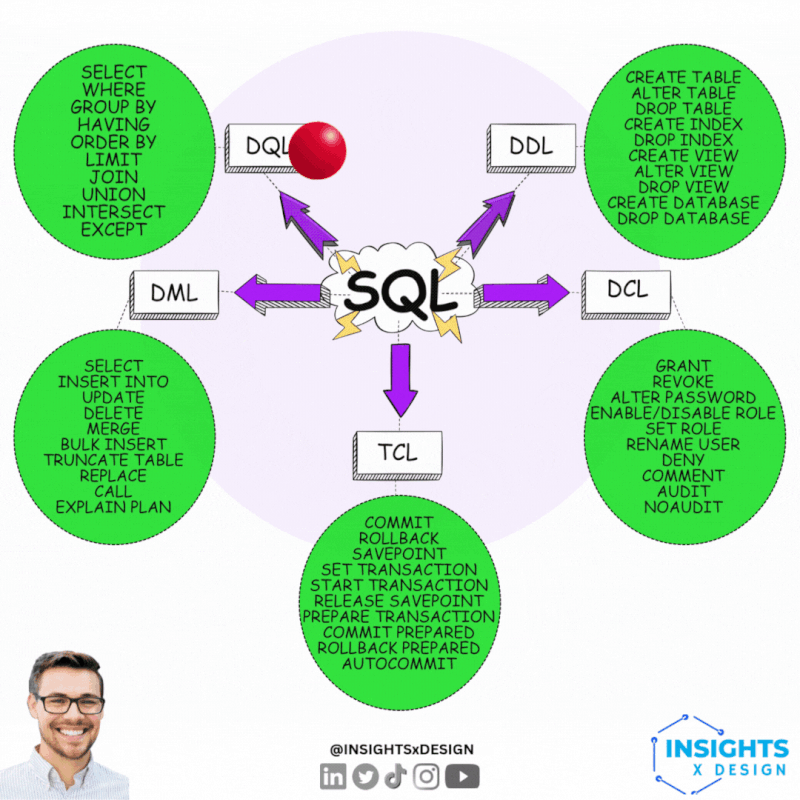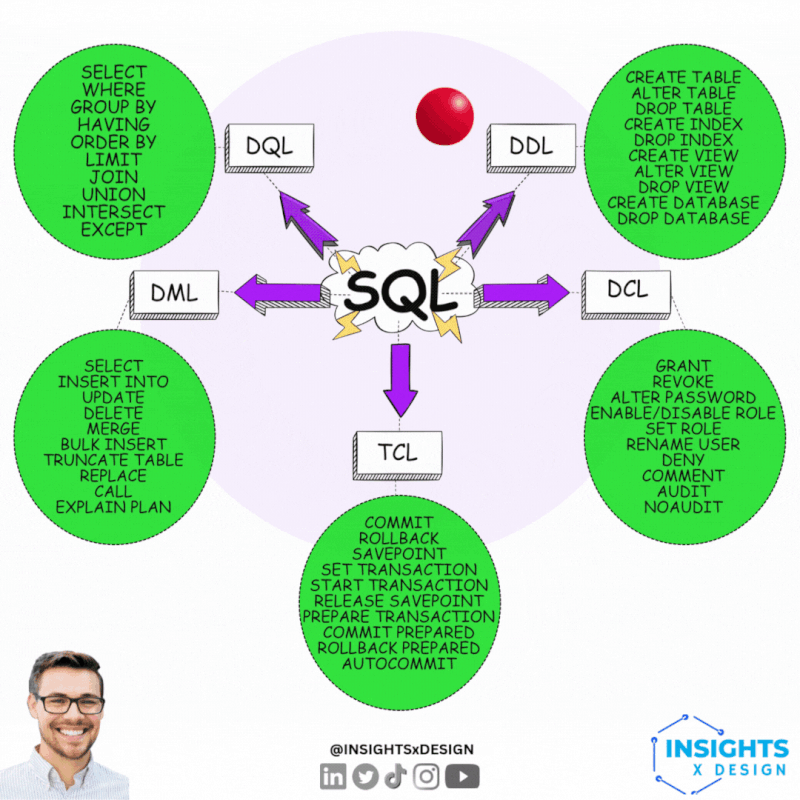
Technical data governance 101.
Using a relational database for managing information is one of the many technical options to realize the functional information processing.
The technical translation of the functional context uses a different language:
- DDL Data Declaring: 📚
The translation from logical to technical has functional impact. Transactional processing is very different compared to analytics.
- DCL Data Control: 🎭 This is partially "access control", "information security".
That is a generic functional topic for another level of tasks & responsibilities.
- TCL Transaction Control: 👁 Loosing information can be catastrofal when it is about legal agreements.
An example of critical systems is payments.
- DML Data Manipulation: ⚙ Modification
- DQL Data Querying: ⚖ Usage
Avoiding misunderstanding: platforms & applications
What is a
"platform"
is as confusing by lack of a shared definition as "the application". Not clear anymore if tangible are machines, servers.
❶
In IT, a platform is any hardware or software used to host an application or service. ...
The term platform may also go beyond simply describing the underlying architecture to also include software that is built upon the architecture.
For example, the adoption of virtual machines in an enterprise requires a hypervisor platform. ...
❷ Tools are software but inseparatable parts of a platform.
Even though an application may require an underlying computing system, such as a particular OS and server or storage hardware, an application may be considered a platform when it is used as a tool for performing meaningful work. ...
For example:
- Structured Query Language (SQL) is a database application. But it is frequently used as a component in other functions, such as logging, analytics, customer relationship management and enterprise resource planning systems. SQL may be referred to as a platform.
- Similarly, a web server application may be considered a platform because it is used to operate the business storefront or user/partner portal.
- Software stacks, combinations of software components, that facilitate the deployment of other complex services for the business may also be referred to as platforms.
The goal of platform engineering is to create organized groups of resources and services that developers can use without needing to deeply understand or directly manage them.
These organized groups, called platforms, are often built using many of the same software development skills and abilities found across DevOps teams.
❸ The "system programmer" role as defined by IBM in the mainframe context (80's).
The platform team uses tool experts to understand developer needs, select the best tools for the required tasks, perform integrations and automations, and troubleshoot and maintain the established platform over time. ...
But platforms don't just happen, and one size never fits all. Platforms themselves are typically considered a product, and they must be created and maintained for the business and its specific software development and productivity needs.
Because platforms are composed of discrete components and services, they can be changed and enhanced over time.
Using a shared environment, shared way of practices, controlled quality for the production environment, there is no other option than a regulated centralised approach for platforms.
It are the equivalents of machinery in the industry. These should usually not be installed nor maintained by the intended operators of the machinery. It is far too demanding to combine those skills to excel.
⚖ W-1.2.2 Definitions products, goods, services: master data
Products, Goods, Services, what is it about?
There is not a good single reference understanding the mastedata object container "service".
Combining multiple sources is the best option. Links with ideas about services, goods for products:
Using chatgpt result for the definition of Services and from the linked sources:
Services are intangible activities or benefits that an organization provides to consumers in exchange for money or something else of value.
Products: Goods vs Services
Differences are:
- Tangibility: Goods are tangible and can be seen and touched, while services are intangible.
- Storage: Goods can be stored and inventoried, whereas services perish if not consumed.
Services cannot be touched, stored, or transported
Service-relevant resources, processes, and systems are assigned for service delivery during a specific period in time.
- Production and Consumption: Goods are produced, then sold, and then consumed.
Goods are sold first and then produced and consumed simultaneously.
❹ Unique characteristics of Services:
- Intangibility: Services cannot be seen, tasted, felt, heard, or smelled before they are bought. They are performances rather than objects.
- Inseparability: Services are produced and consumed simultaneously. The service provider and the consumer must be present for the transaction to occur.
- Perishability: Services cannot be stored for later use. If not used, the opportunity to provide the service is lost.
- Variability: The quality of services can vary greatly depending on who provides them and when, where, and how they are provided.
Each service is unique. It can never be exactly repeated as the time, location, circumstances, conditions, current configurations and/or assigned resources are different for the next delivery, even if the same service is requested by the consumer.
Products, Goods, Services: types and quality
The human factor is often the key success factor in service provision.
❺ Types of Services:
- Business Services: These are services used by businesses to conduct their operations.
Examples include consulting, advertising, and logistics.
- Personal Services: These are services provided to individuals (consumers).
Examples of Services:
- Healthcare: Medical consultations, surgeries, and nursing care.
- Education: Teaching, tutoring, and training.
- Hospitality: Hotel stays, restaurant dining, and travel services.
- Governmental: eg passport, housing, personal finance aid, roads.
❻ Types of Services:
Service quality can be measured through various dimensions such as:
- reliability, Mass generation and delivery of services must be mastered before expanding.
- responsiveness, Demand can vary by season, time of day, business cycle, etc.
- assurance, Consistency is necessary to create enduring relationships.
- empathy, and
- tangibles (the physical evidence of the service).
Both inputs and outputs to the processes involved providing services are highly variable, as are the relationships between these processes, making it difficult to maintain consistent service quality.
Many services involve variable human activity, rather than a precisely determined process.
Service-commodity goods continuum
The distinction between a good and a service remains disputed.
Classical economists contended that goods were objects of value over which ownership rights could be established and exchanged.
Ownership implied tangible possession of an object that had been acquired through purchase, barter or gift from the producer or previous owner and was legally identifiable as the property of the current owner.
😲
Adam Smith's famous book, The Wealth of Nations, published in 1776, distinguished between the outputs of what he termed "productive" and "unproductive" labor.
The former, he stated, produced goods that could be stored after production and subsequently exchanged for money or other items of value.
The latter, however useful or necessary, created services that perished at the time of production and therefore did not contribute to wealth.
Building on this theme, French economist Jean-Baptiste Say argued that production and consumption were inseparable in services, coining the term "immaterial products" to describe them.
🤔
In the modern day, Gustofsson & Johnson describe a continuum with pure service on one terminal point and pure commodity good on the other.
Most products fall between these two extremes.
For example, a restaurant provides a physical good (the food), but also provides services in the form of ambience, the setting and clearing of the table, etc.
⚖ W-1.2.3 Services orientation at information technology
Managing service gaps
❼
Consequently, customers evaluation of overall service quality is based on a combination of all five aspects outlined above.
Knowing the way customers evaluate service, it is important to understand, identify and measure the potential gaps that may exist in the service delivery process.
- knowledge gap This occurs when there is a disconnect between what a customer wants or expects in service quality and what the management team of the service provider thinks the customer wants or expects from the service delivery.
- standards gap This occurs when there is a difference between what the management team wants and the actual service delivery specification that management develops for employees to follow in delivering the service.
- delivery gap This gap can occur when there is a disconnect between the service standard and the actual service delivered to the customer.
- communications gap This happens when there is a difference in what the customer is told they can expect and what service is actually delivered.
- Expectation gap This gap can appear when there is a difference in what the customer expects from the service (prior to consumption or purchase) and what the customer perceives of the service after it has been provided.
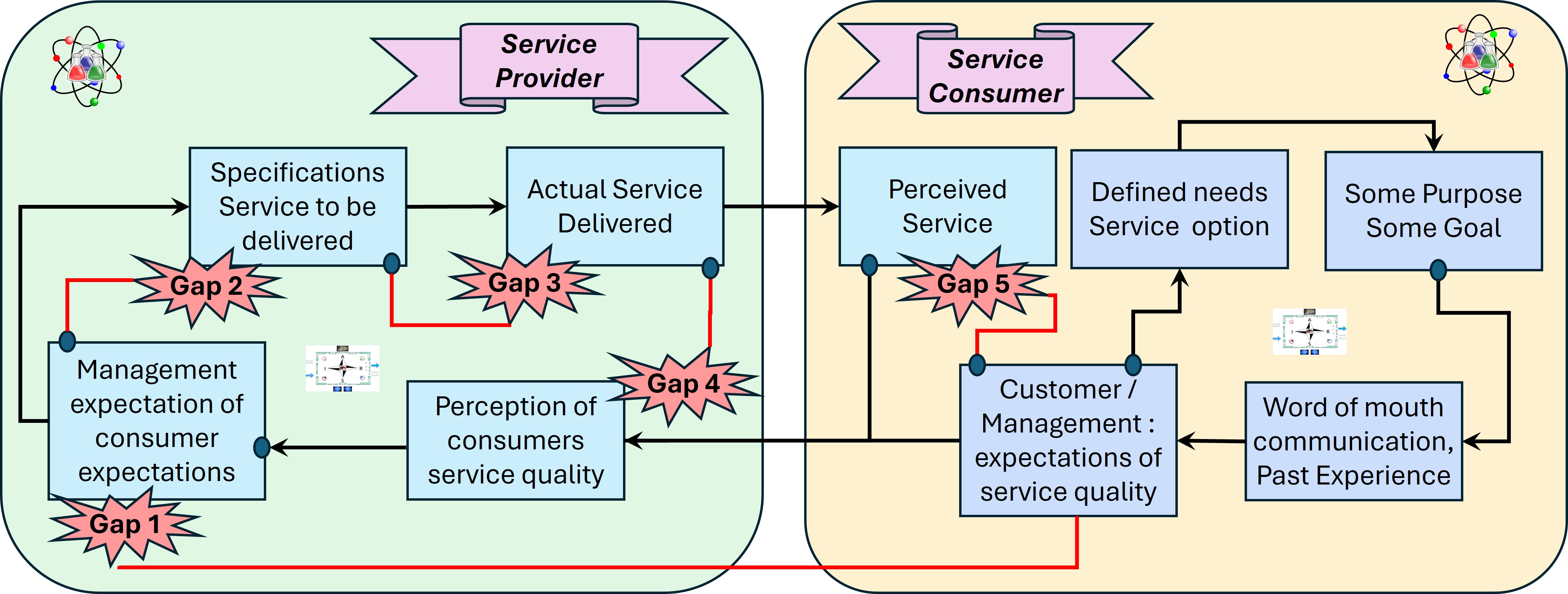
The soll in infomration service provision
❽ Changes in the way of working are needed at a lot of levels. Bottom-up from technology perspective starts at 6.
The columns are: Customer Focus, Processes & Tools, Continuous Learning & Improvements, Team structure, Value stream management, Culture.
👉🏾 The "soll" in a matrix (top-details, context-bottom):
| |  |  |
| | Customer | P&T | CLI | Teams | VSM | Culture |
| | ➡ What | ➡ How | ➡ Where | ➡ Who | ➡ When | ➡ Which |
| 6 5 ➡ | seek satisfaction | continuous improvement | quickly actions | organic autonomy | eliminate bottlenecks | diversity in thinking |
| 7 4 ➡ | visible deliveries | automate: no defects | evolving skills | knowledge sharing | balance: speed - quality | shared visions missions |
| 8 3 ⟳ | feedback loops | effective efficiency | small iterations | breaking hierarchy | informed decisions | safe, blame-free |
| 8 3 ⟲ |
| 9 2 ⬅ | value creation | collaboration | mistakes = learning | responsible autonomy | flow measurements | trust & openess |
| 0 1 ⬅ | Understand needs | lean: avoid 3m | adaption culture | diversity in teams | lean: flow optimisation | transparancy |
🎯💡 Promoting this way of working can be only succesfull by showing it by example.
⚖ W-1.2.4 Roles tasks levels in Information Services
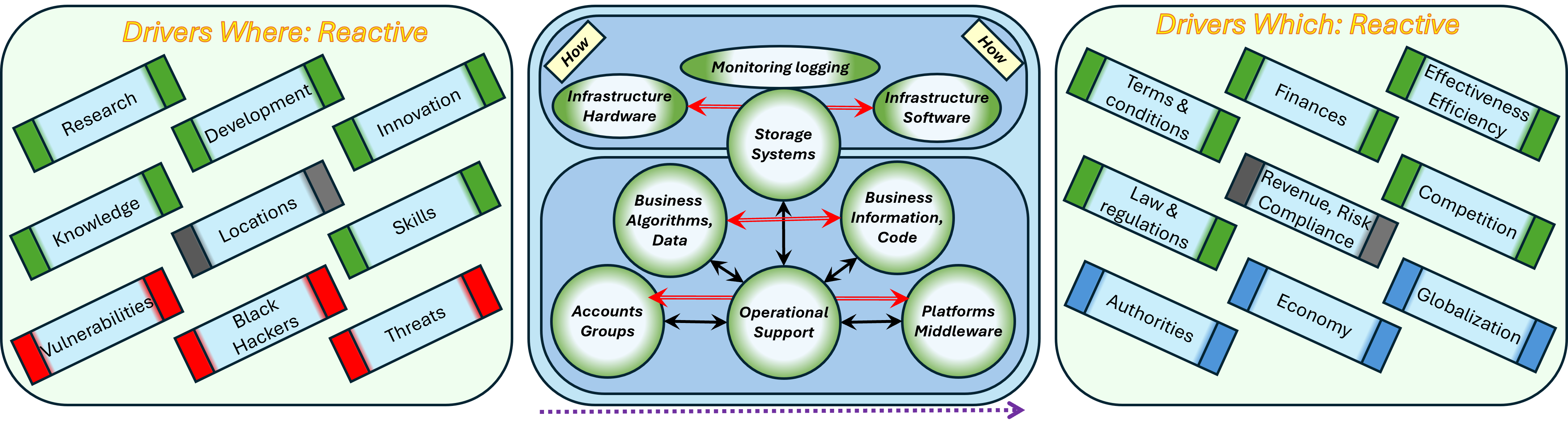
Building up the Information service bottom-up
❾ Every floor level is build on the next one by logical dependencies.
When a task has not found its destination on the intended floor, ad-hoc bypasses are used.
Execution machines floor 0/1, the how for the organisation
Execution processes floor 1/2, the how in value streams
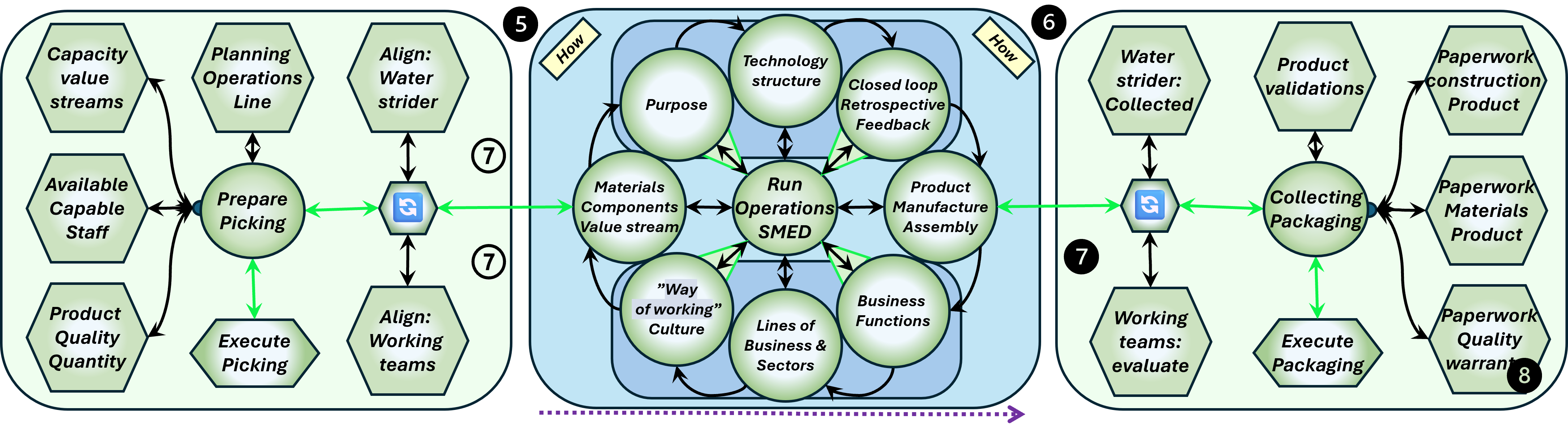
Change enacting floor 2/3, the what for value streams
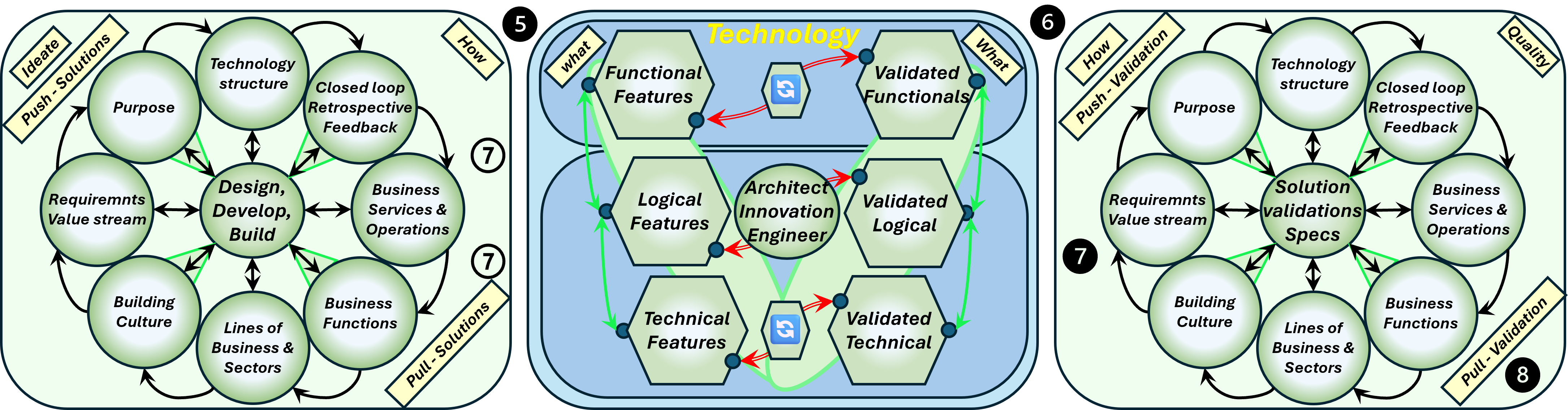
Change control floor 3/4, the what quality & quantity for the organisation
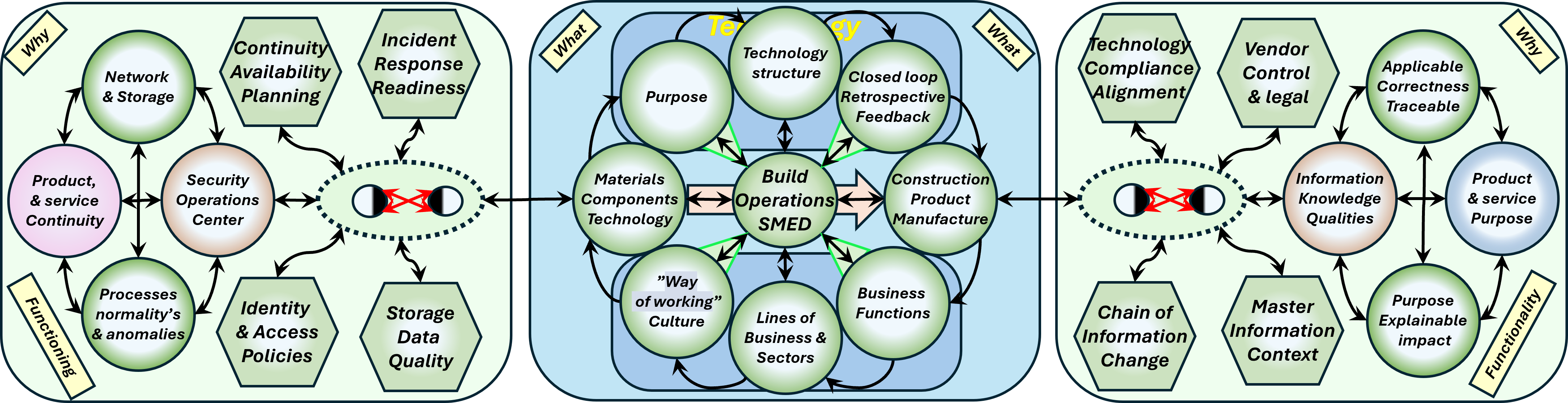 ❿
❿ In a mature situation all levels are in place and aligned with their antipodes.

W-1.3 Steering roles tasks
Managing the building any non trivial construction follows several stages.
These are:
- high level design & planning
- detailed design & realisation
- evaluation & corrections
Non trivial means it will be repeated for improved positions.
Managing the process, information is needed for understanding what is going on.
Without knowing the situation or direction there is no hope in achieving a destination by improvements.
⚖ W-1.3.1 Technical "how to" for understanding steering
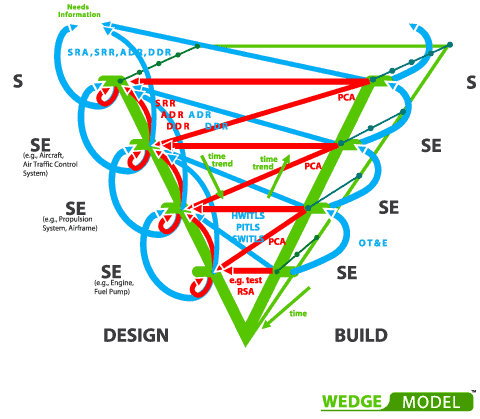
The V-model extended to a W-model
Organizing, planning the work in the primary value stream is a common activity.
Time is important for delivering results.
In engineering using the V-model is the standard, doing as much as possible in parallel.
There is no final design for every detail during construction.
The most important things at high level are however defined for achieving a defined goal.
To be extended to:
- Getting requirements, backlog items, ideas into the engineering line. (wedge model)
- Delivering validated results into specifications for the product: goods, services. (triple V)
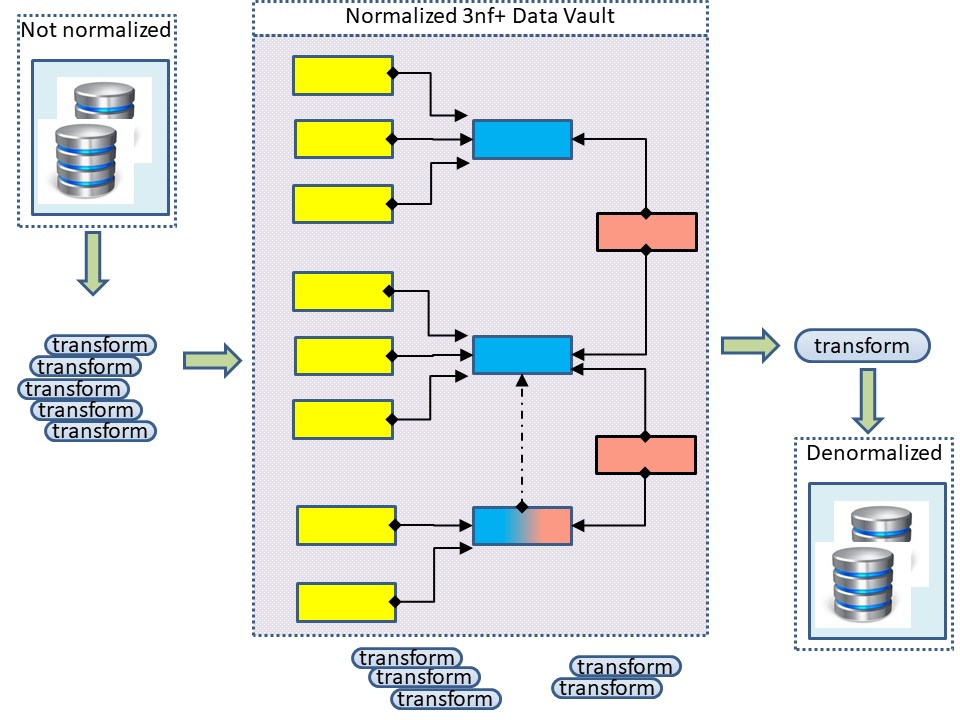
Transactional operations - Normalization
❶ In transactional systems it is important to avoid any duplication of an artefact, element, because it is too complex to keep duplications synchronized.
Details:
👓
The concept of
database normalization
is generally traced back to E.F. Codd, an IBM researcher who, in 1970, published a paper describing the relational database model.
Definion of the third Normal Form (3NF):
- Each column is unique in 1NF.
- All attributes within the entity should depend solely on the unique identifier of the entity in 2NF.
- No column entry should be dependent on any other entry (value) other than the key for the table , 3NF is achieved, considered as the database is normalized.
Reporting Business Intelligence (BI)- Denormalization
Denormalization is the process of reversing the transformations made during normalization for performance reasons.
It's a topic that stirs controversy among database experts;
Tthere are those who claim the cost is too high and never denormalize, and there are those that tout its benefits and routinely denormalize.
❷ Classic Business Intelligence are reshaping all operational data into new dedicated data models.
The reason for this is taht facts and dimension used in the operational process are not suited for reporting and analyses.
The concepts of a transactional operational data design with normalization are followed.
- The result is a lot of transformations for tables.
- What is delivered as olap or reports, is denormalised using summaries.

National language Support (NLS)
National Language Support (NLS) and localized versions are frequently confused.
- NLS ensures that systems can handle local language data.
- A localized version is a software product in which the entire user interface appears in a particular language.
NLS is about:
- string manipulation
- character classifications
- character comparison rules
- code character sets
- date and time formatting
- user interfaces
- message-text languages
- numeric and monetary formatting
- sort orders
❸ In the moment the NLS options are propagating into logical constructs the logic has become dependent on a NLS setting.
Many tools are suffering from this not wanted effects.
This also has impact on the realisation in the data processing.
👓 details
Examples:
- eclipse NLS guidelines. for modifying the tool in supporting NLS.
⚖ W-1.3.2 The what to start operational steering
Scheduling, planning operations.
Scheduling is the other part of running processes.
Instead of defining blocks of code in a program it is about defining blocks of programs for a process.
Processes are planed in time to run in time windows with dependencies.
❹ avoiding confusion by same word other context:
- For building a program "job" is used by developers.
- For building a process flow, having a start and end, "job" is used at operations.
This "job" (process flow) can consist of many "jobs" (programs).
Running process flows will cause a work load for the system (technical infrastrucuture)
- The developers, operations, examples of staff are doing their "job" (work).
Building a process flow
Building a process flow (job) is defining the order how to run code units (jobs).
- Defining the first and last progrm units.
Used for initialisation and a message of a successful finish.
- Dependencies when a next code unit may run, which ones to wait to get ready.
- Allowing for multiple code units to run when there are no dependencies:
- Allowing a single process flow being active at one moment or having multiple of the same process flow running at the same moment.
When parallel flows are allowed, unique application datasets are needed.
See figure, link
👓, details.
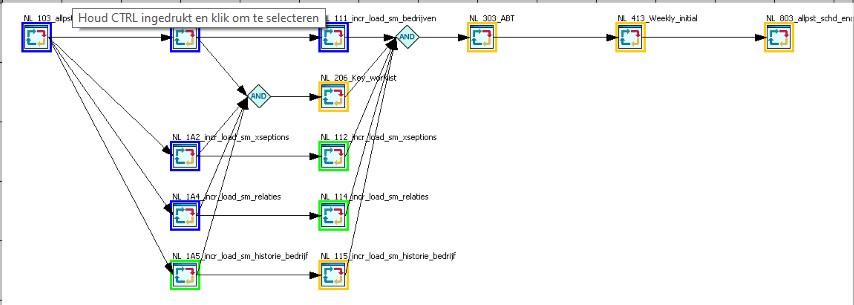
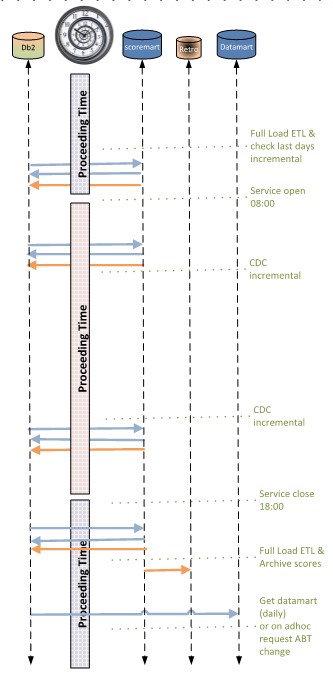
Operational control process flows I
Operational task: Monitoring the progress within a running process.
When automated there is only human interaction needed when there is signal of things going wrong.
- blue ready,
- green running,
- yellow waiting,
- red in error.
Andon ,
stop the line , and do not push the problem downstream.
❺ Human intervention ready for action (Andon).
Running planned proces flows
Having process flow defined the planning is:
- when they should run, able to start.
- when they should be ready.
- Dependencies between flows when running
- Dependencies between programs when running
- what impact there is on technical system resources.
- what impact there is on technical system resources.
In the example, see figure:
- early morning, out of office hours, a full load of several warehouses is run.
The full load in this case was faster than trying to catch all changes.
An additional advantage: missing changes in the source system will not have a big impact as the longest data synchronisation delay is one day.
- During office hours every 15 minutes update for changes. Achieve a near real time updated version.
Developing a system like this is more easy, understandable when the scheduling and program units are designed and build as a system.
See figure, link
👓, details
❻ What is processed are indicators of deliveries, results for information products.
⚖ W-1.3.3 Understanding the data flow, data lineage
data lineage following the cycle
Knowing what information from what source is processed into new information at a new location is lineage (derivation),
"data lineage" .
❼
Understanding changes in data requires understanding the data chain, the rules that have been applied to data as it moves along the data chain, and what effects the rules have had on the data.
Data lineage includes the concept of an origin for the data—its original source or provenance—and the movement and change of the data as it passes through systems and is adopted for different uses (the sequence of steps within the data chain through which data has passed).
Pushing the metaphor, we can imagine that any data that changes as it moves through the data chain includes some but not all characteristics of its previous states and that it will pick up other characteristics through its evolution.
Data lineage is important to data quality measurement because lineage influences expectations.
In a figure,
See right side.
Details 👓
Capacity Considerations, the enterprise data warehouse (EDW)
A standardised location in normal information processes using data is brings normal capacity questions.
Change data - Transformations
More in details the transport of data, flow goes:
- Landing to warehouse collecting point(s).
- Staging transported internally to service technically according agreements.
- Semantic prepatransported internally for best service according agreements.
- Databank to a customer from the warehouse provision point(s).
This breaks with the common acceptance of using a data ware house.
The data warehouse is not used for operational processes but only for doing analytics to inform decision makers.
In normal industrial approaches the ware house is used for operational processes.
Measuring what is going on, informing decision makers is a different topic, different information flow.
The enterprise warehouse 3.0:
- Covers the operation information flows by four stages
- Dedicated flows of measurements, supporting closed loops are a part of the offering.
- Modelling data, information with all very detailed relationships is not a function of a Datawarehouse.
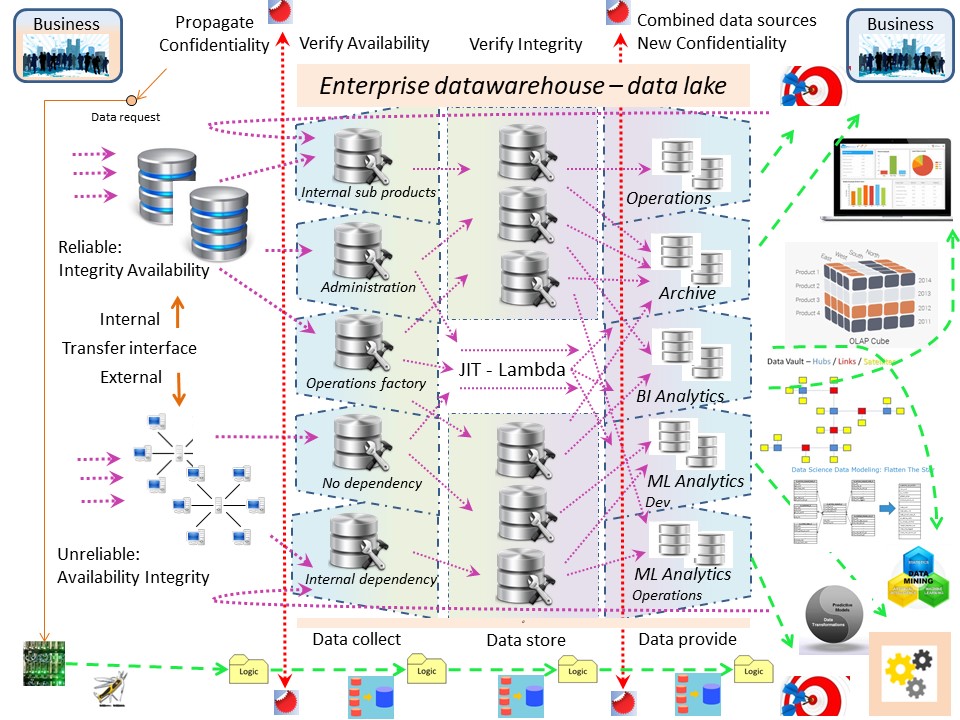
In a figure,
See right side.
Details 👓
In a figure,
See right side.
When the Collecting and sending area's of the EDW 3.0 are the ones that are most limiting the flow, the planning is best done for traffic by managing this service.
❽ Data lineage, data quality, information quality is "by design" of the information products.
⚖ W-1.3.4 Roles tasks levels supporting Information Services
Building up the Information lineage bottom-up
❾ Every floor level is build on the next one by logical dependencies.
When a task has not found its destination on the intended floor, ad-hoc bypasses are used.
Information quality, service product
A specification can be clearly and completely, consistently and concisely specified by means of standard attributes that conform to the MECE principle (Mutually Exclusive, Collectively Exhaustive).
The MECE principle is used in mapping process wherein the optimum arrangement of information is exhaustive and does not double count at any level of the hierarchy.
By reorganizing the information using MECE and the related storytelling framework, the point of the topic can be addressed quickly and supported with appropriate detail.
SCQA: Situation, Complication, Question, and Answer, a brief overview:
- Situation: Sets the context or background for the issue at hand.
- Complication: Introduces the problem or challenge that disrupts the situation.
- Question: This is the central question that arises from the complication.
- Answers, choices: Provides solutions and/or responses to the question.
From this a generic approach for pruducts, goods and/or services:
- Consumer benefits: Set of benefits that are triggerable, consumable and effectively utilizable for consumer.
These benefits must be described in terms that are meaningful to consumers.
- Specific functional parameters: Parameters that are essential and that describe the important dimension(s) of the escape, the output or the outcome.
- Delivery point: The physical location and/or logical interface where the benefits are rendered to the consumer.
At this delivery preparation can be assessed, delivery can be monitored and controlled.
- Consumer count: the number of consumers that are enabled to consume a product.
- Delivery readiness time: the moments when the product is available and all the specified elements are available at their delivery point
- Consumer support times: the moments when the support team ("service desk") is available.
The service desk is the Single Point of Contact (SPoC) for service inquiries.
At those times, the service desk can be reached by defined available communication methods.
- Consumer support language: the language(s) spoken by the service desk.
- Fulfilment target the provider's promise to deliver the product, expressed as the ratio of the count of successful product deliveries to the count of requests by a single consumer or consumer group over some time period.
- Impairment duration: the maximum allowable interval between the first occurrence of a product impairment and the full resumption and completion of the product delivery.
- Delivery duration the maximum allowable period for effectively rendering all product benefits to the consumer.
- Delivery unit the scope/number of action(s) that constitute a delivered product.
Serves as the reference object for the product delivering price, for all product costs as well as for charging and billing.
- Delivery price the amount of money the customer pays to receive a product.
Typically, the price includes a product access price that qualifies the consumer to request the product and a price for each delivery.
❿ In a mature situation all levels of support are in place and aligned with their antipodes.

W-1.4 Culture building people
Managing the working force at any non trivial construction is moving to the edges.
The cultural changes are:
- Respect for people, learning investments at staff
- Accepting uncertainties and imperfections
- Trusting the working force while getting also well informed
Non trivial means it will be repeated for improved positions.
Managing the working force at processes, information is needed for understanding what is going on.
Without knowing the situation or direction there is no hope in achieving a destination by improvements.
⚖ W-1.4.1 Project management, the change challenges
Culture by frameworks, hypes
There is for a many years a fight going on in the information technology world how work should get managed.
Instead of learning from other STEM, Science Technology Engineering Mathematics, what they have learned and what is is possbile, reinventing the wheel is common.
- The waterfall vas Agile fights, without understanding the why.
- Forcing uSing tools, tooligans, without understanding the why.
No such thing as Waterfall (A.Dooley 2024)
The Agile movement has greatly enriched the project management landscape.
Unfortunately the ‘cult of Agile’ is doing more harm than good with its narrow evangelical views.
...
It was perhaps naïve of me to not anticipate that there are many, many different views of what the term 'Waterfall' actually means.
That shouldn't have been a surprise since there is a similar lack of common understanding of what 'Agile' actually is, so if Waterfall is the antonym of something that isn't well defined, why would I expect the term Waterfall itself to be well defined? ...
All of this has reinforced my view that in the world of project and programme management, we should stop using the terms Agile and Waterfall (and, as a consequence, Hybrid) and just talk about agility.
All projects demonstrate some degree of agility at some point in their life cycle and agility can take many forms.

The confusion of:
- managing building a product ⇆ organizing resources
- the building of the product ⇆ engineering
Development life cycles focus on the delivery phase of a project or programme and often arise from particular domains such as construction, engineering or IT.
They should not be confused with governance life cycles or specialist life cycles. ...
As uncertainty about the detail of objectives increases, development life cycles need to be more iterative so they can adapt as more information becomes available.
Future for project, programme management
Vision is linking
Innovation and value (L.Bourne)
The key is an effective and viable strategic planning process that is capable of developing a realistic strategy that encompasses both support and enhancements for business as usual, and innovation.
Strategic planning is a complex and skilled process outside of the scope of this post, for now we will assume the organisation is capable of effective strategic planning. ...
There is a close link between the portfolio management processes and strategic planning, what's actually happening in the organisation's existing projects and programs is one of the baselines needed to maintain an effective strategic plan (others include the current operational baseline and changes in the external environment).
In the other direction, the current/updated strategy informs the portfolio decision making processes.
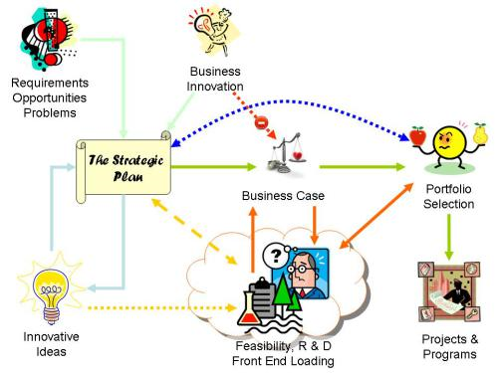
In a figure:
See right side.
The strategic plan is the embodiment of the organisation’s intentions for the future and the role of portfolio management is to achieve the most valuable return against this plan within the organisation’s capacity and capability constraints. ...
👉🏾 The long term viability of any organisation depends on its ability to innovate.
⚖ W-1.4.2 Project into Programme into Portfolio (3P)
Planning, a life cycle for a product, service
life-cycle
Project, programme and portfolio management (P3M) is the application of methods, procedures, techniques and competence to achieve a set of defined objectives.
The goals of P3 management are to:
- deliver the required objectives to stakeholders in a planned and controlled manner;
- govern and manage the processes that deliver the objectives effectively and efficiently.
Investment in effective P3 management will provide benefits to both the host organisation and the people involved in delivering the work. It will:
- increase the likelihood of achieving the desired results
- ensure effective and efficient use of resources
- satisfy the needs of different stakeholders
A consistent approach to P3 management, coupled with the use of competent resources is central to developing organisational capability maturity.
A mature organisation will successfully deliver objectives on a regular and predictable basis.
A P3 life cycle illustrates the distinct phases that take an initial idea, capture stakeholder requirements, develop a set of objectives and then deliver those objectives.
The goals of life cycle management are to:
- identify the phases of a life cycle that match the context of the work
- structure governance activities in accordance with the life cycle phases
Projects and programmes are the primary mechanisms for delivering objectives while portfolios are more focused on co-ordinating and governing delivery of multiple projects and/or programmes.
As a result the project and programme life cycles have many similarities and follow the same basic approach.
The simplest life cycle is a project life cycle that is only concerned with developing an output.
Programme
A typical programme life cycle is shown.
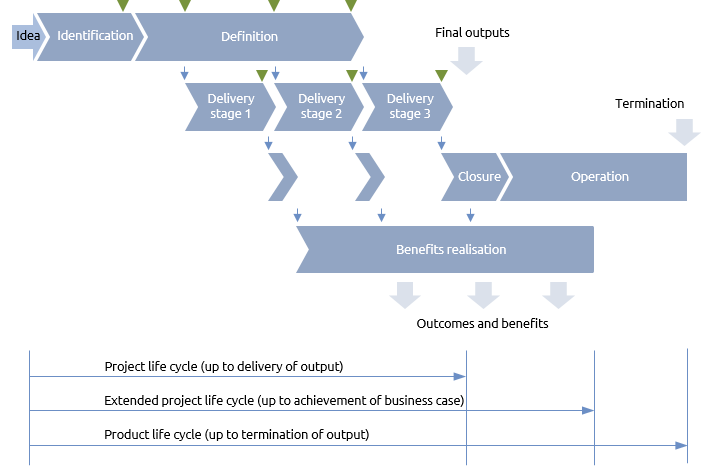
Steps:
- idea,
- identification,
- definition,
- delivery (1-n),
- closure,
- output.
Benefits realisation start at the first delivery.
See figure.
It all starts with someone having an idea that is worth investigation.
This triggers high level requirements management and assessment of the viability of the idea to create a business case.
At the end of the phase there is a gate where a decision made whether or not to proceed to more detailed (and therefore costly) definition of the work. ...
The full product life cycle also includes:
- Operation – continuing support and maintenance
- Termination – closure at the end of the product’s useful life
In a parallel project life cycle, most of the phases overlap and there may be multiple handovers of interim deliverables prior to closure of the project.
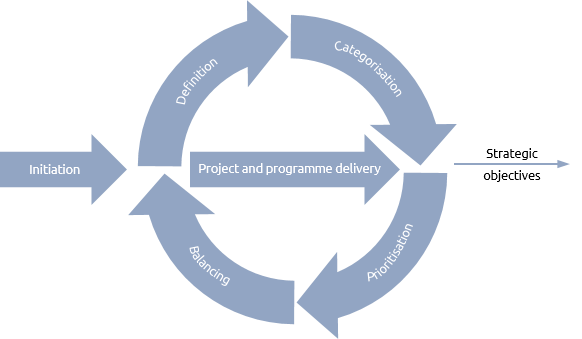
Portfolio
Unlike projects and programmes, portfolios are less likely to have a defined start and finish.
Portfolio management is a more continual cycle coordinating projects and programmes.
It may, however, be constrained by a strategic planning cycle that reviews strategy over a defined period.
If an organisation has, for example, a three-year strategic planning cycle, then the portfolio cycle will have compatible time constraints.
👉🏾 The portfolio management team may be responsible not only for co-ordinating the projects and programmes to deliver strategic objectives, but also for improving the maturity of project, programme and portfolio management.
⚖ W-1.4.3 Managing flow in activities, portfolios
TOC Theory of constraints
BlueDolphins Love the FLOW
To make the long story (s. above) short, "the current accounting is so complex because it tries to optimize everything!
The main assumption of accounting is:
- every team or department has to be efficient, means loaded at 100%.
- if you load every team to 100%, then the overall output is also optimized!
But that is impossible because every system has exactly one constraint.
Without a constraint, it would grow with infinite speed, explode or exhaust all resources. And will die immediately. ...
This algorithm based on the Theory of Constraints (TOC) and Throughput Accounting (TA) is easier because every step is deterministic and easy to understand for everyone.
TOC Dolphins book: Management 4.0, Handbook for Agile Practices (3.0 )
The buzzwords “Agility, Agile or Agile Management” are often interpreted as miracle-workers.
But the number of different meanings attributed to these terms is immense: There are thousands of experts and tens of thousands of books and articles on what agile work actually is.
Subject of agility: everyone is an expert, everyone knows how to do it best. ...
This book was conceived as a manual or "handbook" and ended up as a "brain book".
It is full of concepts and principles, some rough and coarse, some fine polished.
But all help to understand and put into practice the agile movement, and to ride this great wave without sinking!
Highlights:
-
It is often quite astonishing to see how seldom, operative problems seem to attract management attention in today’s large corporations, unless they impact on the tactical strategies of the manager involved.
A more integrated approach is needed, to encourage management to focus on the total throughput of the company, rather than on the individual interests of single departments.
-
“Agile Manifesto” The concept is based on the delegation of responsibilities, self-organization and incremental development steps, which allow a flexible response to customer needs.
These principles can also be transferred to general management tasks.
It would be a fatal misunderstanding though, to see such an approach as an IT project.
-
To achieve an effective transformation the company needs to bring about nothing less than a complete culture change.
Management has to relinquish its monopoly on information ownership, which may be perceived as loss of power.
-
Of course management still retains responsibility for steering the company as a whole in the right direction, yet its role has changed.
As coaches to cross-functional teams, they need to cooperate closely with management colleagues.
👉🏾 It is necessary for management to collaborate, in order to eliminate bottlenecks for the teams, by focusing on the total throughput.
There is no longer room for individual power play between departments, as all teams have cross-functional tasks.
Managing a living viable system
Current enterprises are, to a great extent, pushed by a permanent demand for change and adaption.
One of their main requirements therefore is their ability to react accurately and precisely to dynamic and quickly changing market demands.
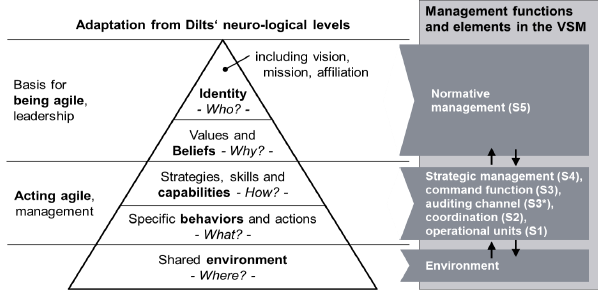
Cybernetic combined with a hierarchy 6w1h.
Management cybernetics provides a structural framework of managerial functions and the required interactions that will enable the long-term success of businesses. ...
changing the normative setting in an organization is crucial for reaching the desired synergy effects, i.e. initiating a process where “the whole is greater than the sum of its parts” (Aristotle).
The main driver for a collective interconnection between people, is
- firstly the development of a collective vision or a shared corporate goal (“big picture”)
- secondly a corporate culture based on confidence and mindful appreciation between the representatives of management functions and operational units.
... We cannot stress strongly enough how important it is from our point of view that any increase in S1’s self-organizing capabilities should always be accompanied by an agile reshaping of the higher management functions S2 through S5 in the sense described above.
⚖ W-1.4.4 CPO, CPE, Managing living viable systems
Lean Product and Process Development (LPPD)
LPPD Guiding Principles (Jim Morgan, Lara Harrington, Steve Shoemaker)
CPO Chief product officer, the goal focus on the product, good or service.
The LPPD Guiding Principles provide a holistic framework for effective and efficient product and service
development, enabling you to achieve your development goals.
- Putting People First: Organizing your development system and using lean practices to support people to
reach their full potential and perform their best sets up your organization to develop great products and
services your customers will love.
- Understanding before Executing: Taking the time to understand your customers and their context while
exploring and experimenting to develop knowledge helps you discover better solutions that meet your
customers’ needs.
- Developing Products Is a Team Sport: Leveraging a deliberate process and supporting practices to engage
team members across the enterprise from initial ideas to delivery ensures that you maximize value creation.
- Synchronizing Workflows: Organizing and managing the work concurrently to maximize the utility of
incomplete yet stable data enables you to achieve flow across the enterprise and reduce time to market.
- Building in Learning and Knowledge reuse: Creating a development system that encourages rapid learning,
reuses existing knowledge, and captures new knowledge to make it easier to use in the future helps you
build a long-term competitive advantage.
- Designing the Value Stream: Making trade-offs and decisions throughout the development cycle
through a lens of what best supports the success of the future delivery value stream will improve its
operational performance.
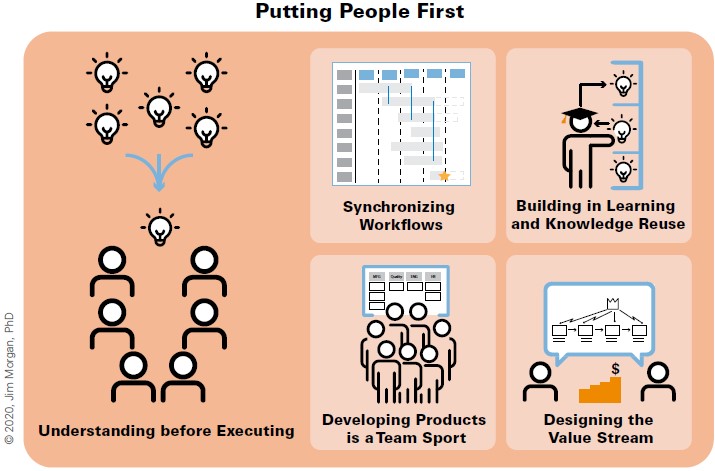
In a figure:
See right side.
Scaling without sacrificing innovation
👉🏾
Developing adaptiveness in a changing world (Sandrine Olivencia)
Chief product Engineers take on the critical role of balancing customer value technology and also finance to craft their products.
Actually a chief product engineer is not tied to a specific role like in agile.
Product manager or Tech lead is more of a responsibility or and a mindset.
CPE: Chief product Engineers can emerge from any part of the organization
3 Practices to scale artisanship (19m06):
- Emotion-centric design
- Performance-based product
- Mentor Chief Product Engineers
Chief product engineer (22m42) :
- Visceral passion for the customer
- Strong grasp of the product
- Committed to optimizing costs
The goal of this mentorship system is for experienced leaders to pass on their knowledge their vision and their artisanship to the next generation.
The Cornerstone of the system is the chief product role the chief product engineer role.
Product-led approach (262m42) :
- Mentor Chief Product Engineers
- Design products that sell themselves
- Perpetuate an artisan mindset

W-1.5 Sound underpinned theory, foundation
Knowing the position situation in by observing several types of associated information .
These are:
- Art of the role by observed input and results
- Art of the role by follow up interactions
- Kind of task in the process by role
Non trivial means it will be repeated for improved positions.
Command & control needs information for what understanding what is going on.
Without knowing the situation or direction there is no hope in achieving a destination by improvements.
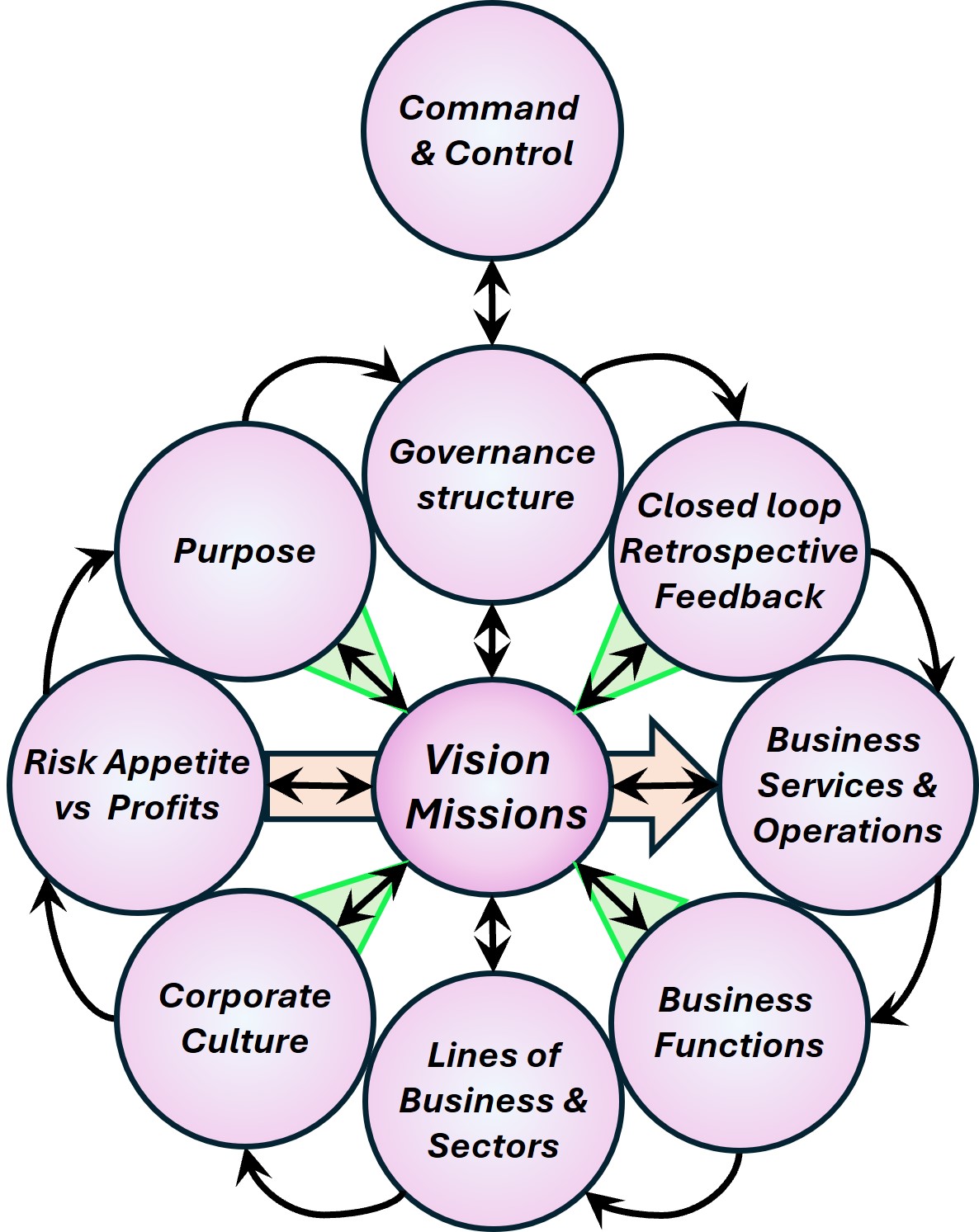
⚖ W-1.5.1 Chosen colours and shapes for the floor plans
SIMF colours for area's
An organisation in two dimensional blueprints for a three (and more) dimensions needs elaboration.
Presenting idea's by only figures is too difficult to understand without an explanatory reference.
| Explanation for the areas | Image |
Steer: An orange colour are organisational command & control for:
- high abstracted level to the operational floor activities
- for functionality, the change and functioning getting the value.
|
 |
Serve: A green colour are technology aspects for:
- high abstracted level to the operational floor activities
- for functionality, the change and functioning getting the value.
|
 |
Shape: A blue colour are mediation aspects for:
- high abstracted level to the operational floor activities
- for functionality: medium & long term closed loop information
|
 |
Synapse: A gray colour are the logical communication aspects for:
- The short term, quick communication, quick reaction at the same floor level.
- The short term, quick communication, quick reaction over floor levels.
This area is the equivalent of command & control of a viable system.
The viable system theory is mentions a fifth level. Questions for that one:
Who are our customers? What problems do we solve for them? What are they really willing to pay money for?
This is crucial because answering those provides the primary control criterion that anchors accountability.
|
 |
SIMF structure in shapes
| Explanation for the areas | Image structures |
Steer: Structures:
- Circles
➡ Interactions
related to:
- Organisation
magenta
- Technology
green
- Consumer focus
brown
- Supplier focus
indigo
- A circle of circles, controlled
- Hexagons
➡ defined actions
- collection
delegated actions, controlled
- duality
➡ Materialised information
vs processing information
|
|
Serve: Structures:
- Circles
➡ Interactions
related to:
- Organisation
magenta
- Technology
green
- Consumer focus
brown
- Supplier focus
indigo
- A tree of circles, controlled
- A V-shape control
➡ adaptive change
- Hexagons
➡ defined actions
- Hexagon flow
➡ fast closed loops
|
|
Shape: Structures:
- Hexagons
➡ defined actions
- Hexagon flow
➡ fast closed loops
- Circles
➡ Interactions
related to:
- Organisation
magenta
- Technology
green
- Consumer focus
brown
- Supplier focus
indigo
- A collection of circles, controlled
|

|
Synapse: Structures:
- Circles
➡ Interactions
Same floor defined orientation:
- Organization
magenta
- Technology
green
- Consumer focus
brown
- Supplier focus
indigo
- Hexagons
➡ defined actions
- Rectangles
➡external influence
- Antennas
➡ receiving signals
|
|
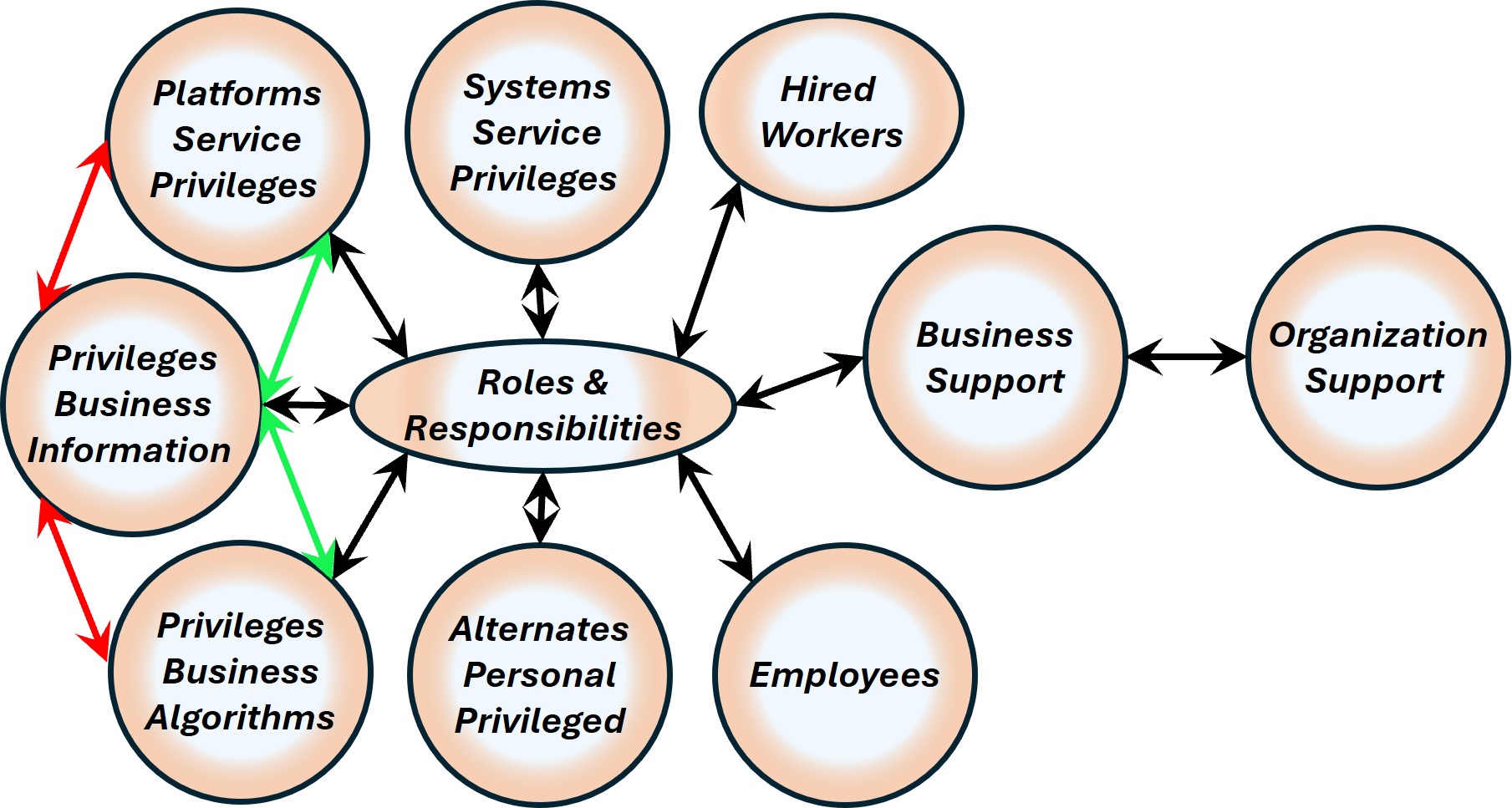
⚖ W-1.5.2 The viable system, conscious decisions
SIMF the organisation for realisations, outside view
👁 Industrial age: the manager knows everything, workers are resources similar to machines.
👁 Information age, required change: a shift to distributed knowledge, power to the edges.
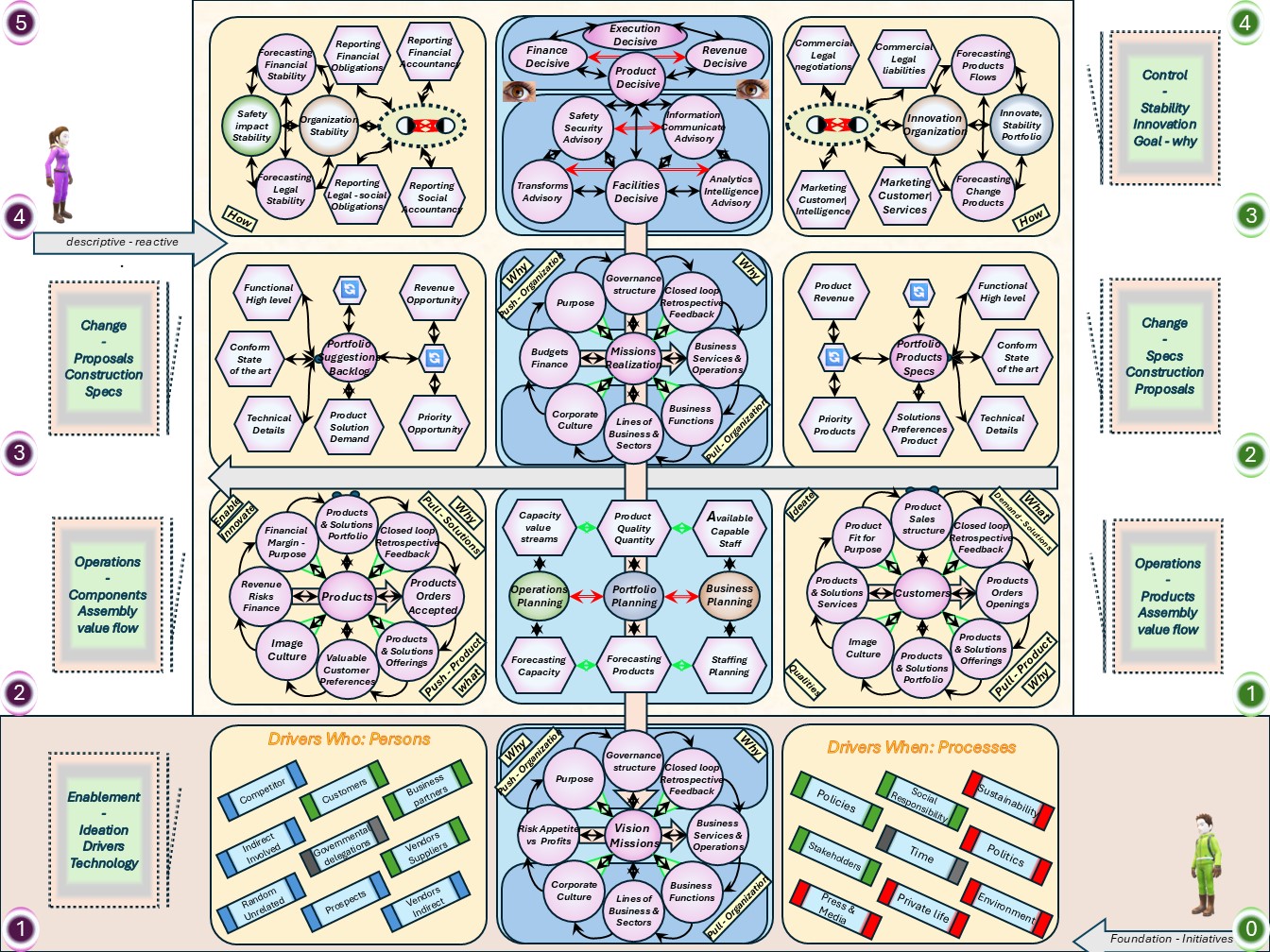
Understanding the business, organisation in their four levels (bottom-up).
- VSM System-5 Mngmt Operational VSM-1i: Visions, Missions elementary, 0-1 floor.
Assuring they are shared values for all and everything. Defining Visions could be by the same persons (boardroom) but that is not necessary.
- VSM System-4 Mngmt Operational VSM-1r: Long term resource planning 1-2 floor.
This a core activity for organisational processes.
- VSM System-3 Mngmt Operational VSM-1r: Mission realisation, 2-3 floor.
Portfoliomanagement knowing and planning the products over the relevant time.
- VSM System-1 Mngmt Operational VSM-3 management. from 3-4. The important secundary functions of holistic strategy tactics finance marketing etc.
- Above this is VSM-4, VSM-5 and the scoped environment, VSM-6
The complete area of information processing for the organisation in a figure:
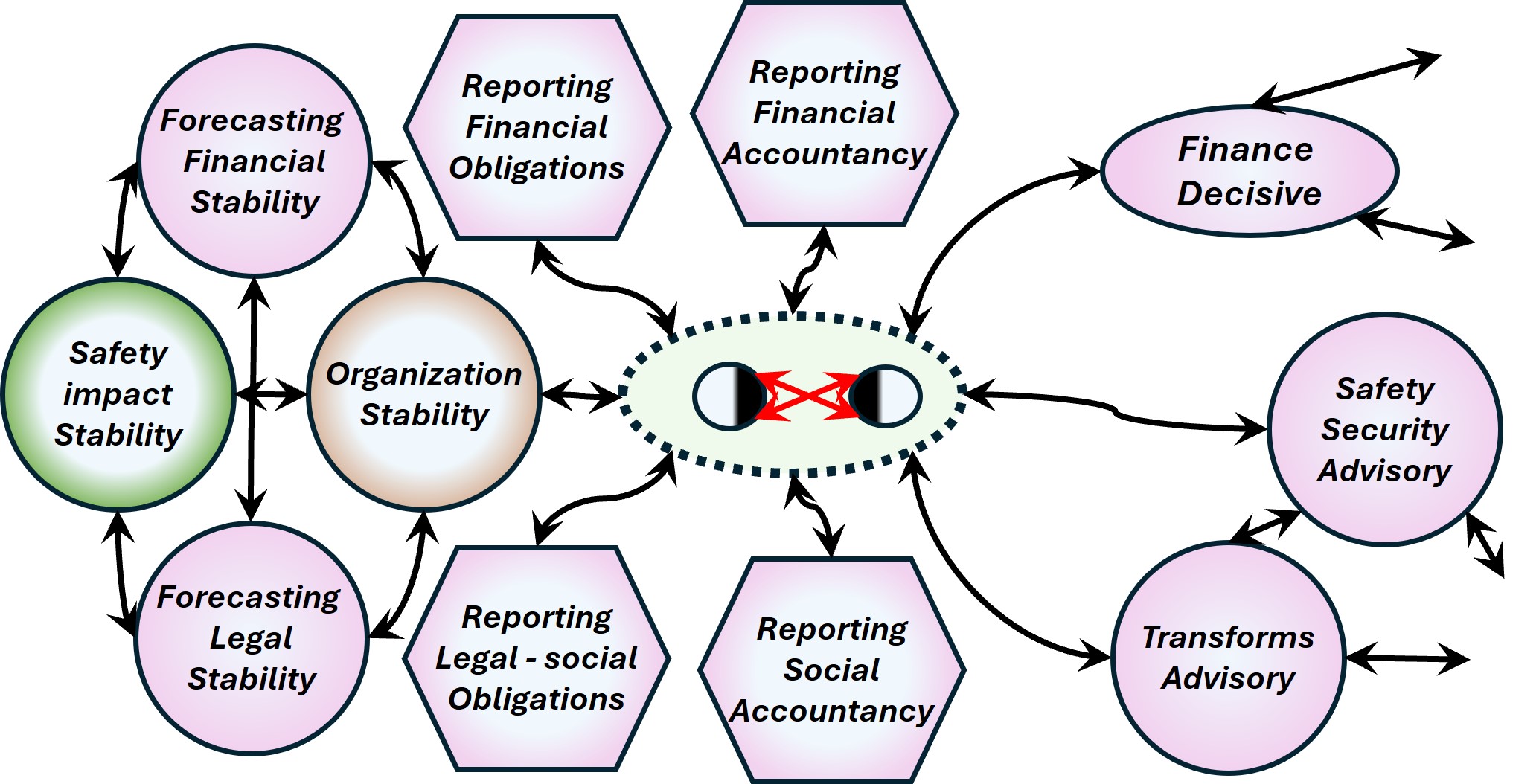
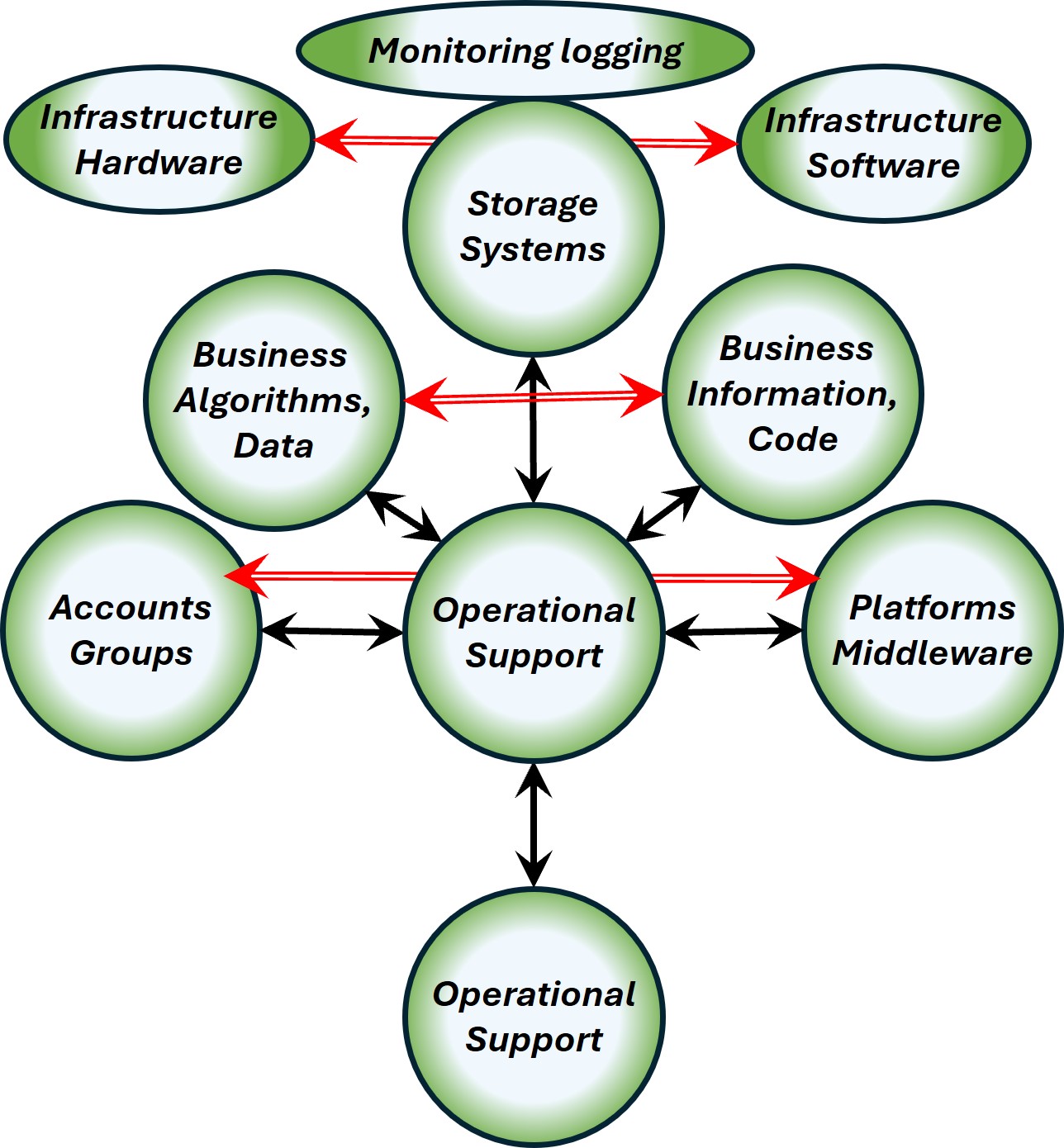
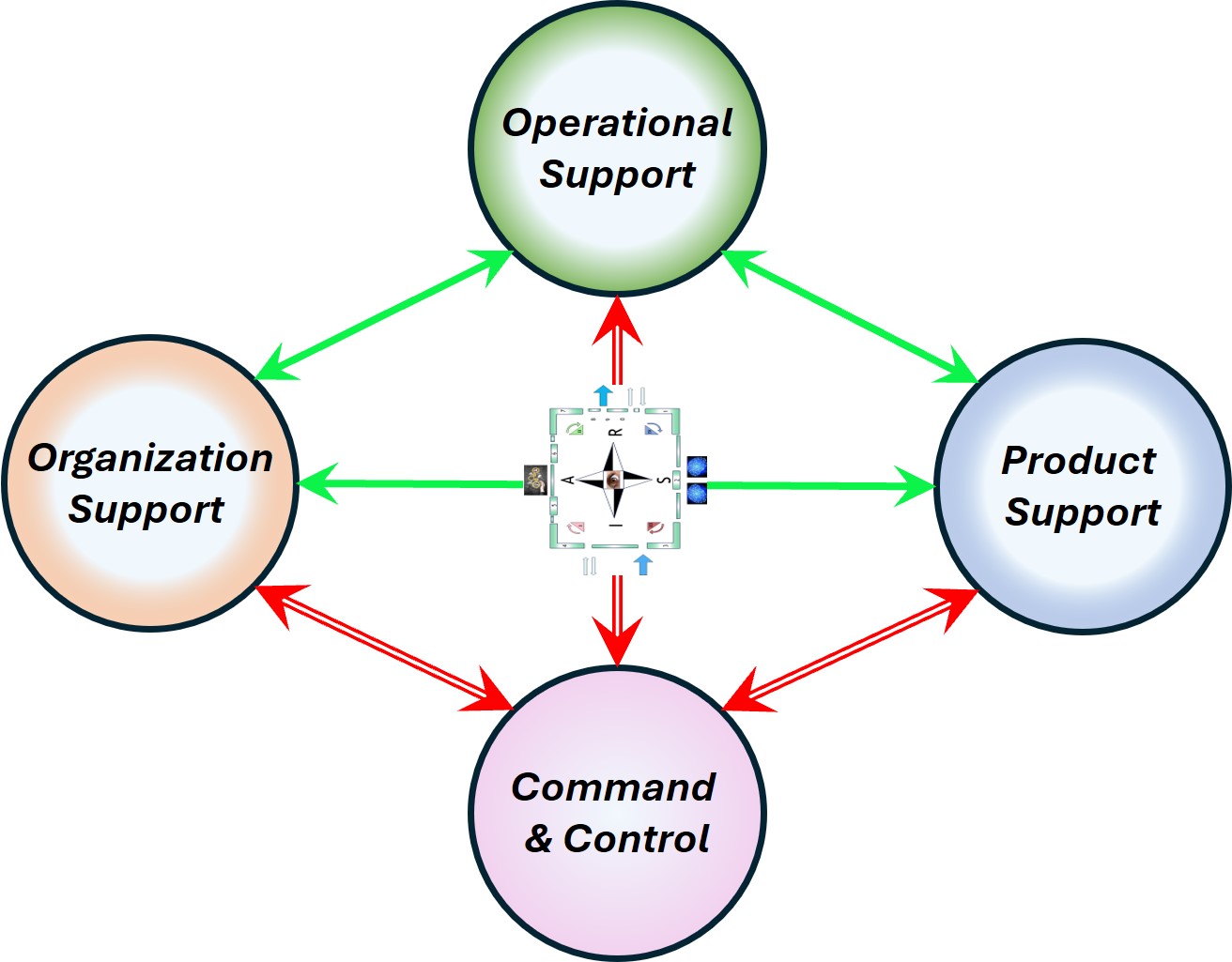
⚖ W-1.5.3 The viable system, autonomic technology
SIMF the processing for realisations, outside view
👁 Industrial age: the manager knows everything, workers are resources similar to machines.
👁 Information age, required change: a shift to distributed knowledge, power to the edges.
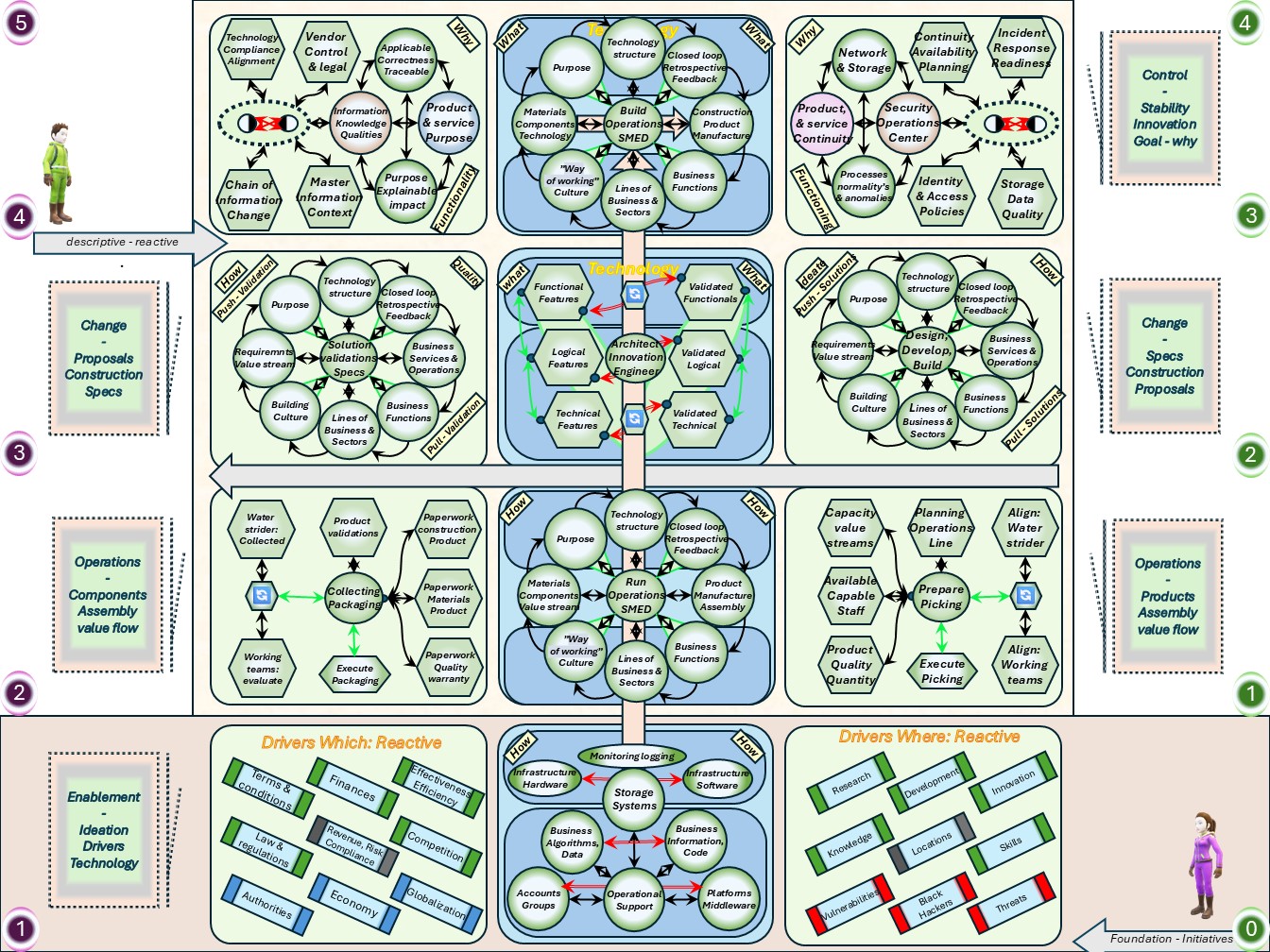
Understanding the technology service in their four levels (bottom-up).
- VSM System-1 Tech Operational VSM-1i the elementary 0-1 floor .
What is needed to react on immediate, very short term, is going by the synapse areas.
- VSM System-3 Tech Operational VSM-1r at the 1-2 floor. The centre where the organisationals value is created conform purpose.
The outside perspective changes: direction into right to left, rotation into clockwise.
- VSM System-4 Tech Operational VSM-1d Changes by missions: 2-3 floor level.
Applying the portfolio planning for purposes, goals with products.
- The change is triggered by feeds coming from the invisible backlog, suggestions.
- The result is going into the invisible adjusted portfolio.
- VSM System-5 Tech Operational VSM-3 mangement 3-4 floor, autonomic functions and algedonic channels.
A holistic information quality and holistic information safety is organisational dependent.
- Above this is VSM-4, VSM-5 and the scoped environment, VSM-6
The complete area of information processing for technology in a figure:
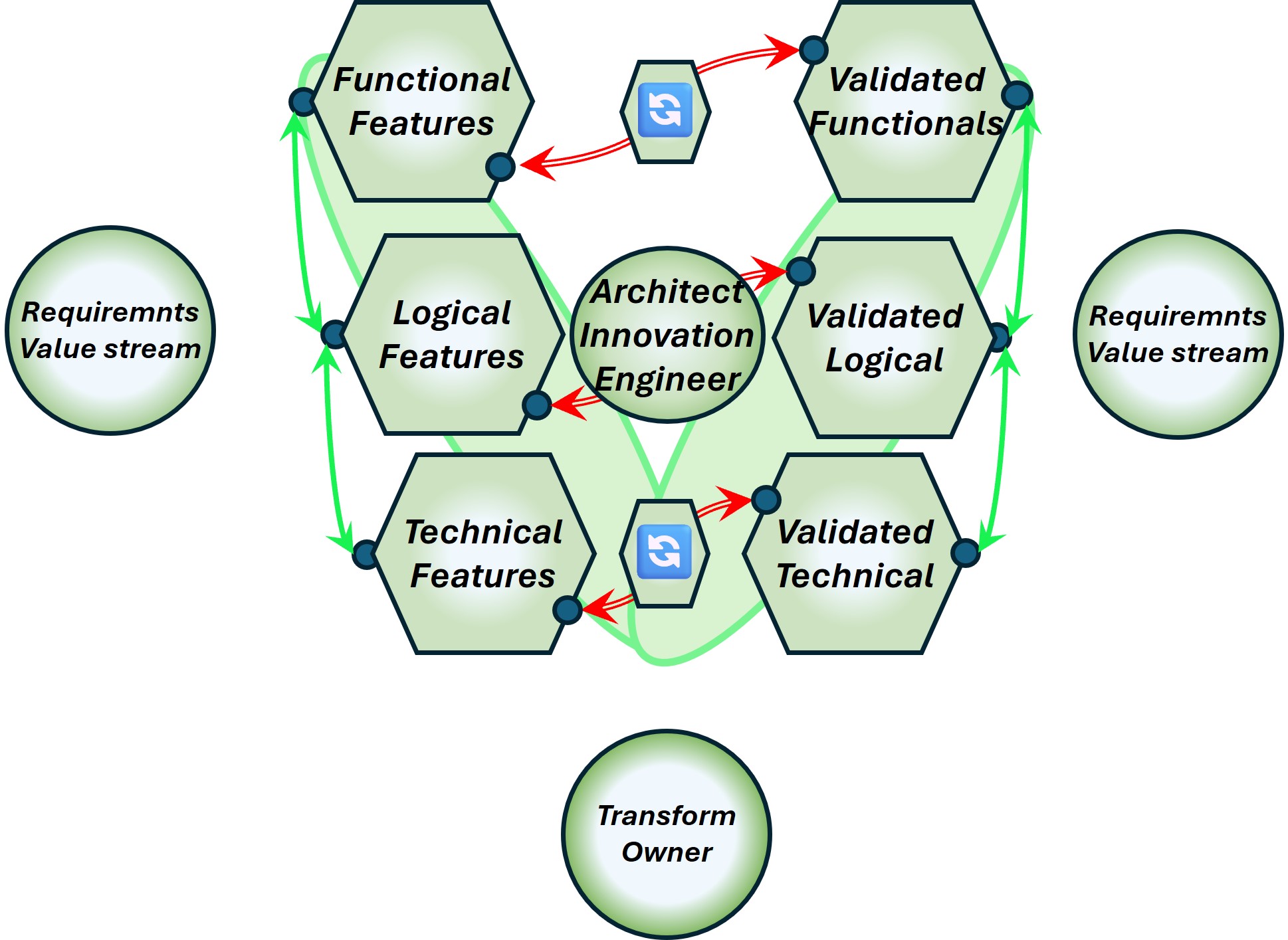
⚖ W-1.5.4 Mediation: Technical autonomy vs organisational control
SIMF Support in improving the product, service
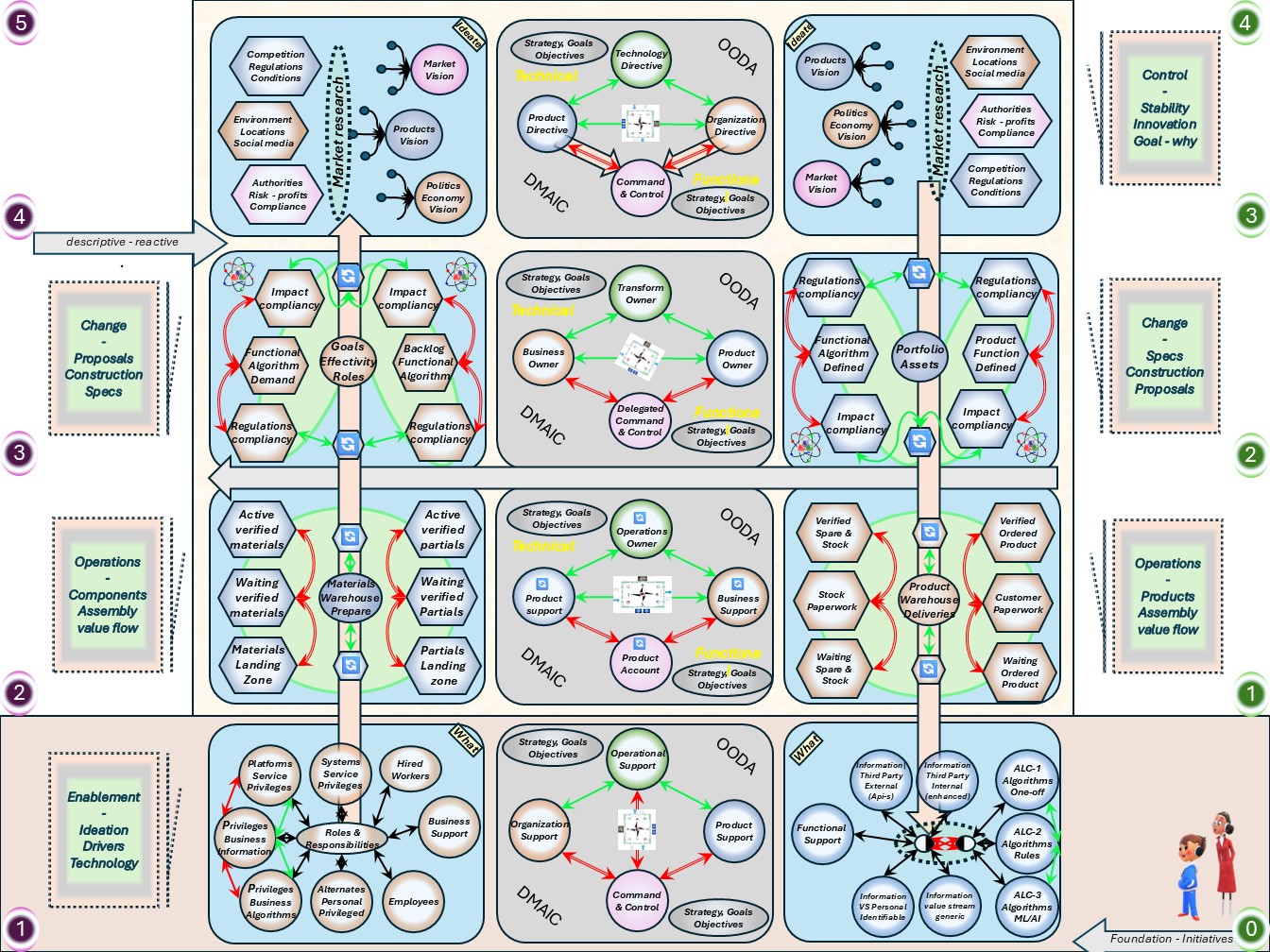
The dichotomy Technical autonomy vs organisational control is not a common historical topic.
Diplomacy is not associated with wealth, honour and glory.
MEDIATION IN ARMED CONFLICT
The practice of mediation involves third-party intervention to facilitate conflict resolution between parties.
Mediators act as neutral facilitators, assisting in communication, negotiation, and finding common ground to reach a peaceful resolution.
It is a diplomatic tool used to de-escalate tensions, prevent conflicts, and promote cooperation.
Seeing the two different side that are a lot of frictions to manage:
- The situation of the different sides are a consequence of growth.
- With a lot of variety to confusion and ambiguity also grows.
Some peculiar interesting attention points:
- Operational VSM-1i 0-1 floor: mix system-5 orgnisation - system-1 technology.
Mediation:
- Conflict: Avoiding the easy choice in technology by the organisation.
- Goal: Promote product improvement, promote culture improvement.
- Operational VSM-1r flow: 1-2 floor. Both sides are missing system-3, synergy.
Mediation:
- Align: Choices for what is going into the process flow - Organisation.
- Align: Choices for what has been processed in the flow - Technology.
- Operational VSM-1d change : 2-3 floor. Both sides are missing system-3, synergy.
Mediation:
- Align wishes with expectations time/cost for activities - Organisation.
- Align the design build verify activities in qualities - Technology.
- Mangement VSM-3 : 3-4 floor. Mediation Technology Autonomic functions and the important secundary functions in the organisation.
The complete area of changing products, goods, services at information processing in a figure:

W-1.6 Maturity 0: Strategy impact understood
From the three PPT, People, Process, Technology interrelated areas in scopes.
- ❌ P - processes & information
- ❌ P - People Organization optimization
- ❌ T - Tools, Infrastructure
Only having the focus on others by Command and Control is not complete understanding of all laysers, not what Comand & Control should be.
Each layer has his own dedicated characteristics.
⚖ W-1.6.1 Determining the position, the situation
Don't waste your precious time on creating something that is not serving the greater good:
- People: find a way to empower employees to innovate and solve problems.
- processes: Start fostering a culture of long-term thinking, not short-term fixes and don't do the same strategy with same expectations year after year.
- Command & Control: Lead by example and start making things transparent.
Start moving beyond the “toolbox mentality” or "my Lean-thinking" and unlock real potential.
⚖ W-1.6.2 Individual logical irrational together
Paradoxes in lean, agile
Thinking about Lean Thinking Part IV Paradox Mindset
At 12m40 there is a nice list of paradoces in defining lean (see 12m40)
A complete list:
Lean Global 2024
Here's a terrific collection of paradoxes that are inherent in Lean, compiled by Rachel Reuter and Eric O. Olsen.
Rachel presented it, with John Shook, at last week's Lean Global Connection event.
Paradox, or apparent contradictions, can be in the challenge statement of the Improvement Kata model, or pop up just about anywhere along the way (Figure 2 below).
Practicing Toyota Kata teaches you to work toward challenges with a scientific mindset and approach, making you more accustomed to the discomfort that uncertainties and paradoxes bring.
It enhances your ability to create 'both/and' solutions rather than limiting yourself to 'either/or' options.
Scientific thinking and what Rachel and John refer to as 'paradox mindset' are closely related.
- Customers-focused yet employee empowering
Lean is driven by delivering value to the customer. Employees focus which ultimately benefits the customer.
Yet empowering and engaging employees to reach their full potential is the focus.
- Structured yet flexible
Lean views structure, including standardisation and stability as key enablers for flexibility, adaptability creativity and innovation.
The framework provides a foundation for continuous improvement.
- Bottom-up, yet top down
Lean requires leadership to provide clear direction and create an environment where all workers drive innovation and improvements.
Both leadership and individual contribution are essential.
- People-centric, respectful yet challenging
Lean shows respect for people by challenging them to learn, grow, and never settle for the status quo.
Respect includes providing physical professional and emotional safety to enable development.
The level of challenge is tailored to the individual's role and abelites, to stretch them appropriately.
- Stop, yet flow
Lean requires stopping to immediately address problems, yet this enables unsurpassed efficiency, productivity and flow.
You cannot have flow without quality vice versa.
- Reflection-seeking yet failure-tolerant
lean pursues perfection and defined by providing on demand detect free one by-one , waste free, safe products and services.
Yet it recognizes the importance of surfacing problems and learning from mistakes through continuous improvement, rather than wating for perfection.

Dominiating: "either-Or"
Befudding us for at leat 25000 years ...
- Heraclitus
- Lao Tsu, Tao Te Ching
- Zen, Either/Or_ Kierkegaard
With "Either-Or" explicitly dominiating much of our, especially western, thinking for centuries.
- Seeing situations in blach & white
- Right solutions vs wrong
No grey: no allowance for uncertaintity.
⚖ W-1.6.3 Value stream VaSM vs Viable system ViSM
Project, Programme, Portfolio (P3)
Project, Programme, and Portfolio Management (P3M) is the application of methods, procedures, techniques, and competencies to achieve a set of defined objectives.
It encompasses three key areas:
- Project Management: Focuses on delivering specific outputs within defined constraints such as time, cost, and quality. Projects are unique, transient endeavors with clear objectives and deliverables.
- Programme Management: Involves managing a group of related projects in a coordinated way to achieve benefits and control not available from managing them individually. Programmes are designed to deliver strategic objectives and transformational change.
- Portfolio Management: Concerns the centralized management of one or more portfolios to achieve strategic objectives. It involves selecting, prioritizing, and controlling an organization’s projects and programmes in line with its strategic goals and capacity to deliver.
Effective P3M ensures that initiatives are aligned with organizational strategy, resources are used efficiently, and desired outcomes are achieved.
Cybernetics S1-S5 into S1-S6
The are three areas mentioned: Operation (O), Management (M) and the environment (E).
Systems are classified and numbered system-1 to system-5.
💡 The environment fits into the strict naming scheme when named system-6.
Command & control a viable system
"The commander must work in a medium which his eyes cannot see, which his best deductive powers cannot always fathom, and with which, because of constant changes, he can rarely become familiar."
Carl von Clausewitz, 1832. On War.
To put effective command and control into practice, we must first understand its fundamental nature—its purpose, characteristics, environment, and basic functioning.
We often think of command and control as a distinct and specialized function—like logistics, intelligence, electronic warfare, or administration—with its own peculiar methods, considerations, and vocabulary, and occurring independently of other functions.
But in fact, command and control encompasses all military functions and operations, giving them meaning and harmonizing them into a meaningful whole.
None of the above functions, or any others, would be purposeful without command and control.
Command and control is not the business of specialists—unless we consider the commander a specialist—because command and control is fundamentally the business of the commander.
Command and control is the means by which a commander recognizes what needs to be done and sees to it that appropriate actions are taken.
- Sometimes this recognition takes the form of a conscious command decision—as in deciding on a concept of operations.
- Sometimes it takes the form of a preconditioned reaction—as in immediate-action drills, practiced in advance so that we can execute them reflexively in a moment of crisis.
- Sometimes it takes the form of a rules-based procedure—as in the guiding of an aircraft on final approach.
- Some types of command and control must occur so quickly and precisely that they can be accomplished only by computers—such as the command and control of a guided missile in flight.
Other forms may require such a degree of judgment and intuition that they can be performed only by skilled, experienced people—as in devising tactics, operations, and strategies.
- Sometimes command and control occurs concurrently with the action being undertaken—in the form of real-time guidance or direction in response to a changing situation.
- Sometimes it occurs beforehand and even after. Planning, whether rapid/time-sensitive or deliberate, which determines aims and objectives, develops concepts of operations, allocates resources, and provides for necessary coordination, is an important element of command and control.
Furthermore, planning increases knowledge and elevates situational awareness.
Effective training and education, which make it more likely that subordinates will take the proper action in combat, establish command and control before the fact.
The immediate-action drill mentioned earlier, practiced beforehand, provides command and control.
A commander’s intent, expressed clearly before the evolution begins, is an essential part of command and control.
Likewise, analysis after the fact, which ascertains the results and lessons of the action and so informs future actions, contributes to command and control.
Some forms of command and control are primarily procedural or technical in nature—such as the control of air traffic and air space, the coordination of supporting arms, or the fire control of a weapons system.
Others deal with the overall conduct of military actions, whether on a large or small scale, and involve formulating concepts, deploying forces, allocating resources, supervising, and so on. This last form of command and control, the overall conduct of military actions, is our primary concern in this manual.
Unless otherwise specified, it is to this form that we refer. ...
An effective command and control system provides the means to adapt to changing conditions.
We can thus look at command and control as a process of continuous adaptation.
We might better liken the military organization to a predatory animal—seeking information, learning, and adapting in its quest for survival and success—than to some “lean, green machine.”
Like a living organism, a military organization is never in a state of stable equilibrium but is instead in a continuous state of flux—continuously adjusting to its sur- roundings. ...
Second, the action-feedback loop makes command and control a continuous, cyclic process and not a sequence of discrete actions—as we will discuss in greater detail later.
Third, the action-feedback loop also makes command and control a dynamic, interactive process of cooperation.
As we have discussed, command and control is not so much a matter of one part of the organization “getting control over” another as something that connects all the elements together in a cooperative effort.
All parts of the organization contribute action and feedback—“command” and “control”—in overall cooperation.
Command and control is thus fundamentally an activity of reciprocal influence—give and take among all parts, from top to bottom and side to side.
(MCDP6 1996).
⚖ W-1.6.4 Flexibility in architecture, engineering, design
Fixed mindset trivial systems
The mindset for trivial systems is that they are that simple everyone understand it, anybody can do it.
As soon it is experienced non-trivial than nobody is there to do it.
Example St-Pauls cathedral
A cathedral is a non trivial construction, for example: St Pauls Cathedral .
(to visit) and
(wikipedia)
 The task of designing a replacement structure was officially assigned to Sir Christopher Wren on 30 July 1669.
Charged by the Archbishop of Canterbury, in agreement with the Bishops of London and Oxford, to design a new cathedral that was "Handsome and noble to all the ends of it and to the reputation of the City and the nation".
The design process took several years, but a design was finally settled and attached to a royal warrant, with the proviso that Wren was permitted to make any further changes that he deemed necessary.
The cathedral was declared officially complete by Parliament on 25 December 1711 (Christmas Day).
The task of designing a replacement structure was officially assigned to Sir Christopher Wren on 30 July 1669.
Charged by the Archbishop of Canterbury, in agreement with the Bishops of London and Oxford, to design a new cathedral that was "Handsome and noble to all the ends of it and to the reputation of the City and the nation".
The design process took several years, but a design was finally settled and attached to a royal warrant, with the proviso that Wren was permitted to make any further changes that he deemed necessary.
The cathedral was declared officially complete by Parliament on 25 December 1711 (Christmas Day).
 The final design as built differs substantially from the official Warrant design.
Many of these changes were made over the course of the thirty years as the church was constructed, and the most significant was to the dome.
The final design as built differs substantially from the official Warrant design.
Many of these changes were made over the course of the thirty years as the church was constructed, and the most significant was to the dome.
After the Great Model, Wren resolved not to make further models and not to expose his drawings publicly, which he found did nothing but "lose time, and subject [his] business many times, to incompetent judges".
The Great Model survives and is housed within the cathedral itself.
The cathedral is one of the most famous and recognisable sights of London.
Its dome, surrounded by the spires of Wren's City churches, has dominated the skyline for over 300 years.
At 365 ft (111 m) high, it was the tallest building in London from 1710 to 1963.
The dome is still one of the highest in the world.
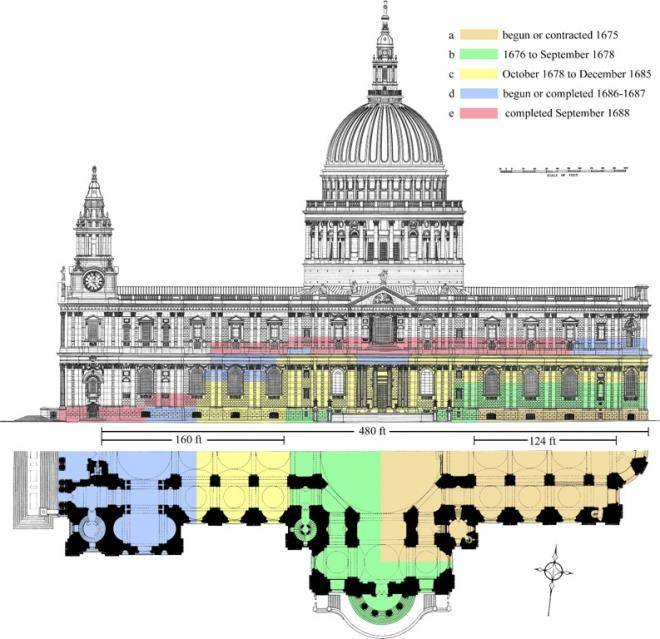 The St Paul’s Collection of Wren Office drawings is unrivalled as a record of the design and construction of a single great building by one architect in the early modern era.
Consisting of 217 drawings for St Paul’s dating between 1673 and 1752 (nine others, catalogued in the final section, are unconnected with the building), the Collection was originally part of a much larger corpus.
This included 67 drawings now in the Wren Collection at All Souls College, Oxford, and a single plan at Sir John Soane’s Museum in London.
The whole corpus is only a fraction of what must originally have existed, for it contains very few executed designs and just one full-sized profile for construction, although hundreds – if not thousands – of such drawings must have been made.
The St Paul’s Collection of Wren Office drawings is unrivalled as a record of the design and construction of a single great building by one architect in the early modern era.
Consisting of 217 drawings for St Paul’s dating between 1673 and 1752 (nine others, catalogued in the final section, are unconnected with the building), the Collection was originally part of a much larger corpus.
This included 67 drawings now in the Wren Collection at All Souls College, Oxford, and a single plan at Sir John Soane’s Museum in London.
The whole corpus is only a fraction of what must originally have existed, for it contains very few executed designs and just one full-sized profile for construction, although hundreds – if not thousands – of such drawings must have been made.
He revised the design stage by stage as work moved from one part of the building to the next.
The entire design process depended on close collaboration between Wren and his draughtsmen. Often working in pairs, they produced finished or alternative schemes for his approval and made large-scale working drawings for construction.
Race to the moon
The Space race
was a 20th-century competition between two Cold War rivals, the United States and the Soviet Union, to achieve superior spaceflight capability.
It had its origins in the ballistic missile-based nuclear arms race between the two nations following World War II and had its peak with the more particular Moon Race to land on the Moon between the US moonshot and Soviet moonshot programs. The technological advantage demonstrated by spaceflight achievement was seen as necessary for national security and became part of the symbolism and ideology of the time. ...
Gagarin's flight led US president John F. Kennedy to raise the stakes on May 25, 1961, by asking the US Congress to commit to the goal of "landing a man on the Moon and returning him safely to the Earth" before the end of the decade.
The US successfully deploying the Saturn V, which was large enough to send a three-person orbiter and two-person lander to the Moon. Kennedy's Moon landing goal was achieved in July 1969, with the flight of Apollo 11.
It is this program met those many launches that initiated the project management as we know these days (2024) for information technology.
The used computers in those days were the first ones that could be used enabling those projects.
The
Learning the Lessons of Apollo 13
 The story of Apollo 13 is one of hope, inspiration and perseverance, and one that holds many useful parallels for those in the field of information system project management.
The story of Apollo 13 is one of hope, inspiration and perseverance, and one that holds many useful parallels for those in the field of information system project management.
- Train Constantly: keep training until the last moment. Backup crew and test environment training beside.
- Prepare for the Unexpected: a crucial part of the program
- Never Consider Defeat: When disaster strikes on a project, as long as you proceed from the standpoint that you can succeed and must succeed, you'll find you have the drive to see that it will succeed.
- Improvise: When being crippled, use ingenuity to solve their problems.
- Take Risks: knowing when to have cut corners, take chances to achieve results.
- Turn Failure into Success: The adage “Unless we learn from history, we are doomed to repeat it”. Learn from failures.
Open mindset non trivial systems
What we can learn from these kind of great examples:
- A design is only needed up to start reliable to what as assumed to be possible without all kind of details.
- Details for design and build are to be solved during the building in cooperation with the customer.
More examples like this one of a non trivial project, non trivial construction can be found.
The questions for this is: why should we do it different for non trivial information systems?
Organisational culture
BlueDelphins:
Hence, it is dependent above all, on the leadership skills of management, to implement a vivid corporate culture, which embraces change as a steady companion of agile living.
SIMF understanding the management improvement cycle
- A vision: Product / Service
- Geo-mapped roles
- Persons methodologies
- Flows, value streams
- Optimizing at constraints
- Functionality, technology
- Safety, technology
- Product Service knowledge
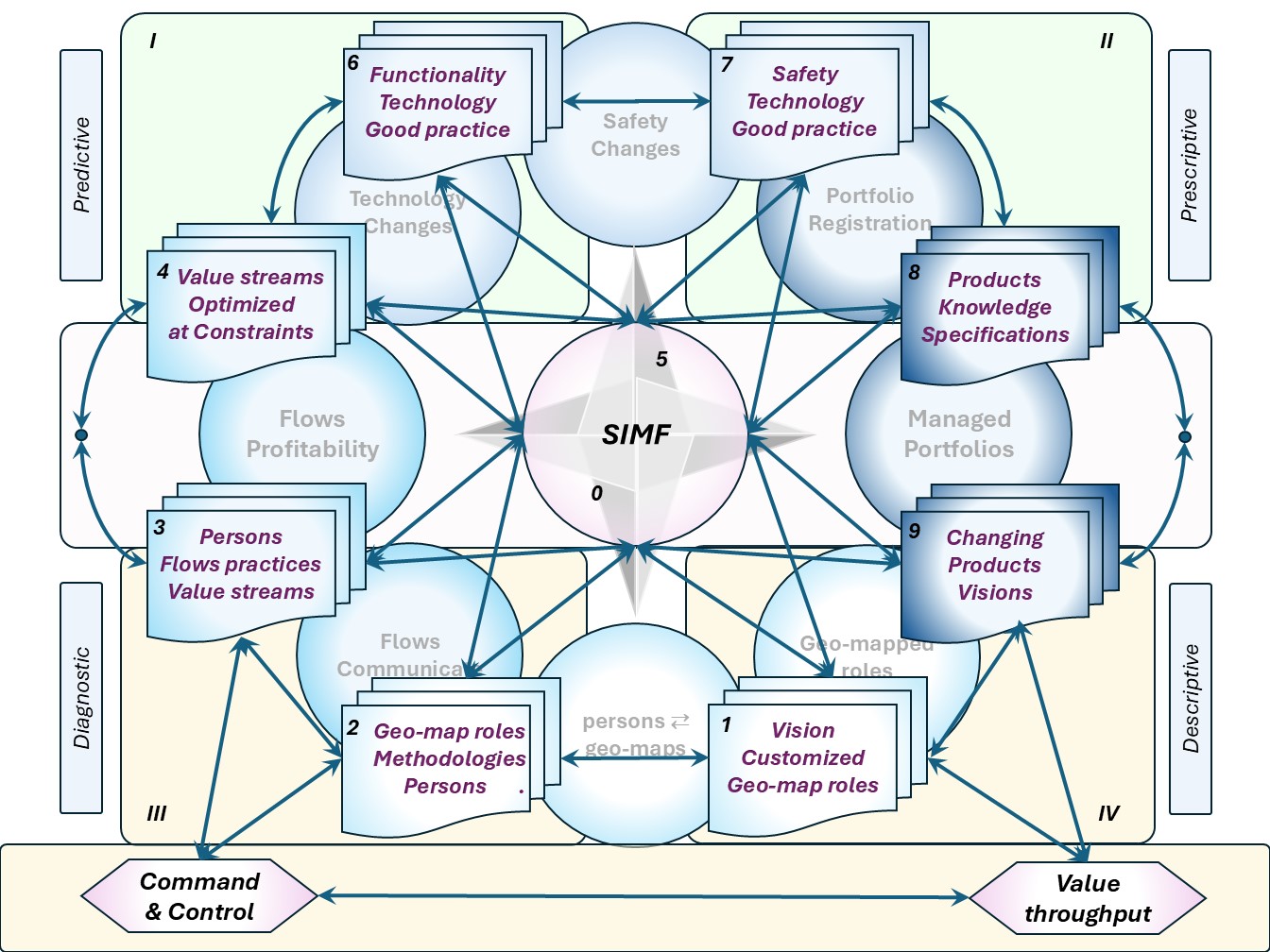
in a figure:
See right side.
💡 Start with knowing what task roles are relevant for the organisation and work from there to value streams going for aligning technology achieving the knowledge of the portfolio.
W-2 Command & Control working on gaps for solutions

W-2.1 Understanding ICT Service Gap types
Preparing the building of any non trivial construction sould include safety.
❗Aspect:
People, safety, functioning topics are:
- high level design & planning
- detailed design & realisation
- evaluation & corrections
A viable system is non trivial, it will be repeated in structures in every layer.
Conscious leading a system by command & control needs only the information for what is relevant in understanding what is going on.
The shared vison mission defines a direction.
⚖ W-2.1.1 Understanding the technical design processes
Development of products and processes as a single effort
A confusion:
What is called ‘waterfall’ or sometimes ´v-cycle’ is in fact systems engineering.
It is not project management although the links and connections are tight. (Jean-Charles Savornin)
See ISO
ISO 15288 on: Systems and software engineering — System life cycle processes
Systems Thinking in Project Management
The term "system" is often used to describe a collection of processes.
However, it is only sometimes used in the form defined by Systems Engineers.
INCOSE definition:
- Systems engineering is an interdisciplinary approach and means to enable the realization of successful systems.
It focuses on defining customer needs and required functionality early in the development cycle, documenting requirements, then proceeding with design synthesis and system validation while considering the complete problem.
There are shorter ones, my favorite is...
- Systems engineering is the development of products and processes as a single effort.
The point of these two definitions is that when someone speaks of "systems," they don't always speak of the processes that go along with the products.
Separation of product from process is the basis of some "world views", that is not a system view.
Another confusion:
A critically missing process in many IT projects, especially Agile development projects, is the principles of Systems Engineering.
Systems Engineering dominates the programs in Space Flight, Embedded Systems, Software Intensive Systems of Systems.
In these domains, 12 principles are used to increase the probability of success.
These principles come from Section 3.2 of Engineering Elegant Systems: Theory of Systems Engineering, A Whitepaper, Michael D. Watson, NASA Marshall Space Flight Center (2020).
Systems Engineering activities Principles
- Systems engineering integrates the system and the disciplines considering the budget and schedule constraints
- Complex Systems build Complex Systems
- The focus of systems engineering during the development phase is a progressively more profound understanding of the interactions, sensitivities, and behaviors of the system.
Sub-Principles:
- Requirements and models reflect the knowledge of the system
- Requirements are specific, agreed to preferences by the developing organization
- Requirements and design are progressively defined as the development progresses
- Hierarchical structures are not sufficient to fully model system interactions and couplings
- A Product Breakdown Structure (PBS) provides a structure to integrate cost and schedule with system functions
- Systems engineering has a critical role throughout the entire system life cycle.
Sub-Principles Systems engineering :
- obtains an understanding of the system
- models the system
- designs and analyzes the system
- tests the system
- has an essential role in the assembly and manufacturing of the system
- has an indispensable role during operations and decommissioning
- Systems engineering is based on a middle-range set of theories.
Sub-Principles Systems engineering has:
- a physical/logical basis specific to the system
- a mathematical basis Sub-Principle
- a sociological basis particular to the organization
- Systems engineering maps and manages the discipline interactions within the organization
Systems Engineering managing Principles
- Decision quality depends on the coverage of the system knowledge present in the decision-making process
- Both Policy and Law must be adequately understood, not overly to constrain or under constrain the system implementation
- Systems engineering decisions are made under uncertainty, accounting for risk
- Verification is a demonstrated understanding of all the system functions and interactions in the operational environment
- Validation is a demonstrated understanding of the system's value to the system stakeholders
- Systems engineering solutions are constrained based on the decision timeframe needed for the system
Agility Project Management and Systems View.
In the search for a definition of Agile Project Management, the Declaration of Interdependence (DoI) proposed a set of principles.
We are, in fact, "engineering a system" when we develop software and manage the project that develops the software.
Are these principles compatible with the systems engineering view?
Realizing successful systems (products) is undoubtedly the goal.
- Focusing on customer needs is essential.
- Defining customer needs is the result of requirements elicitation and management.
- Doing this early in the system's life cycle is critical to successfully realizing those needs.
- Synthesizing the design is an essential activity in any development project.
This is what separates operations from development.
- Validating the complete system provides the means to end the project
So why does the Agile Project Management world still need to have a connection to the Systems Engineering worldview?
It seems like a natural connection.
A much better connection than to the linear, silo-focused set of processes described in PMBOK.
In PMBOK, the customer is connected to the process loop at the start and at the end.
There is however no connection made, more work needed.
Definitions of terms like value, rapid, early, customer, frequent, innovation, performance, effectiveness, and reliability are used by the DoI.
When these terms are given "units of measure," and those units of measure are connected to analytical outcomes for the business, Agile Project Management will have moved into the system engineering domain. A domain where the "trade space" of decisions is where management and engineers live every day.
Asking questions like:
- How does this action or technology benefit our project in some measurable way?
- What risks are reduced, enhanced, or made visible by this technology or action?
- continually: "How do we know that customers will get what they asked for?"
⚖ W-2.1.2 Understanding technical performance choices
Performance & Tuning - Software, Hardware.
Solving performance problems requires understanding of the operating system and hardware.
This is basic classic, the architecture was set by von Neumann.
Optimizing is balancing between choosing the best algorithm and the effort to achieve that algorithm.
The time differences between those resources are in magnitudes factor 100-1000.
➡ A single CPU,
these days many.
➡ limited internal memory,
these days capable of holding massive data.
➡ The external storage.
these days several types for speed and purpose even more massive data.
Neglecting performance questions could be justified by advance in hardware the knowledge of tuning processes is ignored.
Those days are gone, a Fundamental Turn Toward Concurrency in Software,
By Herb Sutter. (2009)
The Free Lunch Is Over .
If you haven´t done so already, now is the time to take a hard look at the design of your application, determine what operations are CPU-sensitive now or are likely to become so soon,
and identify how those places could benefit from concurrency. Now is also the time for you and your team to grok concurrent programming´s requirements, pitfalls, styles, and idioms.
❗ Moore's law is about the number of components, not speed. More:
👓 details
Additional components:
➡ multiple CPU's and the GPU farm for processing.
➡ external storage using the internal memory types avoiding mechanical delays.
➡ Storage in a network cam be a SAN (Storage attached Network) or a NAS (Network attached Storage).
They are different in behaviour and performance.
Performance Data processing
Performance is impacted by:
➡ Use of keys indexes, positieve and negative effects
➡ The order of sorting. For bulk processing presorted works the best.
Transactional applications are better with a random spread.
➡ Set in Limited physical sizing. Saving all history in a single space will have a negative impact.
There are more reasons to split spaces by historical values.
➡ Cache setting for both the OS level and DBMS.
For managing tables a DBA should be aware of the effects by choices.
File system caching configurations
👓 Use concurrent I/O to improve DB2 database performance (ibm 2012)
In some cases, caching at the file system level and in the buffer pools causes performance degradation because of the extra CPU cycles required for the double caching.
To avoid this double caching, most file systems have a feature that disables caching at the file system level.
This is generically referred to as non-buffered I/O. On UNIX, this feature is commonly known as Direct I/O (or DIO).
On Windows, this is equivalent to opening the file with the FILE_FLAG_NO_BUFFERING flag.
query concurrency management
To ensure that heavier workloads that use column-organized data do not overload the system when many queries are submitted simultaneously, there is a limit on the number of heavyweight queries that can run against a database at the same time.
You can implement the limit on the number of heavyweight queries by using the default workload management concurrency threshold. This threshold is automatically enabled on new databases if you set the value of the DB2_WORKLOAD registry variable to ANALYTICS. You can manually enable the threshold on existing databases.
The processing of queries against column-organized tables is designed to run fast by using the highly parallelized in-memory processing of data.
⚖ W-2.1.3 Data governance, knowing wat is going on
ELT processing pre & post steps
Doing Extract / Load processing there are many tools due to
👓 CWM (Common Warehouse Metadata specification).
The standard is almost forgotten in all hypes for tools.
Extract Transform Load ELT, Data Integration, control & performance usually only focus on the technical behaviour.
However doing ELT in real life something is missing, that is functional control & monitoring:
- What data, how many records are processed
- When did the process started and when was it ready
- Performance Processing optimized for bulk or for a small number of records.
- Restart processing options for error recovery.
This kind of logic is only possible by having an adjusted pre and post process in place.
That kind if fucntional logic is impossible to be solved by an external generic provision.
It is relative easy with local customisations and using local naming conventions.
In a figure:
See right side.
More
Details 👓
Transport of data - information
Having systems in place the usual question is how to propagate the data -information- from one system to another in a reliable way.
A technical service, "micro service" is a direct interactive way with no need for storage and building up an inventory with time delay.
Not every process is an interactive needing immediate response. Dedicated transfer steps are other options.
In any case a well defined storage location is needed with an associated security alignment.
In any case a well defined Functional control & monitoring is needed:
- What data, how many records are processed
- When did the process started and when was it ready
- Performance Processing optimized for bulk or for a small number of records.
- Restart processing options for error recovery.

Transferring moving information's conform moving goods.
More
👓 details
Any business application has little value when there are no interactions, no consumers.

⚖ W-2.1.4 Data governance, knowing who is acting at what
DevOps ICT - Transformations
Kim Cameron
In 2000 he became the architect of Microsoft’s Active Directory, which evolved into the most widely deployed identity technology used in enterprises globally.
As the growth of the Internet made the importance of identity increasingly evident, his role expanded to become chief architect of identity for Microsoft.
In 2004 he wrote the Laws of Identity, a document that has long influenced both technologists and regulators, and which Microsoft adopted to guide its innovation.
blog See: "laws of identity in brief".
The Laws Of Identity
Several types of usage an identity:
-
Employers “know” their employees, having verified their qualifications and made them part of an enterprise team.
They assign them a “corporate identity” through which they identify themselves to corporate systems.
To maximize productivity, employees typically log in once and work using their corporate identity for long periods of time.
The context has simply been that the employee is at work, doing his or her job.
-
Relationships with customers have been driven by sales and marketing departments, not by traditional IT departments.
The goal has been to eliminate friction (and clicks!) so new customers come on board – even before the enterprise knows the slightest thing about them – and then deepen the relationship and get to know the customer based on his or her specific needs and behaviors.
-
Clearly there are also cases where customers need access to their own valuable possessions and information, for example, in financial, health, insurance and government scenarios.
Here customers will be willing to jump through various hoops to prove their entitlement and protect what is theirs.
Any application developer, department, enterprise, or group of enterprises can create policies.
What is Azure Active Directory B2C?
Then applications and portals can, depending on their context, invoke the identity experience engine passing the name of a policy and get precisely the behavior and information exchange they want without any muss, fuss or risk.
(nov 2015)
PIM, Privileged Identity Management
What is
privileged identity management (PIM)?
PIM is a process or program for identifying the privileged accounts, also known as superuser accounts, within an organization.
Doing this can help with the monitoring, control and management of the access privileges each superuser has to the organization's resources in order to protect those resources from harm.
Superusers, such as database administrators and system administrators, can perform actions on an enterprise system that a typical end user cannot.
For example, a superuser can change other users' passwords; add, remove or modify user profiles; change device or network configurations; install new programs on enterprise endpoints; or modify enterprise databases or servers.
Business continuity management
BCM ( "Business and IT Continuity: Overview and Implementation Principles" (2008) a part of risk management.
Business Continuity is the term applied to the series of management processes and integrated plans that maintain the continuity of the critical processes of an organisation,
should a disruptive event take place which impacts the ability of the organisation to continue to provide its key services.
ICT systems and electronic data are crucial components of the processes and their protection and timely return is of paramount importance.
Business Continuity (BC) is now recognised as an integral part of good management practice and corporate governance.
Structured defined Cyber Security.
blog (Sarah Fluchs).
The least amount of information is needed at the pyramid top. If you want to communicate a product’s security to a consumer who only needs to use a product securely, you don’t need to communicate much. A list of features is fine.
A cybersecurity label assuring the list of features is met is fine too. This is what all the consumer IoT labels are for.
If you want to communicate a product’s security to an authority, they will want to know more.
At the pyramid bottom, your addressees need to make security decisions themselves for two reasons.
First, because they’re regulated themselves, as many critical infrastructure operators are.
They need to do their own threat models and risk assessment, and they need to explain their security measures to authorities themselves.
Second, because they often do a fair share of engineering themselves.
The products they buy are just building blocks that are further integrated into complex systems of systems
Interesting are the labels for the products, they give an idea of content within a managed portfolio supporting this kind of items.

W-2.2 Understanding ICT operating value streams
Building any non trivial construction is going by several stages.
❗Aspect:
Machines, technology topics are:
- high level design & planning
- detailed design & realisation
- evaluation & corrections
A viable system is non trivial, it will be repeated in structures in every layer.
Conscious leading a system by command & control needs only the information for what is relevant in understanding what is going on.
A shared vison mission is a pre-req.
⚖ W-2.2.1 Technology quality & risk rating
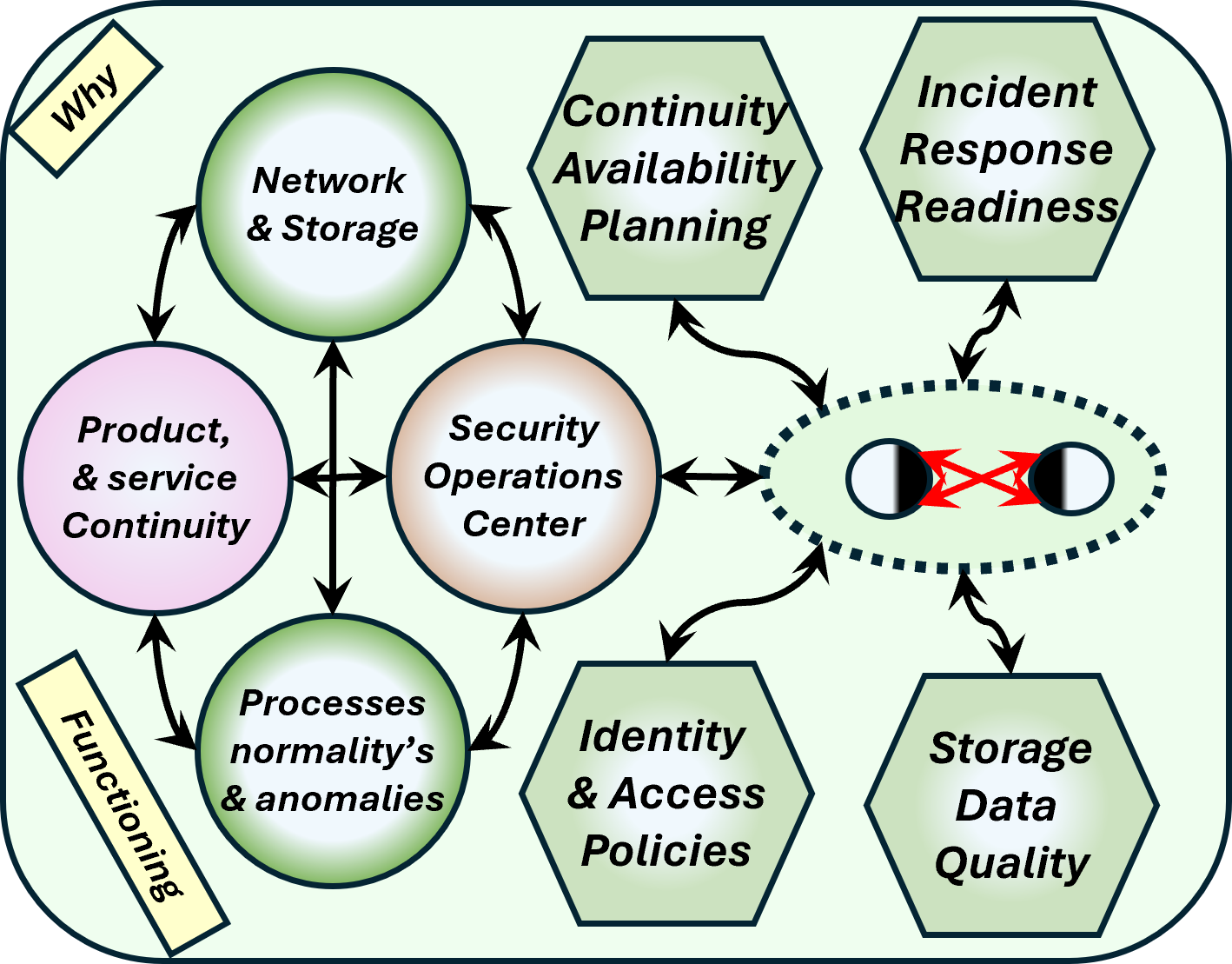
Communication acting at the viable system
CapCom: the primary point of contact and source of truth about the state of the system.
- Strong communication skills.
- High-level knowledge of the viable system.
- Sharing open communication with all that could possible help.
- Able to make quick, confident decisions how to proceed, know to who to delegate.
- Switch the interaction at the best moments to ones that give a signal to help.
- Access to all accountable roles, tasks within the viable system relevant solving evenets.
In IT Service management the goal of acting reacting got lost,
incidents, problems, changes.
👉🏾
CapCom these are not the attributes known from ITIL but are reverted to the source: the incident with apollo 13.
The time to react on an issue is important.
Variations:
- immediate like the nerve system,
- midterm like the oxygen with blood circulation
- long-term like the overall system body condition
Able to communicate within all levels is a prerequisite for able to react in time.
👉🏾 There is a duality in being very safe but not having the service available and running the service but that service has known safety issues.
To balance in the conflicts is a task role not to combine with either of the conflicting sides, segregation in duties.
Incident response readiness, education mandatatory internal
EU directive NIS2, the CapCom:
article 1
Member States adopt national cybersecurity strategies and to designate or establish competent authorities, cyber crisis management authorities, single points of contact on cybersecurity (single points of contact) and computer security incident response teams (CSIRTs).
EU directive NIS2, Also requires educations for executives:
article 20
Member States shall ensure that the members of the management bodies of essential and important entities are required to follow training, and shall encourage essential and important entities to offer similar training to their employees on a regular basis, in order that they gain sufficient knowledge and skills to enable them to identify risks and assess cybersecurity risk-management practices and their impact on the services provided by the entity.
Confusing:
prodcuts with digital elements is not technology neutral defined.
The assumption of simple devices would be different to complicated and complex or even chaotic is not underpinned.
Risk rating, readiness
This is a standard activity.
A split in technology related risk and fucntionality risks is not made yet although this is by nature of a system logical to do.
An open source option:
Ravib
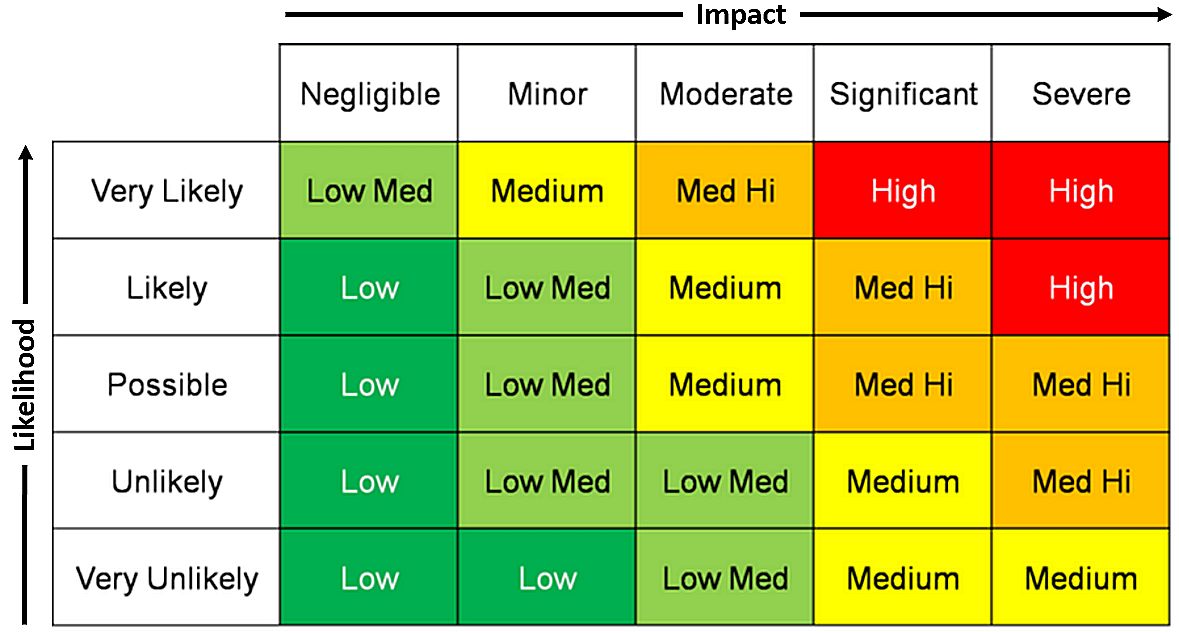 The purpose of this tool is to register risks in order to control them.
Controlling risks requires knowing your risks, assigning them to people who actively deal with them and keeping track of the measures that mitigate those risks. This tool supports in that.
This register is just a tool.
The purpose of this tool is to register risks in order to control them.
Controlling risks requires knowing your risks, assigning them to people who actively deal with them and keeping track of the measures that mitigate those risks. This tool supports in that.
This register is just a tool.
👉🏾 How well risks are controlled depends on how well the responsible people deal with them.
Technical resource qualities
Metrics:
kpis
- MTBF mean time before failure: the average time between repairable failures of a technology product.
- MTTR mean time to (◎), the average time it takes to:
- repair: repair a system (usually technical or mechanical). It includes both the repair time and any testing time.
- recovery: recover from a product or system failure. This includes the full time of the outage—from the time the system or product fails to the time that it becomes fully operational again.
- respond: is the average time it takes to recover from a product or system failure from the time when you are first alerted to that failure. This does not include any lag time in your alert system.
- resolve: fully resolve a failure. This includes not only the time spent detecting the failure, diagnosing the problem, and repairing the issue, but also the time spent ensuring that the failure won’t happen again.
- MTTF (mean time to failure) is the average time between non-repairable failures of a technology product.
- MTTA (mean time to acknowledge) is the average time it takes from when an alert is triggered to when work begins on the issue. This metric is useful for tracking your team’s responsiveness and your alert system’s effectiveness.
⚖ W-2.2.2 Information process: Identities, Access, incident response
Continuity planning
This goal and drivers are not about technology but driven by the business organisation.
Business continuity (r-steer)
measures are however technology related such as backup management, emergency planning, and crisis management.
The
recovery time objective (RTO) amd
recovery point objective (RPO) (techtarget)
are described from technology perspectives.
Metrics:
- RTO , Recovery Time Objective, is measured in time.
It is an important consideration in a disaster recovery plan (DRP).
The RTO is the maximum tolerable length of time that a computer, system, network or application can be down after a failure or disaster occurs.
- BIA, business impact analysis is needed.
With DR strategy and business continuity planning are driving the RTO goal
- RPO , recovery point objective, gives the age of information that must be recovered for normal operations to resume.
Businesses can choose to have any number of different tiers for an RPO based on workload and loss tolerance.
Portfolio, without an accurate inventory, there is no way having a complete BIA.
👉🏾 Simplistic if a computer, system or network goes down as a result of a hardware, program or communications failure:
- if the RTO is one hour, redundant data backup on external drives may be the best solution.
- If the RTO is five days, then tape or off-site cloud storage may be more practical.
👉🏾 The simplistic idea for a DR is missing the intentional actions disabling components.
- a redundant data backup that is lost at the same way as the primary gives no protection.
- Having no redundant fall backup processes for components in the system in place can break the complete system, not a single component.
Identity & access
The "Devils Triangle" on its own with IAM: Conflicting types of interests, focus areas.
Frictions:
- Implementing identities and access control is by technology but driven by the organisation.
- Securing technical systems is using the same shared technology as for the organisation.
- Segregation in duties, segregation type of processing in:
- by a person at several point in a critical flow where trustwothiness is important.
- type of processing work are important for the viable system as a whole.
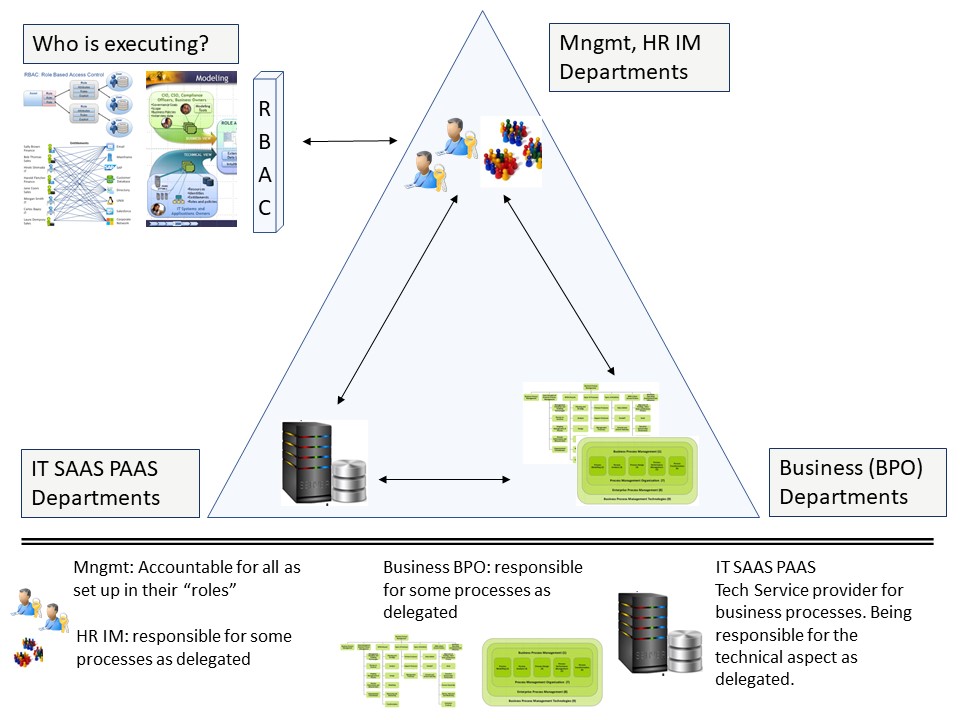
In a figure:
See left side
IAM (C-Serve).
The issue is not the execution of the actions implementing something, these are at the S1 level floor 0-1.
The issue is definining well defined policies that are aligning all area's with the frictions solving the higer level goals of the viable system as the organisation technology and change as a whole.
That is control S4 at level 3-4 and conscious choices S5 at 4-5.
Well defined policy challenges:
- Event differentation in:
- Defining access to system, event: "account log on", or
- Defining access to a resource, event: "account accessing to ... for ..."
- Account differentation in:
- Personal accounts (PA). Differentation PA-s into:
- Used for activities part of a value stream in standard activities.
- Used for activities part of a value stream in privileged activities.
Overruling discretionary defined described process steps is an example.
- Generic administrative purposes for activities not part of a value stream.
- Used for activities not part of a value stream having privileged activities.
The local administrative rights usage on a machine is an example
- Non Personal accounts (NPA). Differentation NPA-s into:
- Service account managing the information, data of a business application
- Service account managing the logic, code of a business application
- Platform account part of a platform limited to a part of defined functionality
- System account part of the operating system
Some systems support facilities to use the NPA avoiding the need using passwords. service a
- Anonymous account (AA) representations that serve for processing when an account is logical impossible being defined.
The log in process of an account is an example for the moment a PA account is logically not known.
- Group usage for:
- Grouping accounts for shared access to a resources or shared definition to log on.
- Defining access rights to resources. Main types of resource access: Read, Write, Create.
Details for access is not exhaustive, behaviour in types can be surprising in technical details.
- Groups can be used for access for similar types as mentioned for PA-s and NPA-s
- Environmental differentation for DTAP: Develop, Test, Acceptance, Prodcution for:
- Accounts, Groups
- Resources
- There are many resource types, for example:
- Machines (logical)
- A shared access to a point in a file system structure
- Files within a file system structure
- Records within a database system
- Defined stored procedure within a database system
- Objects defined at some type of storage
- Account Groups wiht their content at some IAM system
- Operating system, database system, platform, logs for technical events c
- etc.
- There are other types, the list is not exhausitve, e.g.:
- Idenetity, access domains (AD clusters).
- Machine clusters, segmentation for reducing risks.
- Virtual networks, segmentation for reducing risks.
⚖ W-2.2.3 Safety Monitoring for anomalies by open source issues
Security operations Processes
The security operations center is often outsourced, not being an indespensible part of the viable system.
This is possible by the more generic aspects of safety.
What functionality in details is needed is different for each system at a moment.
👉🏾 An outsourced SOC introduces a problem in more complicated systems where the anomalies of the internal processes is decisive for understanding a healty situation recognizing unhealty signals.
Security operations: The Team
Cybersecurity's the Team (linkedin post)
Critics: The ciso is missing the trainers on the side line like risk managers compliance managers.
The people watching the game employees operaton managers and ofcourse the club owners in the skybox paying top dollars for the players which resembles the business owner or board.
The FIFA as regulatory compliance institutions.
Imagine a football team, but instead of players, we have cybersecurity heroes on the field, each playing a vital role to secure the "goal" (protecting systems and data)!
Here's how the ultimate Cybersecurity Dream Team shapes up:
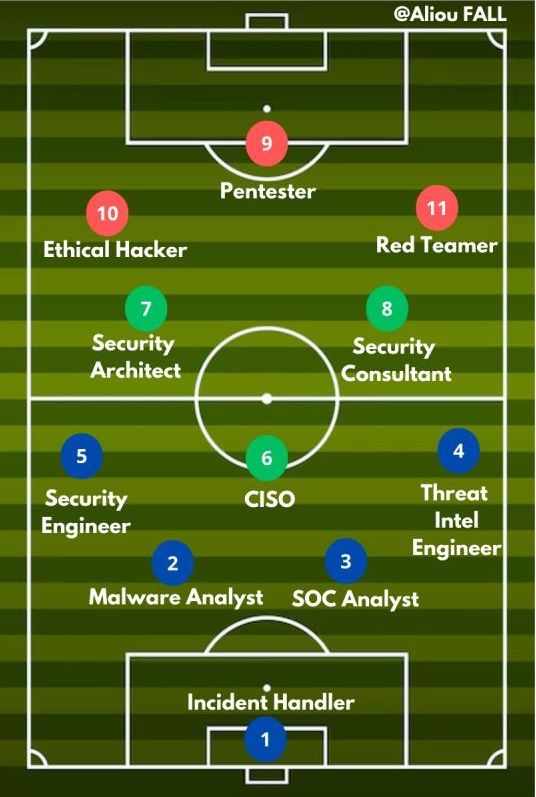
- Incident Handler: The goalkeeper, always ready to block threats and recover from attacks.
- Malware Analyst: The defender who tackles malicious players (malware) and keeps them off the field.
- SOC Analyst: The sweeper, constantly scanning the field for suspicious activity to prevent attacks.
- Threat Intelligence Engineer: The playmaker, analyzing the opponent's strategy and planning countermeasures.
- Security Engineer: The solid midfielder, building a resilient defense and ensuring the game flows securely.
- CISO: The captain, leading the team with strategy, vision, and oversight.
- Security Architect: The tactician, designing the winning formation (secure infrastructure).
- Security Consultant: The team’s engine, delivering expert advice and strategic "passes" to ensure both defense and attack operate at peak performance.
- Pentester: The striker, finding and exploiting weak spots in the defense (but for good!).
- Ethical Hacker: The winger, always pushing boundaries to test the team’s resilience.
- Red Teamer: The challenger, simulating real-world attacks to prepare the team for anything.
Together, they form an unbeatable force, each with a unique role to ensure every play (whether defense or attack) is executed flawlessly. (Credits to @Aliou FALL.)
⚖ W-2.2.4 Continuity monitoring with anomalies known internal processes
Monitoring, Network - Storage
Organizations are debating the need of a SOC, what kind of SOC and which components their SOC should include.
SOC Roles and Responsibilities .
SOCs can provide continuous protection with uninterrupted monitoring and visibility into critical assets across the attack surface.
They can provide a fast and effective response, decreasing the time elapsed between when the compromise first occurred and the mean time to detection.
Product & Service continuity
The effects of the SOC centre is directly related to what external customers are experiencing.
Therefor colour brown is chosen although the others in this area are green, technology.
There is a continuously feed back knowledge needed of the organisational needs.
Therefor an activity with the colour magenta is present in the SOC interaction.
Monitoring, Processes - value stream flows
Knowing how processes are normal functioning, how value streams are normally behaving is learning from measurements. Learning from information, data.
This is contionously changing evolving approach, applying AI is in a hype.
Secure AI Access by Design , enabling Safe Usage of GenAI Apps.
The rapid proliferation of GenAI apps, coupled with their unique characteristics and evolving AI ecosystems have introduced new security challenges.
Empower your security teams to not only keep pace with the latest GenAI apps but make informed risk-based decisions about which apps to sanction or tolerate.
These policies can be customized based on user roles, departments or specific data uploads, helping ensure that AI apps are used in compliance with your organization’s security and governance standards.
The questions in this: what are the " organization’s security and governance standards"?
From: "How CISOs Are Supercharging Their Teams With Generative AI Augments" (gartner 2024, William Dupre, Anthony Carpino, Nader Henein, Kevin Schmidt), notes for GenAI.
- come with a unique set of risks when compared with other AI implementations.
- cost for internal enterprise use cases does not leave much room for trial and error.
- will change how organizations design jobs, resource tasks and allocate responsibilities across all facets of the enterprise.
The initial hype around GenAI rushed many organizations into adopting the technology without much in terms of planning.
Scenarios like this come with a high rate of risk because, outside of some fringe cases, the reward will never match the hype.
The results are often months of trial and error, followed by a retroactive assessment, a financial write-off and potentially a sacrificial executive departure, depending on the size of the write-off.
The bigger impact will come later, in the form of opportunities lost when the rollout of generative capabilities is delayed.
The paradox, failure by:
- FOMO - fear of missing out.
- overconfidence fluff and fud.
"We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run." ( Amara's law)

Several examples for AI usage, one of them (no 3):
- Target 'applications': Code assistant tools
- Relevant data (knowledge graph/vector DB): Source code, unit tests, user stories
- Outcome: Improve application security by providing developers with automated tests focused on security.
- How it works: Code assistant AI tools can generate code and unit tests using prompts from developers.
Some of those unit tests could be negative or adversarial tests to stress test the code.
The system could also generate examples of how the code could be exploited if the developer inadvertently created vulnerable code.
The assumption of the required creativity could be automated trustworthy is questionable.

W-2.3 Information systems: Actuators - Steers
Using a system is simpler than designing those actuators in the construction.
❗Aspect
Processes topics are:
- high level operations & planning
- detailed operations & realisation
- evaluation & corrections
A viable system is non trivial, a repeated structure in every layer.
Every layer has their actuators to manage by observing for what is needed.
Without knowing the shared goal, mission, there is no hope in achieving a destination by improvements.
⚖ W-2.3.1 Communicating a shared value, mission for understanding
A history for he most complex social system: top-down
A short extract from the
introduction "conversations for action" (fernando flores).
Argues that certain speech acts, particularly requests, promises, offers, assessments, and declarations, serve as building blocks for activating and fulfilling commitments in working relationships and, hence, in organizations.
The essays in his book are all about how to effectively make commitments that allow us to create something of value, to generate value for ourselves and for others in the world.
In essence, they are about instilling a culture of commitment in our work with others, whether that be in an organization, our own start up, or even in working together as a family to get ahead or raise children.
He was anticipating what would become the greatest challenge of capitalism hence far: unregulated free markets that coexist with value creation for the world at large.
❶ The point is that people work together to produce value, not just for self interest.
The networks of commitments/conversations for action framework for designing organizations makes explicit who is creating value and for whom value is being created, and what are the promises being completed that act as value producers at every step of the way.
The core business has to think about how its products, manufacturing processes, business processes, employee relations, services, and role in the community impact the world.
❷ Designing work to produce value is very different from designing work for maximizing the self-interest of each party involved.
Fernando Flores developed a unique theory of work and organizations that has had numerous practical applications.
The seeds of these classic works were first developed in his dissertation, “Management and the Office of the Future,” which was written in 1980.
A system without classical hierarchy: Cybersyn
A viable system according
CyberSyn (1970-s) ViSM is a different context than the value stream VaSM.
On July 13th 1971 Stafford Beer received a letter from Fernando Flores, then President of the Instituto Technologico de Chile, and Technical General Manager of Chile's equivalent of the National Enterprise Board, which had been charged with the wholesale nationalisation of the economy.
Flores spoke of the "complete reorganisation of the public sector of the economy" and said he was "in a position from which it is possible to implement, on a national scale, at which cybernetic thinking becomes a necessity, scientific views on management and organisation". ...
❸ The entire story has been told on several occasions, but some accounts miss the essential nature of this, and indeed all VSM applications: the key is to enhance and encourage autonomy at all levels (as the only way of dealing with environmental variety) but to ensure that the autonomous parts work together in a harmonious, coherent fashion and thus enjoy the synergy which comes when parts join together to create a whole-system.
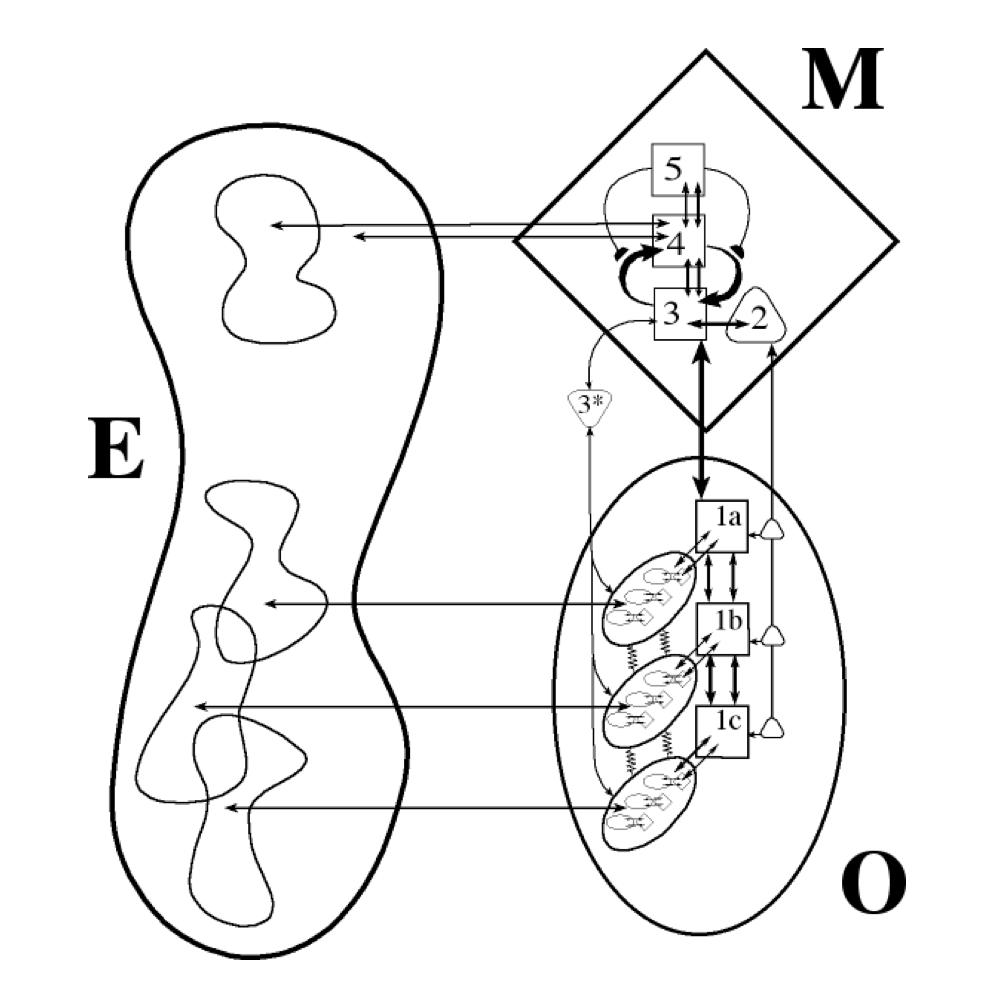
The viable system as a whole
A viable system according
Stafford Beer (1960-s) ViSM is a different context than the value stream VaSM.
❹ The model was developed during the 1950s as a practical tool capable of dealing with issues of organisational structure.
An understanding of the theory begins with the observation that operational units must be as autonomous as possible, and thus Beer's model of sees any organisation as a cluster of autonomous operational parts which bind together in mutually supportive interactions to create a new, larger whole system.
The job of management is to provide the "glue" which enables this to happen.
The diagram shows the three main elements:
- the operation (O) ,
- the management (M) and
- the environment (E).
VSMB_SYST_01: Classification systems types including the environemt 1-6.
➡System-1: The operation. The operational units are given as much autonomy as possible so they can respond quickly and effectively.
This is limited only by the requirements of system cohesion.
➡System-2: There will be conflicts of interest which must be resolved.
Harmonise interactions, to keep the peace, to deal with the problems.
Without this the system would shake itself to pieces.
➡System-3: is concerned with synergy. Look at the whole interacting cluster of operational units from its meta-systemic perspective.
Considering ways to maximise effectiveness through collaboration.
➡System-4: ensures the whole system can adapt to a rapidly changing and sometimes hostile environment.
It scans the outside world in which it operates, looks for threats and opportunities, undertakes research and simulations, and proposes plans to guide the system through the various possible pathways it could follow.
➡System-5: Rules come from System 5: not so much by stating them firmly, as by creating a corporate ethos, atmosphere: identity, ethos, ground rules under which everyone operates.
Re-thinking the workings of any organisation in these terms.
Take any enterprise and identify the operational parts. Questions to answer:
- How do conflicts of interest get resolved?
As the process continues a diagram something like the figure shown above will develop.
Once this is complete, the diagnosis can begin:
- Are the identified systems properly connected?
- Are they fit for purpose?
➡System-6: The purpose and regulations, come from System 6: the environment.
This is a real holistic way to look at organisations, systems, avoiding the technical hope beliefs.
⚖ W-2.3.2 Communications, variety & velocity and regulators
VSM, multiple information channels
Viable System Model (Michael Frahm)
The static facet of the VSM involves analyzing present systems using its framework.
The VSM is a strong homeostat.
The VSM can be very well combined with other methods like lean management, scrum, OKR and others.
This framework process goes beyond system viability, addressing issues within the corporate structure, and the structural and procedural organization.
The objective is to uncover cybernetic insights and pinpoint any absent elements by employing a cybernetics oriented checklist.
This serves as a foundation for the conceptual design of an enhanced system, ensuring a comprehensive consideration without the risk of overlooking crucial asp ects.
The VSM can be used for design, analysis and diagnosis. ...
❺ and six vertical information channels ...
VSMB_SYST_02: A classification in channel types: 1-6.
- Intervention Regulation
- Allocation of Resources
- Operational Interrelationships
- Interrelationships of the Environment
- Coordination (Sympathicus) System 2
- Monitoring (Parasympathicus)
❻ Moreover, within the Viable System Model, there exists an algedonic channel and transducers.
Algedonic signals, serving as alarm signals, convey either positive or negative messages directly into System-5.
Transducers, acting as converters, establish the interface between subsystems, guaranteeing the preservation of information authenticity.
Autonomy vs. Alignment: an important conflict wherof the outcome should never be resolved.
Viable System Model (Michael Frahm)
The organizational management can only be as good as the model on which it is based. ...
Dealing with megaprojects means dealing with the functioning of complex systems.
❼ Measuring and managing change, closed loops.
VSMB_SYST_03: A well defined way of using good regulators in functionality and functioning.
-
The Nyquist-Shannon sampling theorem
is an essential principle for digital signal processing linking the frequency range of a signal and the sample rate required to avoid a type of distortion called aliasing.
The theorem states that the sample rate must be at least twice the bandwidth of the signal to avoid aliasing.
This is a well known principle in electronical communications.
-
The Conant-Ashby good regulator theorem
, which established that "every good regulator of a system must be a model of that system," is a key tenet of the model-centric cybernetics paradigm.
The paradigm defines that a cybernetic regulator consists of a purpose, a model, a well-defined observer that only observes what the model requires as input parameters, some kind of decision-making intelligence, and a control channel that transmits selected actions or communications to the regulated system.
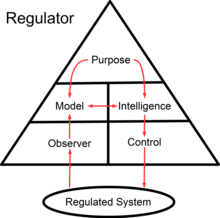 Thus, in order to be effective:
Thus, in order to be effective:
- a first-order (simple) cybernetic regulator requires a model of the system that is being regulated and
- a second-order (reflexive) regulator can only achieve reflexivity by also having a model of itself, which encodes a real-time representation of the possible variety that is available to the regulator.
- Finally, an ethical regulator is realized by using a third regulator to regulate a reflexive regulator to constrain it to only exhibit behavior that does not violate the ethical schema that is encoded in a third model.
A PID controller is the simplistic closed loop.
The good regulator adds specific requirements.
⚖ W-2.3.3 Communications, variety & velocity within systems
viablity the ability to survive or live successfully
The viable system (VSM) as a whole
VSM (Michael Frahm, Dr. Martin Pfiffner - research gate)
The predominant model of organizations in the past was the machine: A more or less complicated construction designed to perform a more or less well-defined task.
We still use this model when drawing organizational charts and describing processes.
But a machine does what it does. Its predetermined behaviour keeps its variety low.
A model of much higher variety is the model of the living organism. ...
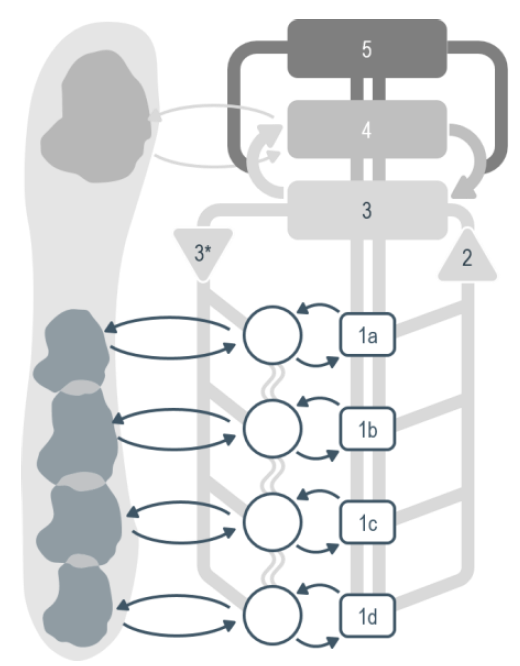 Todays management practice deals only with two of three organizational dimensions.
Todays management practice deals only with two of three organizational dimensions.
- The first dimension is the anatomy of the organism.
We use organizational charts to represent the anatomy of the organization.
We enter the names of the organizational entities (e.g., divisions or business units, steering and supervisory boards, finance or legal department) into the boxes of the chart.
- The second dimension is the physiology of the organism (i.e., the different processes and routines for breathing, digesting, sleeping, etc.).
It includes capabilities not found in machines, or only to a limited extent, such as the ability to adapt to fast-changing situations, to learn, to heal, to reproduce, to converse or even the ability to produce consciousness.
As a rule, however, we neglect the third dimension: the neurology of the organism.
VSMB_SYST_04: Enablement to adapt to external changes, variety.
- Have more variability in the system than expected to get exposed to.
- Allow, create controlled paradoxes, in the system for the variety.
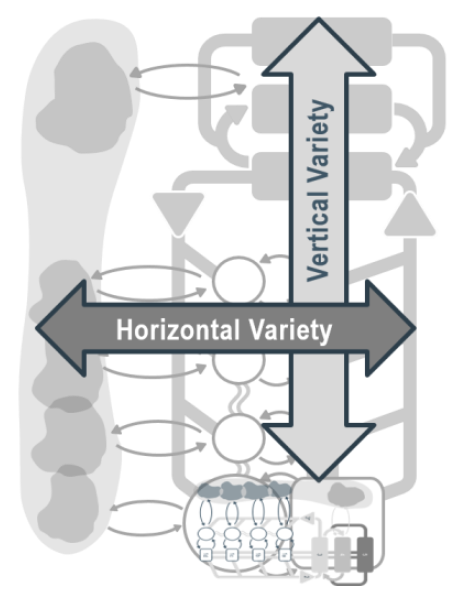 ❽
Variety is both in horizontal and vertical lines in the strcuture.
This is the most important dimension in modern projects because it helps managers cope with complexity and dynamics.
❽
Variety is both in horizontal and vertical lines in the strcuture.
This is the most important dimension in modern projects because it helps managers cope with complexity and dynamics.
- the third dimension of organization, the neurology of business, is designed rather poorly in most organizations.
The neurology of the organism is its control and communication structure.
Crucially, it ensures that the organism, or the organization, remains viable, that is, able to lead a separate existence.
System 3 (i.e. operational management) has several communication channels at its disposal.
These allow it to take well-informed decisions as well as to implement them even if they restrict the autonomy of System 1 (i.e. operations).
➡
Please note that we are talking about a control and communication structure here, and not about boxes in an organizational chart.
In the VSM, we no longer enter names in the System 3 box.
Instead, we ask a crucial question: What mission-critical tasks must System 3 perform, and who is involved?
Quite often, the same person is involved in different control functions, and thus "wears different hats".
The viable system as a whole, floor level 0-1
Categorizing an inventory of processing topics for secure information management (SIMF).
The result presenting it using nine areas is (see figure):
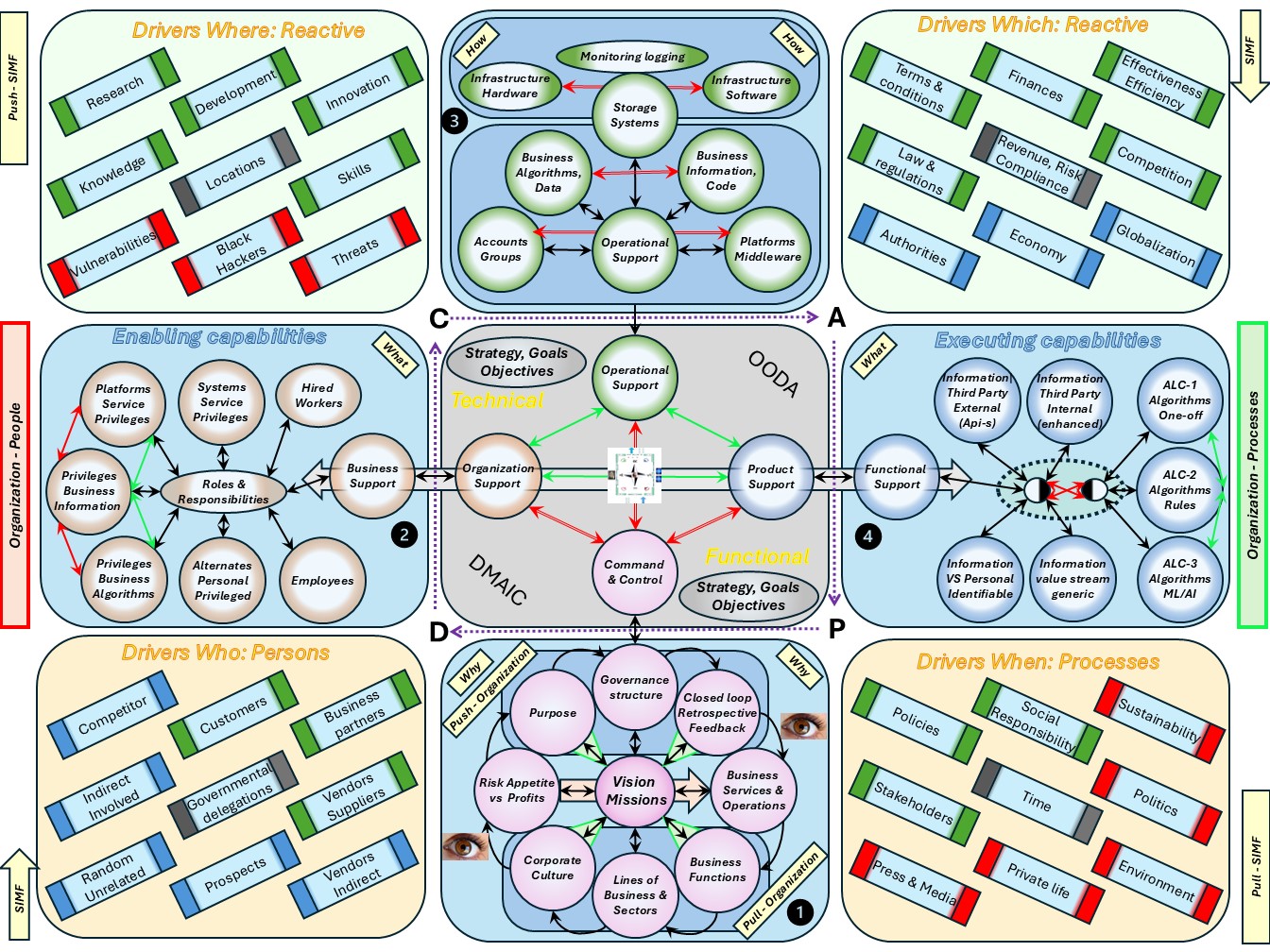
There was no immediate associations with ViSM (Viable System Model), but:
- Operations systems (green) in the middle to the top horizontal is VSM system-1. (O)
- Vision, missions (magenta) in the middle of the bottom horizontal is VSM system-5 (M)
- The middle horizontal:
- Enabling capabilities (brown) is system-4 (M)
- The gray area is alignment communication system-2
- Executing capabilities (indigo) is system-3 (O)
- The four corners are the environment (E) to deal with.
- The vertical in the middle follows bottom-up: strategy, tactical, operations.
- The horizontal in the middle follows left to right: steer, shape, serve.
⚖ W-2.3.4 Product vs Service provider & Top-down vs Bottom-up
Autonomy vs. Alignment: an important conflict whereof the outcome should never be resolved.
❾ The identity has important consequeunces.
Produktanbieter oder Dienstleister? (blog Conny dethloff "Diagnosis of organizations with the VSM")
When breaking down an organization into operational units, the VSM systems-1, this question is crucial:
- Do we want to be product providers or service providers at our core?
Knowing that most product providers also offer services around their products, this 0-1 decision should still be made as it has implications for the organizational design, namely:
- Product providers should cut operational units along product components.
- Service providers should cut the operational units along the user or customer journeys.
Let's take a trading organization and go through both cases.
- Product provider If a trading organization wants to establish the platform business, it is then a product provider.
The product is the platform. Product providers are characterized by the fact that they do not have a high rate of interaction with their customers and users along their journeys.
Of course, they should know them very well in order to incorporate appropriate features into their products.
- Service providers have a high rate of interaction with users and customers along the journeys.
They define themselves by the fact that they provide services at many points along the journeys.
Accordingly, service providers should position themselves along these journeys.
A trading organization that purchases goods and then sells them with a certain margin is a service provider.
Let's assume that goods are offered in the areas of food, fashion and home & living, i.e. in 3 shopping contexts.
Since customers have different wishes and needs in the respective 3 shopping contexts, the organization should respond to them internally using differentiated skills, processes and structures depending on the context. The service provider should therefore cut the operational units along these 3 shopping contexts and the journeys embedded in them.
Because of the necessary differences between the operational units, it is easy to see that the "commerce" and "platform" business models should not be executed by one and the same organization, otherwise neither of the two can really be served well from an organizational design perspective.
➡ Paradoxes in an organization increase variety and the range of actions. One could also say that without paradoxes an organization would operate in a way that is too simplistic and would neither be able to react appropriately to market surprises nor provide them with any.
Organizations need paradoxes. Task force mode therefore only works for a short time at best.
.
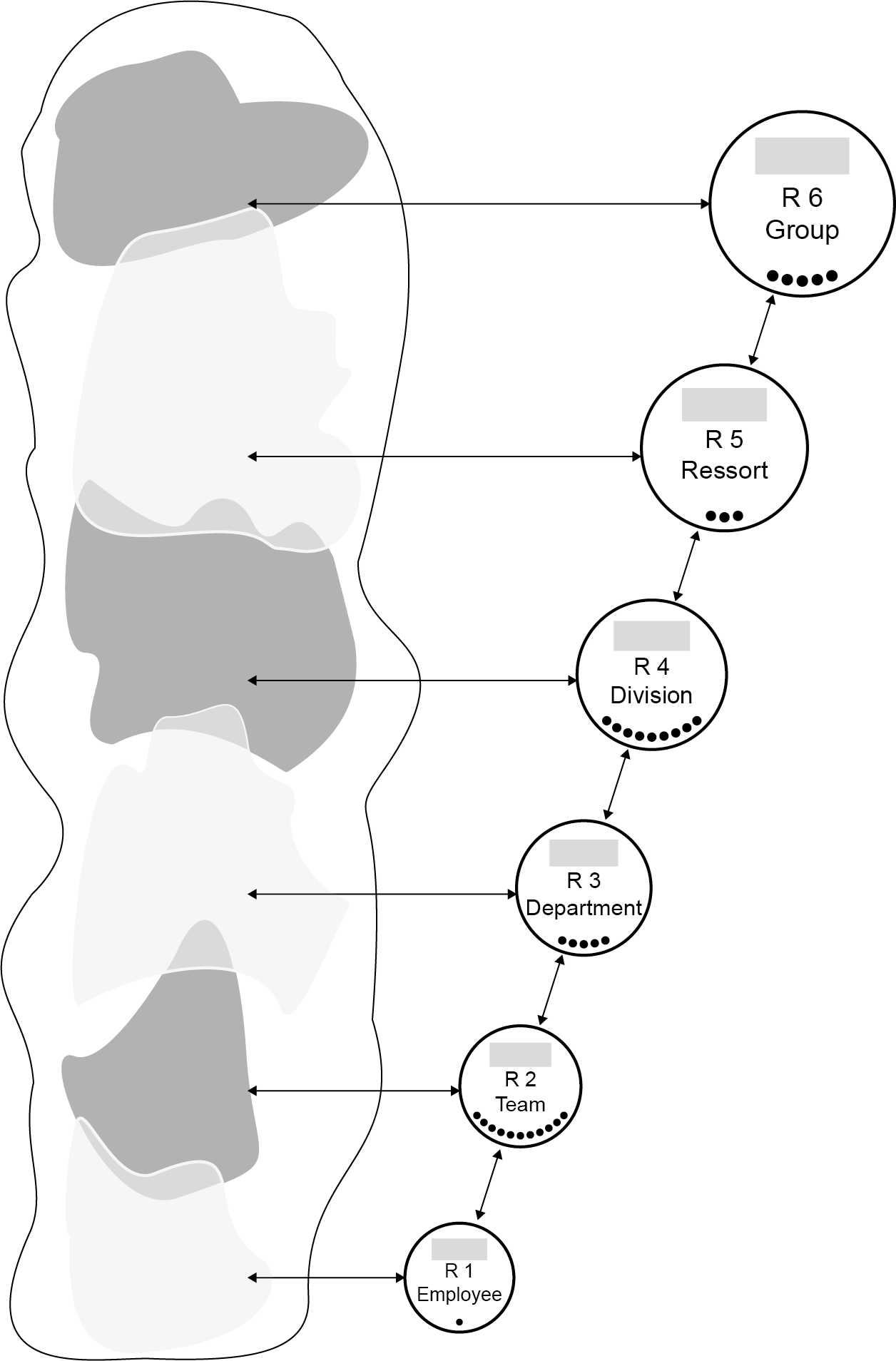
Top-down VSM vs bottom-up VSM.
Having the idea on what viable systems is about there are the following questions:
- Analyzing a system or designing and building
- Working top-down or bottom-up
What is seen in many examples is about analyzing systems top-down.
A bottom-up design and build is missing for viable systems.
The natural evolution is building those from the bottom into complex systems, going into complex systems build on complex systems.
❿
The bottom-up approach has become to live.
New insights:
- Selecting 5 areas in a nine plane is a representation for the 5 VSM systems.
- The simplest VSM representation is a nine plane.
- Building up complexity, a nine plane will create new planes that are interconnected in three dimensions.
- Both in the horizontal and vertical planes are new viable systems all interacting to each other.
The start for building new planes is when the team becomes too big.
A stable point is achieved when a division is completed, roles for accountability for the product are clearly settled.

W-2.4 Roles tasks in the organisation
Managing the working force at any non trivial construction is moving to the edges.
❗Aspect:
Communication, cultural changes are:
- Trusting the working force while getting also well informed
- Respect for people, learning investments at staff
- Accepting uncertainties and imperfections
Every layer has their actuators people to manage for what is needed.
Only knowing the shared goal, mission, there is hope in achieving a destination by improvements.
⚖ W-2.4.1 Team member and organic system roles
team diversity - roles I
Humans are viable systems and follow what is defined by some unknown invisible goal, a purpose.
The personal interest vs the social community is a dichotomy.
Belbin Team Roles Building Effective and Balanced Teams for Success.
Dr Meridith Belbin developed the Belbin Team Roles Theory in the 1970s, based on how individuals perform in a team environment. ...
What came out of the experiment was that particular individuals gravitated towards certain roles when working in a team context.
Role balance within a team was found to be crucial to the positive and timely outcome of a task.
It is easy to see this in everyday life. When a team performs well, be it in sport, school, projects or general business, you can see that there is a degree of uniformity, whereby everyone knows what they are doing and how to do it.
Everything looks easy and well-structured and success typically flows through the team. ...
Belbin Team Roles can be split into three different behaviours:
- Action oriented
- People Oriented
- Thought Oriented
❶ People acting in teams.
Each function is associated with typical team work behaviour and interpersonal strengths and weaknesses.
The goal:
- manager: To pick a team that covers each team role to create balance and synergy.
- team member: To understand their Belbin team role and identify associated strengths and weaknesses, in order to improve and thus increase the performance of the team.
The Belbin roles in a figure:
See right side.
team diversity - roles II
The Belbin Team Roles are as follows:
- Action Oriented Roles:
- Shaper. The shaper challenges, is dynamic and thrives on pressure with the drive and courage to overcome obstacles.
The Shaper can also hurt the feelings of other team members through provocation.
- Completer or Completer Finisher. The Completer delivers on time is conscientious and anxious searching out errors and omissions in a project.
On the negative side the completer is inclined to worry unduly and is reluctant to delegate.
- Implementer. Discipline, reliability, efficiency and the ability to turn ideas into practical action are attributes of the Implementer.
Although; on the reverse side implementers can be inflexible and slow to respond to new opportunities.
- People Oriented Roles:
- Resource Investigator. This is an enthusiastic and extrovert character who is communicative with a particular skill in exploring opportunities and developing contacts.
Negative aspects being over optimistic and losing interest once the initial enthusiasm has passed.
- Coordinator. The coordinator is mature, confident and a good Chairperson who clarifies goals, delegates well and promotes consensus.
On the minus side, the coordinator can be manipulative.
- Team Worker. Team Workers are cooperative, mild mannered and perceptive. Good listening skills are possessed with the ability to build a calming environment.
Team Workers can also be indecisive in pressure situations and be easily influenced.
- Thought Oriented Roles:
- Plant. The plant was identified as the creative member of the team with an imaginative and uncommon approach to solving issues.
The reverse characteristics being that the Plant can ignore detail and be too preoccupied to effectively communicate with team members.
- Monitor Evaluator. Team members with this role are sober and strategic seeing all options and accurately judging situations.
The Monitor Evaluator can also lack the drive and ability to inspire others and be critical of them.
- Specialist. The Specialist is single minded and self-starting . This role provides the knowledge which is in short supply.
On the negative side the Specialist can only contribute narrowly to the team task.
Belbin team roles are a good indication; a great way to analyse the makeup of your team, but you should not use this model as set in stone. After all, we rarely live in a perfect world and what looks good on paper proves tricky to perfect in reality.
 ❷
❷
The Belbin roles align to the SIAR model supporting a full PDCA cycle, pull-push and 10 detailed steps.
In a figure:
See right side.
Another Belbin reference part of a training knowledge promotion:
Belbin Team Roles explained .
Competencies includes a vast array of skills, from IT expertise to an understanding of production methodologies.
This is what we call the 'task focus', the primary force behind accomplishing the job at hand.
This relates to how something collaborates within a group and boosts its overall efficacy.
❸ balancing the teams!
It's not just about getting the job done; it's about the process and the dynamics of how it's achieved.
⚖ W-2.4.2 The ignored Engineer executing everything
ViSM: some important principles
Aside the principles about variety in the system and velocity of the communication signals there are many more principles in
Viable System Model (Michael Frahm).
VSMB_SYST_05: A set of principles for behaviour.
❹ Principles:
- Black box principle: (not necessary to understand the inner workings)
- Understand how it performs
Example: You don't need to understand in detail how a car drives, but you do need to know how it reacts.
- Dealing with the variety it produces
Measuring complexity is not necessary.
Assessing quantities and the right matching are important.
The decisive factor is behavior and not primarily the inner workings of the system.
Complexity is deliberately ignored the focus is on the input output relationship or on relevant systems or relevant tasks.
- Darkness Principle: No system can be completely captured.
Systems are dynamic and change while you observe them.
This must be accepted residual uncertainty must be dealt with.
- Adam's 3rd law: It states that a system built from a series of components selected on the basis that they each represent the least risky option is exposed to higher overall risk.
- Agility theorem: In order to survive, the rate of change of the organization must be greater than or equal to the rate of change of the environment.
- Relaxation time principle: System stability is only possible if the relaxation time of the system is shorter than the mean time between disturbances.
- Example 1: An employee, team, department or organization is organized in such a way that a task cannot be completed "in order".
Accordingly, production planning must be improved and bottlenecks avoided.
- Example 2: Organizational change, stable performance is disrupted by change.
If changes are made too often, stability is never achieved.
- Principle of homeostasis: A system is stable if all its key variables remain within their physiological limits.
It is about self regulation, balance and ultra stability.
In the course of changes, it is about dissolving homeostasis..
VSMB_SYST_06: Theorem of recursive systems.
- Systems organize themselves as follows:
- Creation of a new, superordinate structure of a system from previously disjointed parts.
- Process of self organization within an existing system (subsystems disintegrate, form anew, change completely).
- Systems organize recursive:
If a viable system contains a viable system, then the organizational structure must be recursive.
Using the same organizational genetic code by applying the VSM, complexity is thus managed.
❺ The theorem states the solution should be similar, not that the problem is the same.
⚖ W-2.4.3 Mediation technology: functionality - functioning
VSM principles and balances
When discussing variety flows, we are qualitatively addressing the organization's ability to manage the ratio between disturbance variety and system reaction within each relationship.
It also pertains to the organization's capacity to cope with the inherent variety or com plexity.
❻ The change variety challenge.
To gain a deeper understanding of the VSM's dynamic perspective, consider these five significant variety balances:
- Workload
- Line balancing
- Autonomy vs. Cohesion
- Change Rate
- Change vs. Status Quo
ViSM: recognizing problematic patterns
Common failures are lessons to learn from.
Viable System Model (Michael Frahm).
The following is just a brief introduction to recurring problematic patterns, which are referred to as pathological archetypes and are suitable for identifying and communicating problems in systems through the viable system model:
❼ Examples of what to avoid and how to correct them:
- Fantasy World (system-4 to system 3,1 fail)
- Symptoms: Senior managers and senior executives make decisions without sound information.
Neither information from the organisations environment nor from the operational base is used as a source for decisions.
The perception of senior management differs greatly from reality.
In a way, these managers live in a fantasy world.
This can also be referred to as optmism bias.
-
Solution: Senior manage ment must be aware of Crow's Law, which states: "Don't believe what you want to believe until you know what you need to know."
Assumptions based on a fantasy world do not protect the decisions made and those responsible from reality.
Effective operational and strategic feedback loops, critical feedback and well founded observations and analyses are necessary to escape from the fantasy world and validate assumptions.
-
Frequency: Very frequent
- Control Dilemma (system-3 to external fail)
-
Symptoms: Rapid changes in the environment require a direct response from the operational systems.
Senior management notices unusual activities in the base and fears a loss of control.
It therefore demands additional reporting and issues more instructions.
The management of the operational systems now has to act on two fronts: on the one hand, to fulfill the increased requirements from the environment and, on the other, to meet the increased reporting requirements and instructions from senior management.
This means pressure from outside and pressure from within.
Senior management, on the other hand, neglects strategic activities because it wants to retain its supposed control over the operational systems.
By intervening, senior management also denies its subsystems the autonomy they need to deal with their challenges.
-
Solution: Control dilemma or micromanagement requires standardized and regular reporting that stands up to scrutiny by senior management and third parties.
This creates trust for both superiors and employees.
-
Frequency: Very common triggered by "bottle necks"
- Bottle Necks (system-3 with system-1 fail)
-
Symptoms: Classic symptoms are uncoordinated, unexpected or uncontrollable fluctuations in workload between the operational units and their environments.
See also the Beer Game, which Peter Senge (1990) from MIT has made a standard part of management training.
The archetype can be triggered by the control dilemma.
-
Solution: Adequate coordination mechanisms as well as bottleneck concentration, standardization and cooperative project management are effective levers for countering the archetype.
-
Frequency: Very common, triggers "control dilemma"
- Re-Inventing the Wheel (system-3 with system-1 fail)
-
Symptoms: In this archetype, no or insufficient standards are defined.
For example in large and complex projects or organisations with a large number of departments, this leads to the wheel being reinvented several times and there are many isolated solutions.
Due to the lack of standards and communication, unnecessary resources are used for activities already carried out in the subsystems and by senior management.
-
Solution: Uniform standards for implementation must be made binding.
Implementation must be checked by means of suitable monitoring.
The standards must be adapted to the unique requirements.
-
Frequency: Frequent The standards must be adapted to unique requirements.
- Bunker Mentality (system-as a whole with external)
-
Symptoms: The "bunker mentality" is a common problem when sudden events occur, e.g. crises.
The organization closes itself off and a bunker mentality prevails both within the organization and towards the environment.
Information and knowledge are neither exchanged nor accepted.
Isolation takes place in order to understand the situation, reduce the amount of incoming information and regain the illusion of control.
In a strategic context, this isolation is fatal for the organization.
-
Solution: With this archetype, there is no substitute for practice.
It is also said that "you emerge stronger from a crisis", which is indeed the case. Fortunately, many crises only happ en once.
You can increase resilience through an organizational culture of trust, transparency and a constructive error culture.
Nevertheless, an effective approach to dealing with crises is to use scenario exercises to prepare management teams for the emot ional and behavioral impact of dealing with crises.
-
Frequency: Very common
⚖ W-2.4.4 Interactions in the organic viable system
Power and the edge
Power to the Edge (David S. Alberts, Richard E. Hayes 2003)
The source is defence but mentioned is that is generic appplicable.
An organization's power is also a function of the power of its members and the nature of the interactions among those members.
Organizations realize their potential power by instantiating mission capability packages. ...
In a hierarchical organization, one with a topology organized by status and power, those at the top are at the center and those at the bottom are at the edge.
In addition, there is a significant portion of the organization in the middle.
Those at the top have the power to command, to set the direction for the organization, allocate its resources, and control the reward structure.
Information flows along the axes of power, hence these flows are vertical.
Information collected at the bottom flows vertically to the top, and directives flow vertically from the top to the bottom.
The middle is needed to deal with the practical limits on span of control.
❽ The question: is the classical hierarchical power C&C a fit for the "information age"?
The middle serves to mediate and interpret information flows in both directions, allocate resources, and delegate authority. ...
Worst of all, stovepipes result in cultural differences and tensions between and among different parts of the organization. ...
In the Industrial Age, stovepipes were necessary because the economics of information made it prohibitively costly to support widespread information sharing and peer-to-peer interactions. ...
The adverse affects of stovepipes often come to light as a result of a catastrophic failure. ...
The only way to ensure that information will be shared and that individuals and organizations will work together appropriately is to move power to the edge.
(page 173- 176)
Beyond individuals, beyond hierarchical Command & Control
The challenge of a problem without any lead in command.
The puzzles were meant to be so demanding that no individual could possibly complete them all.
But immediately after the discovery of the game on the Web, teams of curious players developed organically across the country.
Working together, their combined knowledge allowed them to complete the first 3 months' worth of game content in only 1 day.
These teams excelled at solving problems, and they could do so at surprising speeds.
However, learning the work processes associated with information sharing, exploiting collective knowledge, and conducting the efficient, authoritative collaboration will require establishing new mind sets (education and training) as well as new tools.
❾ The question: How to change the classical hierarchical power C&Control?
Without being able to fall back on traditional approaches to strategic planning, without being able to rely on intuition, from where does leadership and direction now come?
The answer for industry is the same as for the military; constantly dealing with unfamiliar situations places a premium on agility in all of its dimensions.
The approach to developing the agile organization, the Information Age approach to command and control presented in this book, is based on the application of power to the edge principles.
This enables an enterprise to bring all of its available information and its brain power to bear by allowing information to be recombined in untold ways and by allowing individuals to interact in unplanned ways to create understandings and options not previously possible. ...
Four minimum essential capabilities are required for a given operation:
- The ability to make sense of the situation;
- The ability to work in a coalition environment including nonmilitary (interagency, international organizations and private industry, as well as contractor personnel) partners;
- Possession of the appropriate means to respond; and
- The ability to orchestrate the means to respond in a timely manner.
Three of these four essential capabilities involve command and control.
The third is about the tools of war and policy implementation.
(page 90-98)
Power to the edge
Power to the edge involves changes in the way we think about the value of entities and desirable behaviors and interactions.
Ultimately, this involves a redefinition of self and the relationship between self and others, and self and the enterprise.
Thus, in order to move power to the edge, we need to do more than redraw an organization chart; we also need to change what is valued and the way individuals think and behave.
We need to rethink the way the enterprise is motivated and led.
We need to revamp processes and the systems that support these processes. We need to reeducate and retrain. ...
The concept of adaptability (changes in organization and work processes) is a crucial element of agility.
❿ The question: is the classical hierarchical power C&C a fit for the "information age"?
However, it directly contradicts Industrial Age solutions of complexity, decomposition, deconfliction, specialization, and optimization. ...
However, a network topology alone will not achieve the desired result; it does not create the conditions necessary to achieve productive self-synchronization.
To complete the package, a suitable approach to command and control must be developed to leverage the capabilities provided by a robustly connected network topology.
(page 181- 186)

W-2.5 Sound underpinned anatomy of a viable system
Understanding the position, situation by understanding the system.
❗Aspect:
Information, types of association relations:
- Art of the role by follow up interactions
- Kind of task in the process by role
- Art of the role by observed input and results
A viable system is non trivial, it will be repeated in structures in every layer.
Conscious lead of a system needs only the information for what is relevant for understanding what is going on.
Using the knowledge of the anatomy enables to limit the set of information flow for improvements.
⚖ W-2.5.1 Fundaments of activities processes (0-1-2, 4-5)
The enterpise organisation, viable system model
👁 Industrial age: the manager knows everything, workers are resources similar to machines.
👁 Information age, required change: a shift to distributed knowledge, power to the edges.
A viable system according
Stafford Beer ViSM
- System-1 all of the basic, primary operations of the organisation, which justify the existence of the system as a whole.
The elementary 0-1 floor level is and 1-2, are mostly system-1.
➡ The floor 01 vs 1-2 differences:
- Floor 0-1 is missing internal activities at the corners.
Only reacting on external influence for the good bad and ugly.
- Floor 1-2 is the full cycle of a value stream (product: good, service).
Mostly acting conformin internal set guidelines for the good bad and ugly.
- System-2 represents all of the communication channels and communication methods.
- Gray areas (centres) are system-2: very short time, term communications.
- The blue areas are shared to other systems: medium time, term communications.
- Vertical en horizontal lines: long time, term communications.
- System-3 represents all of the structures that are the broad view of all the operations active within the first systems.
Activities, roles at floor 2-3 is mostly system-3.
The results are guidelines, instructions for the others that enables everyday control for their processes.
❗ Combining system-3 with system-1, mixing up floor 2-3 and floor 1-2 will result in conflicts by conflicting interests, conflicting type of specialisms.
- System-4 floor 3-4, responsible for looking externally from the organisation or overall system, at the environment in which it operates, and establishing which factors may impact operations, and how it needs to adapt in order to remain viable and sustainable.
- System-5 is the Organisation Policy, Ethos, encompassing all decisions within the organisation.
Floor 4-5 as a virtual floor position in the virtualisation of a viable system.
❗ This system should always be maintained as separate from the System 3 control.
Added to the usual viable system model is:
- system-1: differention in types of primary activities
- system-2: differention in speed of communication
- system-5: abandoning the ivory tower, shifting power to the edges
The enterpise organisation, system-5 executives
When the product service is what is about, the CPO (Chief Product Officer) has a pivotal role.
An abstracted proposal for a structure:
- CFO Chief Finance officer, CDO Chief Data officer, CEO Chief executive officer
- CAIO Chief Analytics & intelligence officer, CPO , CTO Chief technology officer
- FM/HR Facilities and Humanity, CSO Chief Safety officer, CRO Chief risk officer
All of them are universal exchangeable to other type of enterprise.
Positions within the green areas are changed when the context is changed between operational or change, innovation.
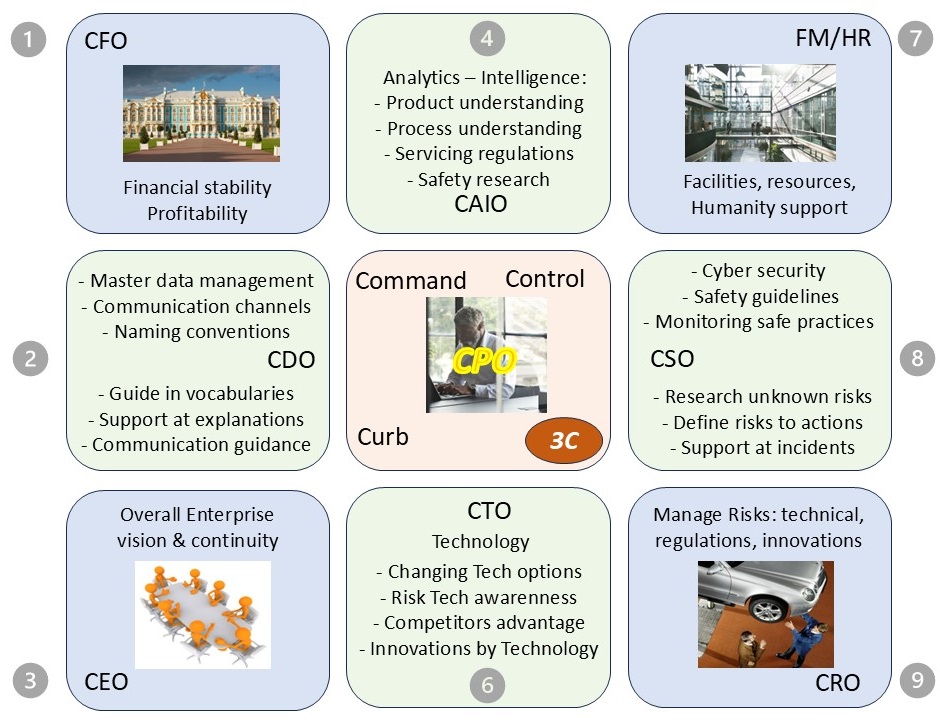
Top-down theoretical view:
Figure, see right side
The enterprise organisation, system-5 executions
When the product service is what is about, the CPO (Chief Product Officer) has a pivotal role.
A CPO is also accountable responsible for the coordination at the floor, empowering people.
An abstracted proposal for a structure:
- Product Manager, Sales Manger, Quality control
- Safety analyst, -, Business Analyst
- Account Manager, Water Stride, Cyber defence, Safety
All of them are universal exchangeable to other type of enterprise.
Positions within the green areas are changed when the context is changed between operational or change, innovation.
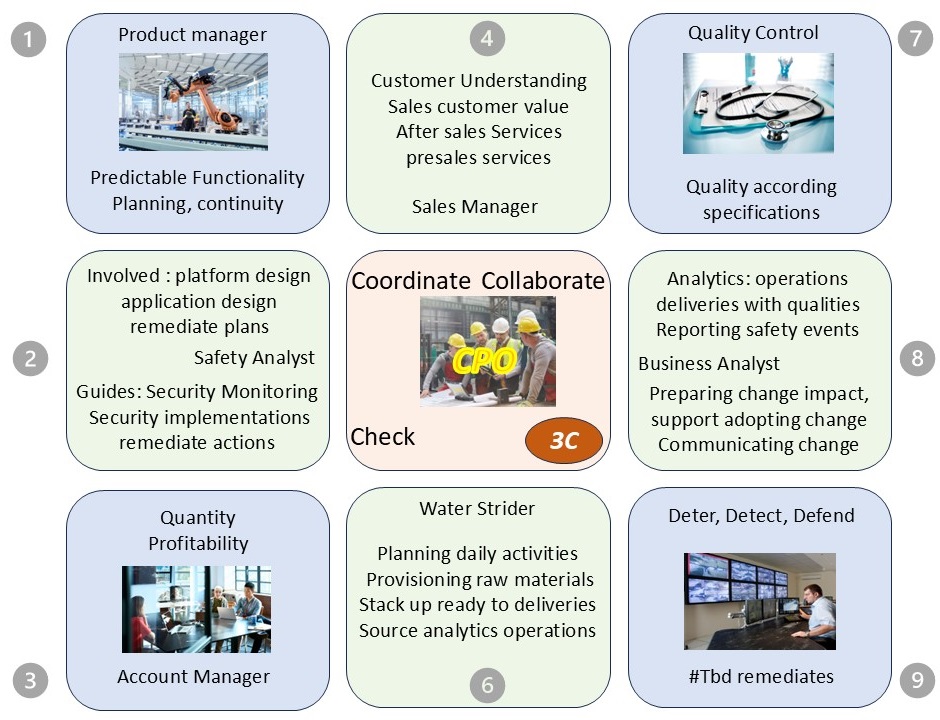
Bottom-up practical view:
Figure, see right side
SIMF the foundation floor 0-1
Some peculiar interesting attention points:
- Vision, missions: are what executives build and maintain as foundation for the whole.
In a very small enterprise just having this floor it is still indispensable.
- Technology operations: representation does not not have a logical leader at floor 0-1.
In a very small enterprise this will not be an issue.
When there is growth into an organised values stream flow the questions arise what to do.
🤔 Being an indispensable part of the value stream floor 1-2, it is combined to the operations area in the value stream.
- Support organisation: enabling capabilities, will become a question when the organisation becomes that big, it has become important dedicate tasks.
🤔 Combining it with the long term time planning at floor 1-2 is the most logical choice.
- Supporting operations: executing capabilities, will become a question when the variety and complexity for products, services becomes that big, it has become important dedicate roles with tasks.
🤔 Combining it with the long term time planning at floor 1-2 is the most logical choice.
In a figure:
⚖ W-2.5.2 Operational deliveries, functioning portfolio (1-2)
SIMF the value stream in information processing
A full complete generic value stream flow in a cycle with a pull-push.
Some peculiar interesting attention points:
- There are three area's with planning:
- Long term:
- What products: goods, services are in scope in quality quantity (processes)
- Expectations what can be processed for products: goods, services (machines)
- What is the needed staff for all activities (people)
- Medium term: "prepare picking", what is getting processed.
- Short term: "execute packaging", what is getting to delivered.
- Two area's with coordination, assuring the completeness of planning:
- Supplier oriented at the backend.
- Consumer oriented at the frontend.
- There is a V-shape for the planning and coordination task at a whole.
- There are three areas intensive activities (circles):
- Consumer, Customer oriented for the products: goods, services.
- products goods, services oriented oriented for the purposes values.
- Operations process oriented creating the products, executing the services.
In a figure:
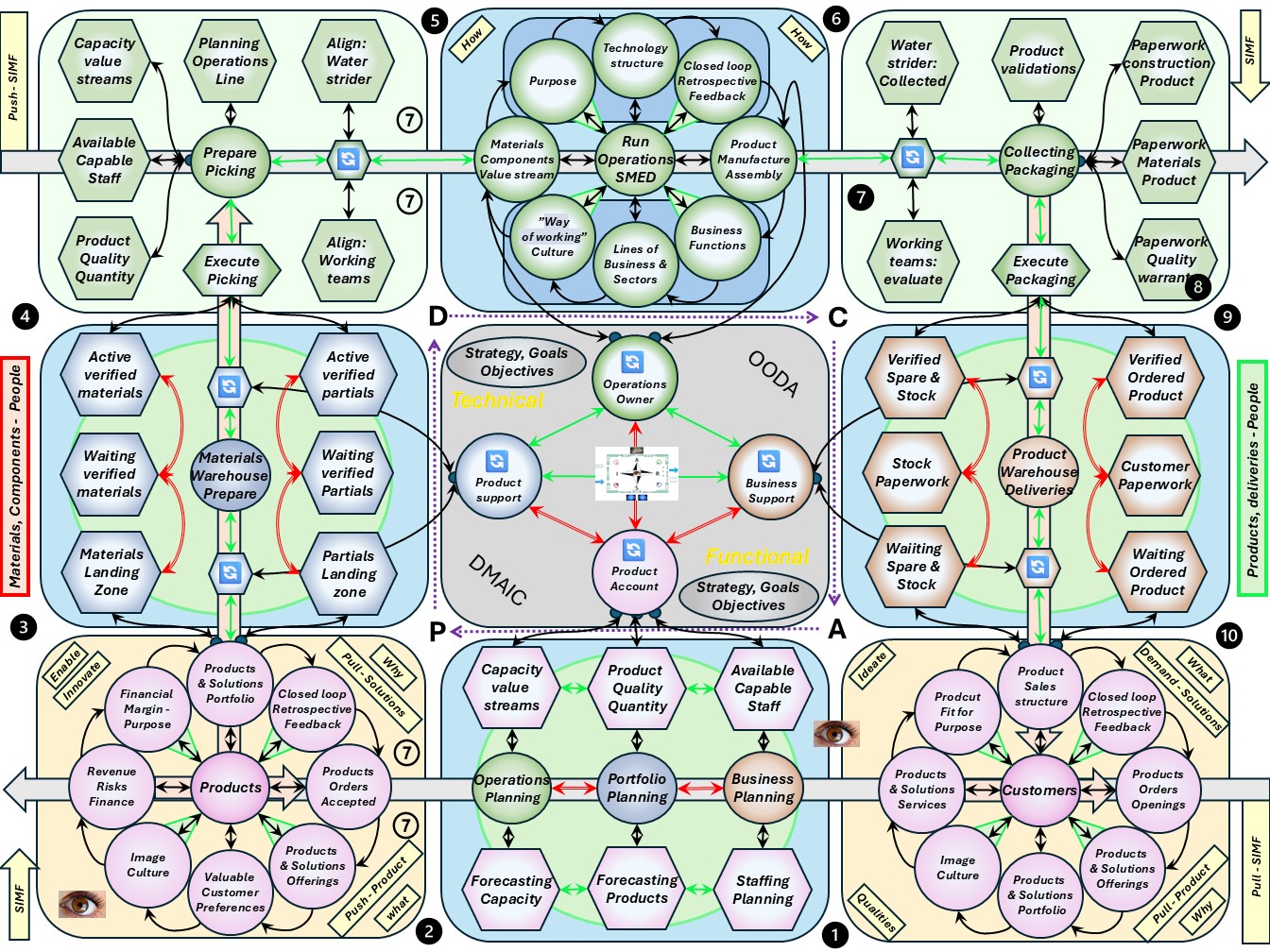
⚖ W-2.5.3 Changing products, services, functionality portfolio (2-3)
SIMF changing the vale stream
A full complete approach for creating & changing value streams in managed suggestions, backlog for requirements in a cycle with a pull-push.
This is a segregated from system-4 and
Some peculiar interesting attention points:
- There are three areas intensive activities:
- portfolio management: Aligning the missions for realisations by suggestions, wishes and specifications for all products. (horizontal orange areas)
- program management: coordination of the lifecycle of products adding and validating requirements. (horizontal blue areas)
- project management: coordination of partial stages in the lifecycle of products, completing and validating requirements. (horizontal green areas)
- There is a reversed (upside down) V-shape for the planning and coordination task at a whole.
- There are three V-shapes for:
- Engineering type: design, build validate the product.
- Compliance design type: narrowing down to what is needed at what level in the product.
- Compliance validation type: narrowing down the level specified into specifications.
In a figure:
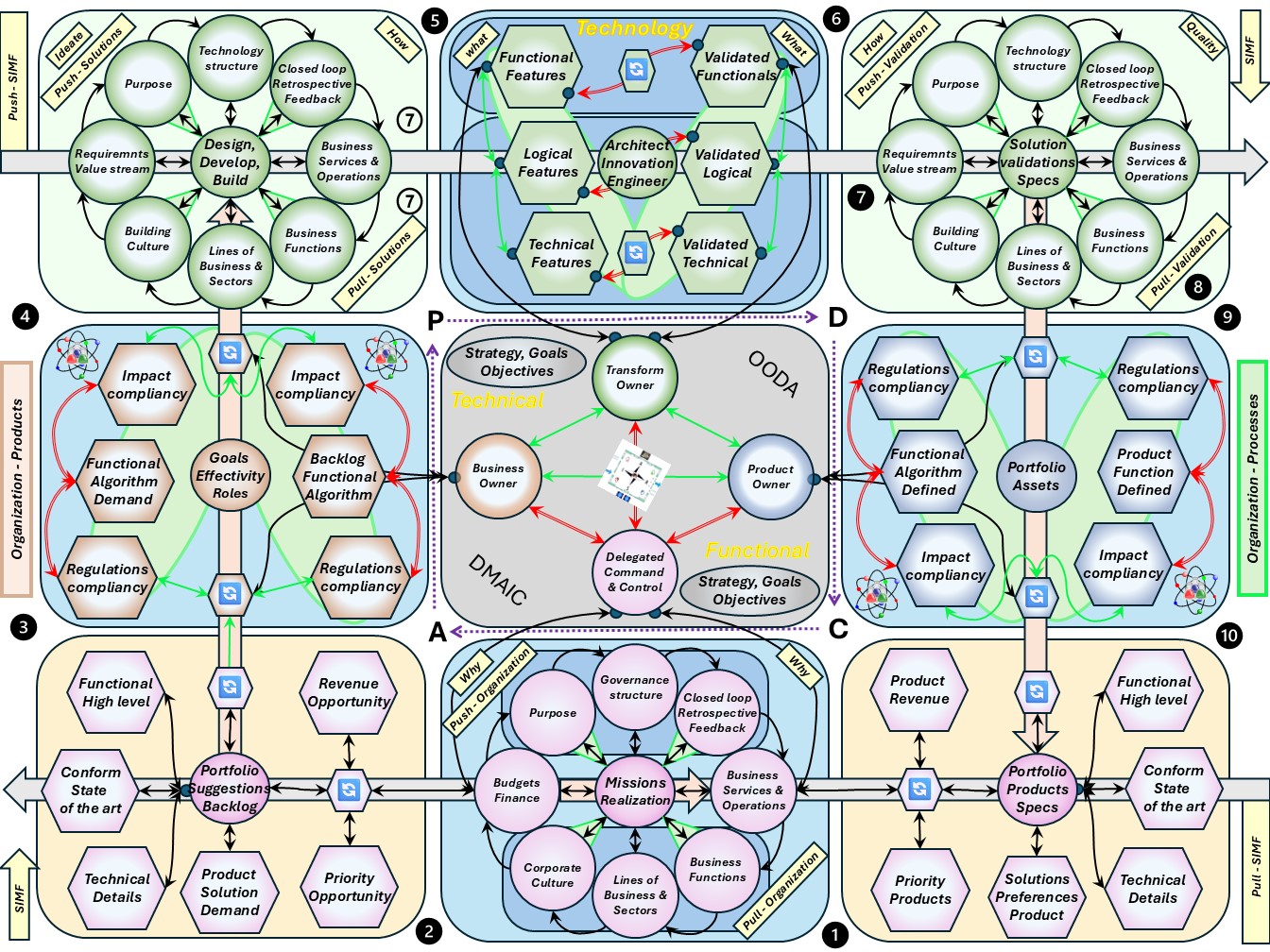
⚖ W-2.5.4 Autonomic compliancy control & conscious decisions (3-4)
SIMF The organisation as a whole: ambiguity at the same horizontal plane.
⌛ ⏳ When C&C gets more mature there are options in proactive starting activities by risk evaluated changes (system-4).
What gets attention and what gets ignored is the identity, ethos, ground rules.
These should be an indispensable part of the vision.
The technical peculiar interesting attention points:
- The central nerve system, grey area.
- A plane with coordination, assuring knowledge related to the product (good, service) in the external environment want the internal relationships in the horizontal blue areas.
- Another coordination plane in the vertical blue areas:
- The organisation with an executive decisive point
- The areas supporting the additional (secondary) tasks, processes.
- The technology with supporting SMED (Single Minute Exchange of Dies)
- autonomous parts that can interact by alerts and others signals.
- There are four areas with sensors to the external environment and much autonomy in activities:
- Consumer oriented: innovate, align the internal organisation, innovate and align the portfolio, products.
- Internal organisation oriented: safety impact vs stability and stability of the organisational by e.g. good financial stability and legal compliancy.
- Internal technology services oriented: technology stability and continuity.
- Product (good, service) quality quantity an given service. More specific: information quality, explainability, accountability.
In a figure:
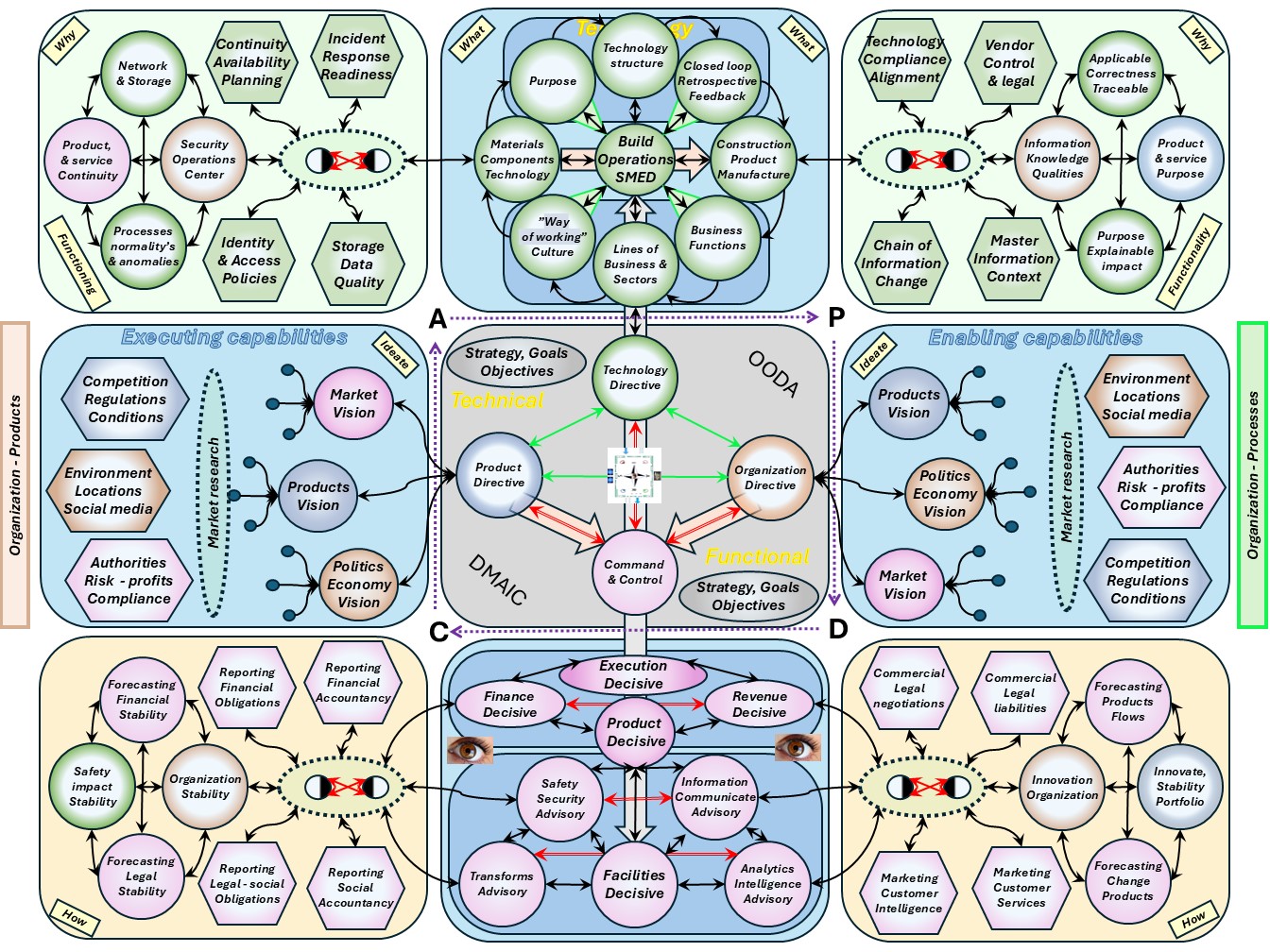
Why there is that much ambiguity at this level?
- dimension-1:Acting as a system-3 connected to a higher system system-4.
The planes:
- People: Organisation (orange) System-3 the counterpart
- Processes: Communication (blue / grey ) System-2
- Machines: Technology (green) System-1
- dimension-2: Each floor level has two viable systems that should cooperate well.
The difference between those is: functionality and functioning. Both sides restart with their own scoped system-5. Both sides are helped wiht a system-1 and system-4.
- dimension-3: Each plane by itself is a viable system, the systems-5 of a floor in the middle.
The organisations start as a system-1, the technology with a system-5.
W-2.6 Maturity 3: Enable strategy to operations
From theoretical to practical needing the collaboration.
❗Aspect:
Purpose, value, interrelated areas in scopes:
- ✅ P - processes & information
- ✅ P - People Organization optimization
- ❌ T - Tools, Infrastructure
Only having the focus on others by Command and Control is not complete understanding of all laysers, not what Comand & Control should be.
Each layer has his own dedicated characteristics.
⚖ W-2.6.1 SIMF-VSM Safety with Technology at Technology
How to act in a situation, plan driven vs goal driven
When to choose a plan or a goal,
Agile Cynefin
I believe the simplest explanation of Agile has its roots in military warfare.
Understanding Agile begins with understanding friction and how it affects our plans, actions and results. ...
Why does this matter?
Well, the level of friction we face determines the amount of surprises and the extent to which we can rely on planning and prediction.
When what we’re doing is Clear or Complicated, plan-driven approaches work well.
Clear or complicated, is what I have labelled as: trivial.
A plan driven approach will work but is an overkill for the clear situation.
When plan-driven approaches work, where we can plan and predict while leaving the goal implicit and embedded in our plans, then we don't need Agile approaches.

Those, complex or chaotic, is what I have labelled as: non-trivial.
It is important to don't get lost in confusion.
When we want to people to do what is expected of them, let them define the plans and actions, and report them back to the higher levels.
When our actions don't pan out as expected, let the people that do the work adjust plans and actions as necessary in line with the intent of the original plan. ...
When we can't adequately plan and predict to achieve the desired results, we should switch towards goal-driven approaches.
We should start with humble plans that are adjusted as we learn and discover what’s necessary while we do the work.
Why does it matter?
In complex systems there exists algedonic channels and transducers.
Principles: Safety with Technology at Technology
There is a lot of autonomy expected from the technical perspective by the organisation.
Too often ignored or only poorly getting some attention are the expectations for the organisation by technology.
A categorized list for Safety Technology at Technology SaTT :
- SIMF_SATS_01: An open algedonic channel between the organisation and SaTT.
- Rationale:
- Any impact on the system as a whole matters the system as a whole
- A fast immediate response requires fluent trained cooperation
- There must be a CapCom Technology role for enabling the fast reactions
- Implications:
- Accountability at the organisation. GDPR: Data controller
- Responsibility at the technology: GDPR: Data processor
- SIMF_SATS_02: Alignment of the organisation and SaTT for scopes in core technology.
- Rationale:
- Any impact on the system as a whole matters the system as a whole
- Every organisation has to go through the mandatory alignment for all their details.
- Every organisation is required to maintain the alignment for all on going internal and external changes.
- Implications:
- The variety: Organisations are not the same although they share a lot.
- All channel types (1-6) are used for achieving an alignment.
- The complexity: every channel can act on his own speed own type of regulators.
- SIMF_SATS_03: Alignment details SaTT for: People, Processes, Machines and Structure.
- Rationale:
- Any impact on the system as a whole matters the system as a whole
- Regulations are mentioning explicit CIA:
- People ⇄ Confidentiality,
- Processes ⇆ Integrity,
- Machines ⇄ Availability
- Regulations are mentioning structure by:
- Segmentation in the three CIA topics, internal and external
- Supplier management, e.g. required safety at their side
- Physical spaces, e.g. controlled monitored access
- Communications spaces, e.g. clean desk policy.
- Implications:
- There are a lot of attentions point to fulfil.
- There is a lot of mandatory administration related to products.
⚖ W-2.6.2 SIMF-VSM Uncertainties imperfections at processes, persons
Two-valued logic and liveliness
Viable systems and Polycontextual Logic (PCL),
"The Viable System Model as a transclassical organizational model" ( PKL VSM Conny Dethloff 2017)
I was asked to explore and describe the similarities between Stafford Beer’s Viable System Model (VSM) and Gotthard Gunther's Polycontextual Logic (PCL).
My suspicion of some similarities was certainly there, since the VSM is a model for liveliness and the PKL is a formal language for modeling liveliness.
The PCL, designed by Gotthard Günther, represents a formal theory that makes it possible to model complex, self-referential processes that are characteristic of all life processes in a non-reductionist and logically consistent manner.
The problem at modelling human actions:
- Two-valued logic excludes contradictions and therefore liveliness.
- It is not possible to model human actions on the basis of this logic, or only with great caution, since people have to be trivialized to apply two-valued logic to them.
- This trivialization often occurs without reflection, as it occurs within the framework of two-valued logic.
This is why this fact of trivialization is so dangerous.
Please do not confuse this with multi-valued logic.
 The PCL includes the person making the statement and does not just deal with the statement itself.
That's why this logic is often called multi-digit or location-dependent logic.
Often, "place" is used instead of "location".
It therefore addresses where someone is standing who is making a statement.
Each person making a statement makes their statement on the basis of two-valued logic.
The PCL includes the person making the statement and does not just deal with the statement itself.
That's why this logic is often called multi-digit or location-dependent logic.
Often, "place" is used instead of "location".
It therefore addresses where someone is standing who is making a statement.
Each person making a statement makes their statement on the basis of two-valued logic.
Now here comes the trick.
- These statements are mediated with each other.
- This means that a quasi-objectification between different subjectivities is created within the logic framework.
- It is precisely this fact that the VSM uses to mediate between individual viable systems.
 With two-valued logic, this quasi-objectification is created outside the logic framework because this framework does not know any mediation.
Only when this mediation has been done, for example in values of "yes", "no", "maybe", etc., can the logic be applied. ...
With two-valued logic, this quasi-objectification is created outside the logic framework because this framework does not know any mediation.
Only when this mediation has been done, for example in values of "yes", "no", "maybe", etc., can the logic be applied. ...
The clue, novelty of VSM is not the individual systems 1 to 5, but the reflexive, interrelated structure between the individual systems. ...
We humans are capable of acting polycontextually because we are alive.
However, since we are not able to model this ability in the classic sense.
As a result, people in binary systems are always caught "between the devil and the deep blue sea".
Dichotomous poles:
- no defined processes vs defined processes and present vs. future
- Specialists vs. Generalists functional vs. procedural
- Strategy vs. Operational and innovation vs. optimization
- Planbarkeit vs. Überraschung and Errors, failures vs. quality compliance
- etc.
There must be no hierarchy and therefore no priority between these pairs of values.
They must be treated equally, but this is not possible in the classic models.
Why does it matter?
Because the real world is full of uncertainties imperfections we should not ignore that in our models and assumptions.
When we ignore that will create bad systems with undesired behaviour.
Principles for information procseeing as a vaiable system (VSM)
dichotomies, uncertainties for inputs and results
These two are the drivers for a lost of issues when not managed well.
misunderstdrviing aT. alendrivers in informa
- SIMF_DUIR_01: The dichotmy Functionality vs. functioning is intangible part of an information viable system,
- Rationale:
- The dichotomy: Functionality, politics, authority vs. functioning, implementation, fulfilment is fundamental in an information system.
- The dichotomy results into intanglible subsystems:
- System-3 What: The organisation, synergy for a: goal - purpose
- System-1 How: Technology that will enable the organisation achieving their goals, purpose.
- System-2 Where: Communication, Mediation is needed to align the activities by the the other subsystems.
The system perspectives for this are from a division delivering a product perspective.
The vision and mission is known and the activities for that planned.
- Implications:
- Ordering Communication, Technology is a question of what was first in time:
- When technology is split of from the organisation than the quest for communication, mediation will grow and is created after the split.
- When analysing a system starting at the organisation the communication, mediation, is the path to find the technology connection.
- SIMF_DUIR_02: There is a balanced acceptance of imperfection & uncertainties
- Rationale:
For the product (good, service).
- A good as product can only be measured equal in conformity within uncertainties of measurements.
- A service as product can never be exactly the same due to all variations in the service and consumer.
- Implications:
- Accepting the imperfection will show the need for:
- A safe state situation for outcomes that are disputed by the parties.
- A correction path for outcomes that have been found evaluated to be unwanted.
- Acceptance that not all situations with a result are equal for the processing neither in equal outcomes and equal impact.
⚖ W-2.6.3 Dichotomy: generic approaches vs local in house

Product-based vs Project-based
A project managers perspective by a nice cycle in the same orientation that is used following the SIAR model.
- The flow from briefing to delivery left to right
- The idea at the bottom, Operational realisation: at the top
- Enabling, bottom left. Quality: delivering in time, top right
- Ideate question bottom right. Design activities: top left
The post attention was for the image, agility for projects:
Topic:
Project Manager in a Product Based Company?
- Product-Based:
- Focus: Long-term product development 👁 aligned with a roadmap.
- Stakeholders: Internal teams & end-users.
- Approach: Iterative delivery (Agile) 👁 evolves with the product lifecycle.
- Success: Product adoption & customer satisfaction.
- Project-Based:
- Focus: Delivering one-off client projects with defined goals.
- Stakeholders: External clients.
- Approach: Fixed timelines (Waterfall/Hybrid).
- Success: On-time delivery & client satisfaction.
Key difference: Product-based PMs work on roadmap-driven initiatives, while project-based PMs focus on client-specific solutions.
Team member balancing the construction of a system
The Belbin figure is adjusted in the related paragraph (W-2.4.1). Goal: fit into the SIAR orientation and directions.
Communication between persons in a system will impact the system.
Details on topics that made in the paste
Data information chain links:

Master data links:


Dichotomy: generic approaches that are insufficient secure and special local builds to get it secure.
personal frustrations resulted in some local builds.
Examples using SAS, code:
| Source | Description |
| xkeypsw | Using a manageable Password vault without needing obscurity. |
| xgetsetpsw | Synchronise account stored obfuscated. |
| xmetadirlst | Obfuscated definitons reading to visible usable syntax. |
| (no code) | failing home dir definition, missing saswork, wrong pwd, java /tmp
correcting run time settings. |
| (no code) | Dictionary database processing synchronise (users/rights). |
⚖ W-2.6.4 SIMF-VSM Multidemensional perspectives & revised context
Principles: dichotomies, uncertainties for inputs and results
Information Technology Communication Structured Processing (ITCSP):
- SIMF_SYST_01: ITCSP is a subcategory of viable systems.VSMB_SYST_*
- SIMF_SYST_02: ITCSP adds:
- see: SIMF_DUIR_01: the dichotomy with the two competing subsystems
- see: SIMF_DUIR_02: managed with uncertainties for uncertainties "
- SIMF_SYST_03: There is well defined way of changing, shaping processes practices
Well defined is eg the use of USM. Two types of changes:
- SIMF_CHNG_01: Using and coorecting the product (good, service) reactive.
- SIMF_CHNG_02: Changing adjusting the product (good, service) proactive.
- SIMF_SYST_04: There is a secure information management in place:
- Secure, safe technology usage within the technology plane.
see: SIMF-SATS01, SIMF-SATS02, SIMF-SATS03
- Secure, safe information usage within the technology plane.
see: SIMF-SATS04, SIMF-SATS05, SIMF-SATS06
- SIMF_SYST_05: ITCSP support "information technology" at products (goods, services):
- SIMF_EXEC_01: common available technoloyg, knowledge in usage (reactive).
- SIMF_EXEC_02: innovative usage of available technology for distinctive products.
- SIMF_SYST_06: Solving the dichotomy in secondary but indispensable processes.
- see "SIMF_DSEC_01" for legal obligations e.g. finance.
- see "SIMF_DSEC_02" for market alignmet e.g. customer intelligence.
SIMF ViSM: the VSM connection
The three dimensional perspectives wiht a prodcut oriented mindset (green) and a service oriented one (magenta).
The system-4 and system-5 on top that is repeated at the bottom. Three system-1 constructs form the highest perspective.
- 1d design & change the products (good, service)
- 1r operations & run the products (good, service)
- 1i maintain the internal cohesion guided by vision
Functional perspective in a figure:
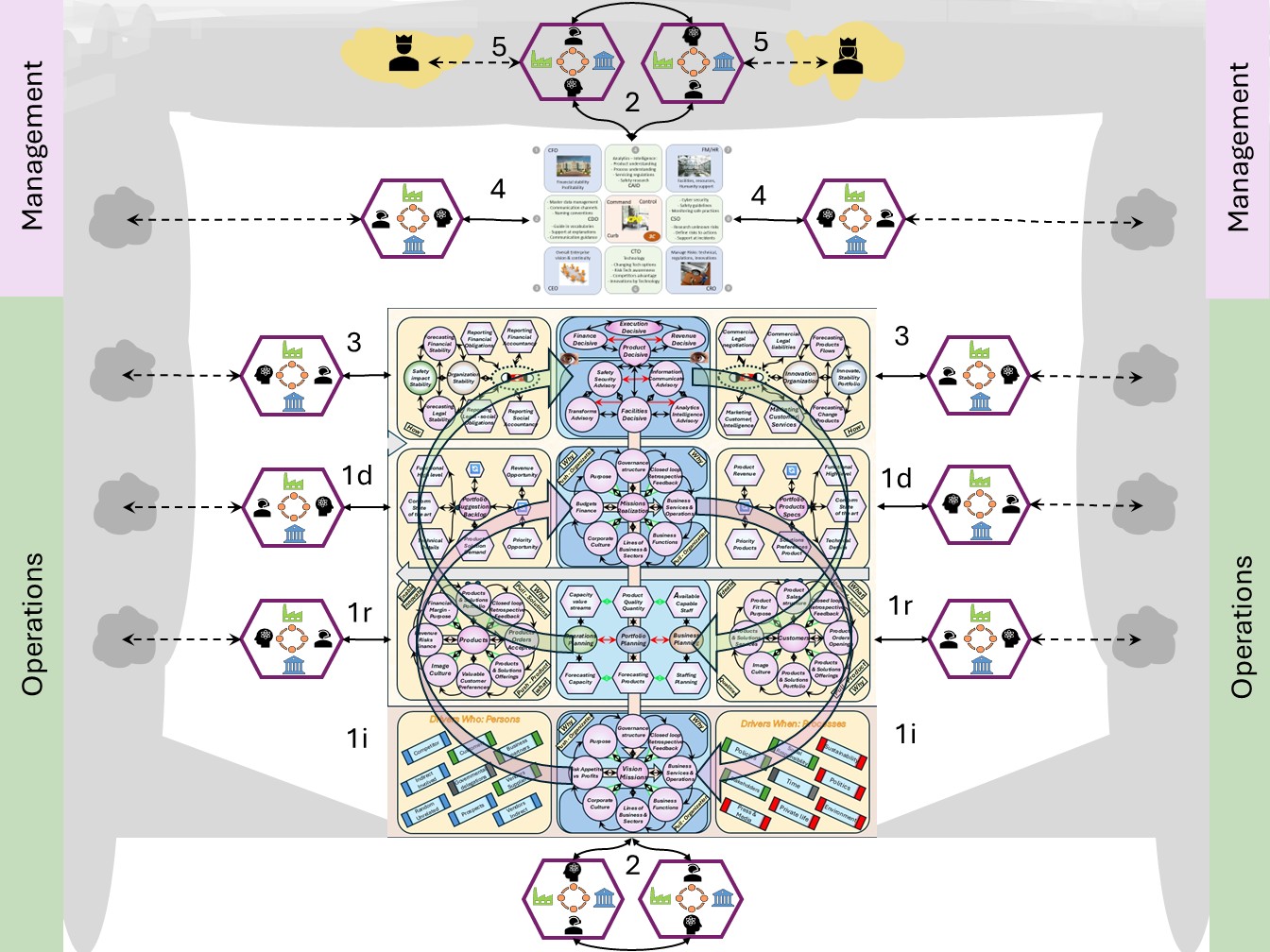
Technical perspective in a figure:
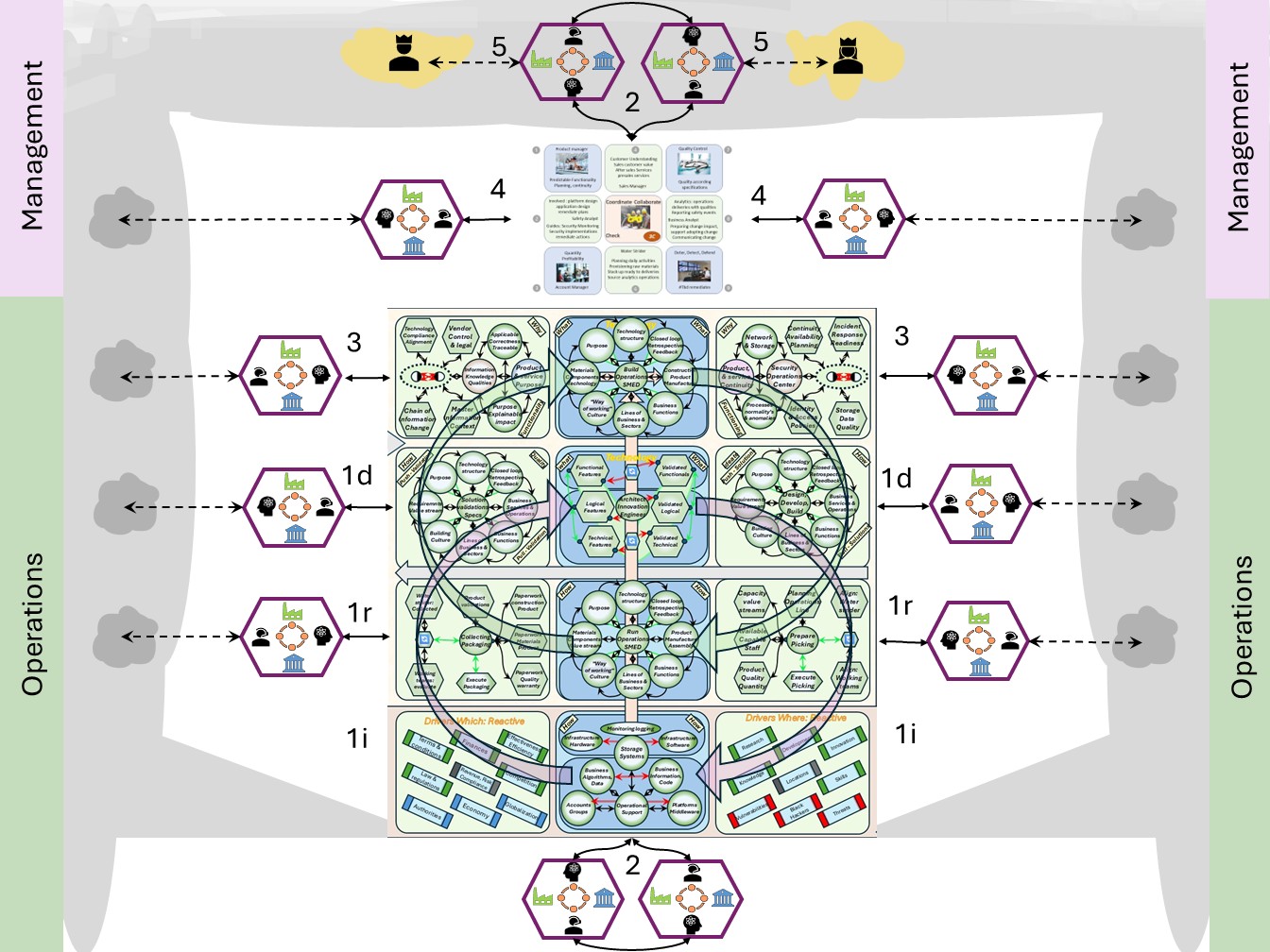
SIMF ViSM Extending complexity variety at floor (3-4).
Both the technology and organisation have dualities dichtomies at their system-1 and system-5 in
dimension-2 there is a recursion for the system.
For the two safety, security options:
- dimension-4:starting at floor 3-4 organisation execution decisive, product decisive as system-5.
The lines:
- Crossing over to the central technology now a system-4
- The context switch to either the technical or functional area now a system-3.
- Operational activities (system-1) both sides. Cooperation needed for the shared goal.
All the detailed activities to get reported to the highest chief in command is a mission impossible for understandable Command&Control.
Limiting the information loop-back for managing a system appropriate is the real challenge.
W-3 Command & Control planning for innovations

W-3.1 Information processing in the information age
Information processing, administration using machines tools is a rather novelty for mankind.
Status:
- Became commodity for work flows in the 1990-s.
- Hypes based on tools technology, not the purpose.
- Focus internal organisational, not the customer.
Exceptions are successful organisation everyone wants to copy.
👉🏾
Preach: set the purpose, customer central.
✅ When the service for a customer is the core value dot it in a effective efficient way: no overburdening, no unnecessary complexity.
⚖ W-3.1.1 Master data, understanding information
Master data - Naming artefacts
Naming conventions, when done correctly, are narrowing down a complex environment into many smaller, less complex environments.
Reference patteren: book library has a fine tuned labelling (naming) convention to be able to find and store a huge number of books.

For a information system is needed:
- Life Cycle indications on any component
- Unique business process lines
- Classification business artefacts (technical)
- Classification technical artefacts (tools)
- Hierarchy in: technical, administrative and monitoring
- Decoupling and connection to other business processes
A proposal for a naming convention see:
👓 details
The intention is to bring this into an operational environment.
Important is the segregation of the tool from the business process.
Master data: on premise vs a bought solution
When the problem to solve is a standard well known one there would be a good chance there is commercial software available for that.
Building and maintaining once for many is usually cheaper and giving more functionality than building it yourself.
There is no way out in avoiding responsibility for the own organisation.
💣 There are many cases there is not a usable standard in place.
Requesting data - communicating what is going on
An approach in defining similar to the pull question is defining the data lineage as a value stream.
The request for interactions of information starts with the following questions:
- What information is needed
- Who should deliver the information
- When is the information needed
See see:
👓 details
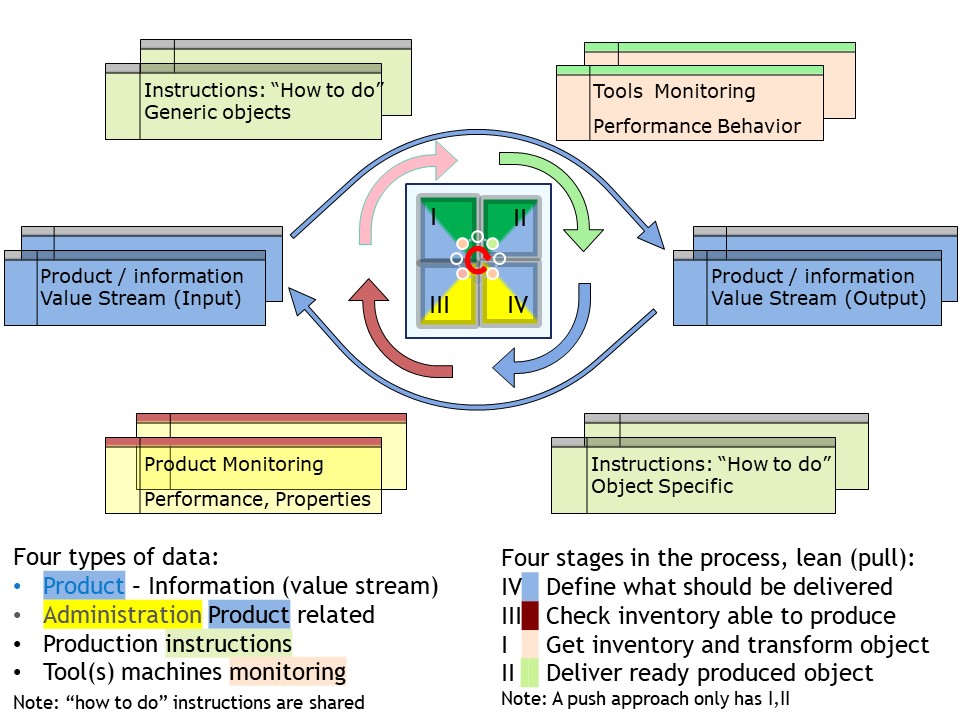
Starting at: IV
goes to III
(pull demand)
proceeeding to:
I and II
(push delivery).
in a figure:
see left side.
⚖ W-3.1.2 Volatile master metadata and information chains
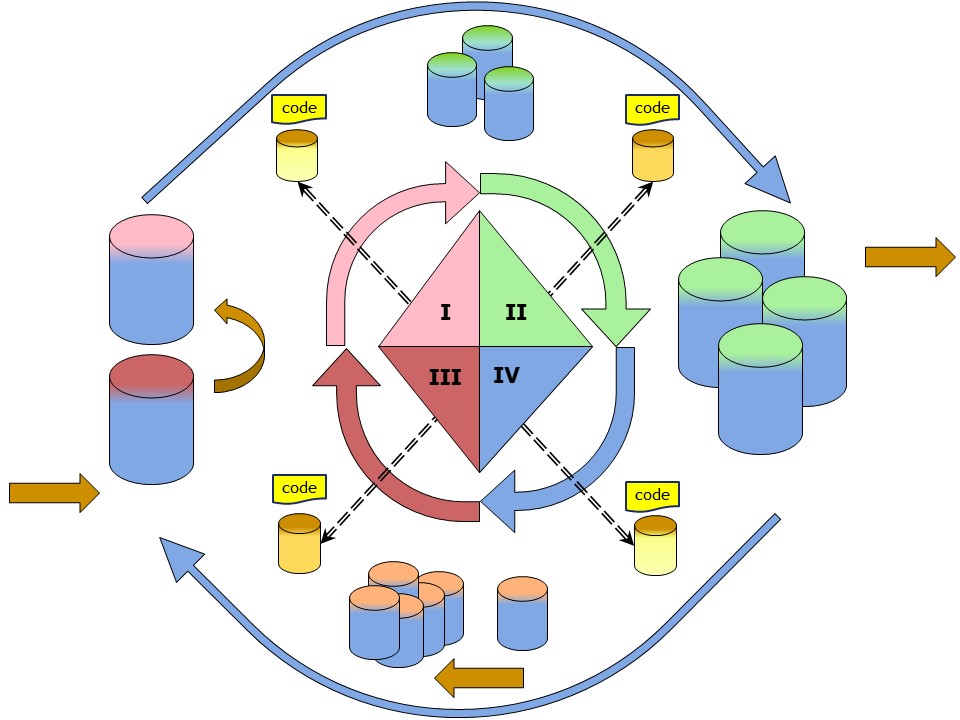
A volatile private metadata approach
The challenge is how to manage the metadata when the data, information, doesn't follow the well known solutions.
Describing the problem, requirements exchanging information:
- A single object for the interaction.
- Support for complexity aside the obvious.
- Support for variety and variability, time related.
- Quickly easy processing at the agreed intervals.
- Support for trend analyses for longer periods.
This can be a bought solution, pitiful that is only available when the situations are obvious.
Using a spreadsheet (Excel) is a simplistic way that could also be very advanced.
Technical details for this idea:
- One worksheet having a table collecting the required information from other worksheets (protected).
The table is defining elements by a name and their content value (string or numeric).
This table has just three columns.
- Several other worksheets in spreadsheet act as gathering requested input.
Validating the integrity and consistency for selected elements.
- Retrieving the spreadsheet table in an organised vertical.
Building a basic history on what has delivered by requested sources
- Converting the temporal indicators, version indicators to current valid values, organised with current valid data-time indicators.
- Transposing the vertical adjusted elements to more practical column oriented tables.
- Adding additional computations on transposed elements.
There are many other often used approaches, most of them are using a fixed data-structures very difficult to change.
Defining the elements dynamically for a request avoids that change limitation.
See for more
👓 details
The volatile chain of information
Information is not:
- A complete single artifact. It is composed by many partial components in interactions.
- An artifact stabel in time. It is changing in content by time and location.
Just an attempt to visualize:
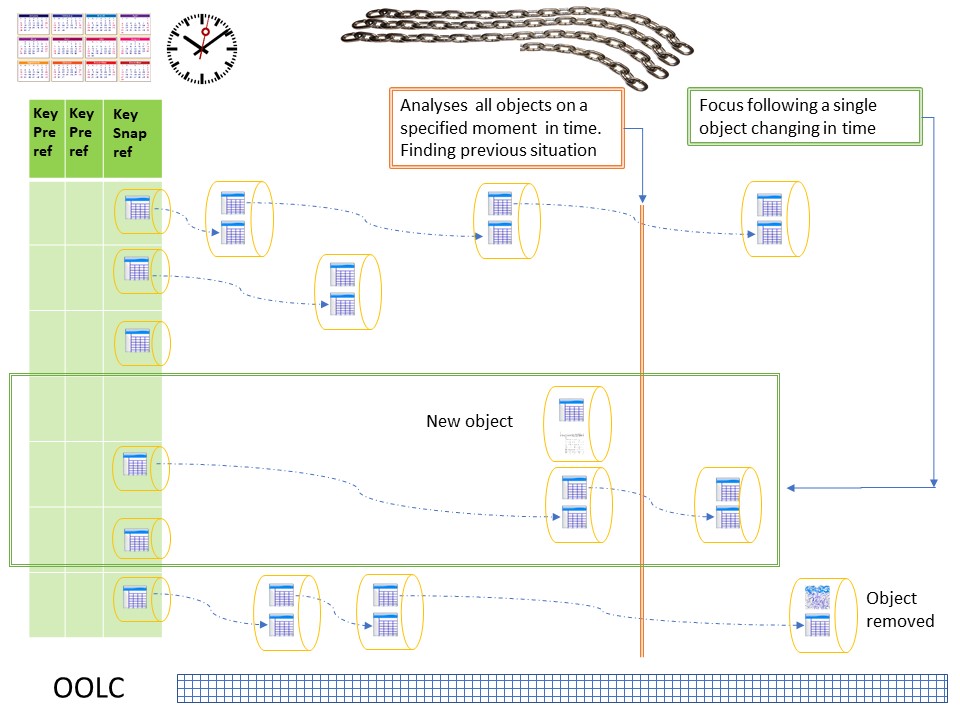
in a figure:
see left side.
See for more
👓 details
Interactions between process quantums on shop floors
A product is never created from scratch without materials being supplied, with tools being supplied.
There are several complicated supply chains:
- The chain of materials
- The chain of tools in use serviced by suppliers
Tools, platforms, are products that should comply to service agreements for products by other parties.
The chain of supply in materials is a complicated one by dependencies other external products, reuse of partial information products.
Just an attempt to visualize:
in a figure:
see right side.
Platforms, application security AppSec
Platforms are the enablers for realisations of the core processes.
- The safety in core processes is related to the state of a platform.
- Safety in core processes is an accountability for the organisation.
See for more
👓 details platform and
👓 details devops

⚖ W-3.1.3 Strategy conflicts: safe platforms, business applications
Accountability product safety
Creating or delivering a product, good, service comes with responsibilities accountabilities.
Legal people are easily missing the point what it is about but are well capable in good descriptions.
The
CRA act (eur-lex/2847) has a limited scope.
However, the text and definitions could be made applicable for all type of information products.
This part is very generic, Jabes could cover that:
Annnex II, Information and instructions to the user
At minimum, the product with digital elements shall be accompanied by:
- the name, registered trade name or registered trademark of the manufacturer, and the postal address, the email address or other digital contact as well as, where available, the website at which the manufacturer can be contacted;
- the single point of contact where information about vulnerabilities of the product with digital elements can be reported and received, and where the manufacturer’s policy on coordinated vulnerability disclosure can be found;
- name and type and any additional information enabling the unique identification of the product with digital elements;
- the intended purpose of the product with digital elements, including the security environment provided by the manufacturer, as well as the product’s essential functionalities and information about the security properties;
- any known or foreseeable circumstance, related to the use of the product with digital elements in accordance with its intended purpose or under conditions of reasonably foreseeable misuse, which may lead to significant cybersecurity risks;
- where applicable, the internet address at which the EU declaration of conformity can be accessed;
- the type of technical security support offered by the manufacturer and the end-date of the support period during which users can expect vulnerabilities to be handled and to receive security updates;
- detailed instructions or an internet address referring to such detailed instructions and information on:
- the necessary measures during initial commissioning and throughout the lifetime of the product with digital elements to ensure its secure use;
- how changes to the product with digital elements can affect the security of data;
- how security-relevant updates can be installed;
- the secure decommissioning of the product with digital elements, including information on how user data can be securely removed;
- how the default setting enabling the automatic installation of security updates, as required by Part I, point (2)(c), of Annex I, can be turned off;
- where the product with digital elements is intended for integration into other products with digital elements, the information necessary for the integrator to comply with the essential cybersecurity requirements set out in Annex I and the documentation requirements set out in Annex VII.
- If the manufacturer decides to make available the software bill of materials to the user, information on where the software bill of materials can be accessed.
Scope details product safety
The list of wat is in scope in the CRA act dos mention prodcuts in the generic "TechSec" area.
The
CRA act (eur-lex/2847 ):
Annnex III, Important Products With Digital Elements
Class I:
- Identity management systems and privileged access management software and hardware, including authentication and access control readers, including biometric readers
- Standalone and embedded browsers
- Password managers
- Software that searches for, removes, or quarantines malicious software
- Products with digital elements with the function of virtual private network (VPN)
- Network management systems
- Security information and event management (SIEM) systems
- Boot managers
- Public key infrastructure and digital certificate issuance software
- Physical and virtual network interfaces
- Operating systems
- Routers, modems intended for the connection to the internet, and switches
- Microprocessors with security-related functionalities
- Microcontrollers with security-related functionalities
- Application specific integrated circuits (ASIC) and field-programmable gate arrays (FPGA) with security-related functionalities
- Smart home general purpose virtual assistants
- Smart home products with security functionalities, including smart door locks, security cameras, baby monitoring systems and alarm systems
- Internet connected toys covered by Directive 2009/48/EC of the European Parliament and of the Council (1) that have social interactive features (e.g. speaking or filming) or that have location tracking features
- Personal wearable products to be worn or placed on a human body that have a health monitoring (such as tracking) purpose and to which Regulation (EU) 2017/745 or (EU) No 2017/746 do not apply, or personal wearable products that are intended for the use by and for children
Class II
- Hypervisors and container runtime systems that support virtualised execution of operating systems and similar environments
- Firewalls, intrusion detection and prevention systems
- Tamper-resistant microprocessors
- Tamper-resistant microcontrollers

⚖ W-3.1.4 Strategy conflicts solution: change to systems thinking
Choice, decisions for intended paths, directions
The most important thing for the futurre is knowledge in the intentions of a future state.
The future state defined in a Vision. (LI G.Alleman 2024 )
The five immutable principles of performance-based planning are designed to meet the definitions of a principle and Wideman's requirement that they be effective.
These questions can be applied to projects just as they can be applied to any endeavor, from flying to Mars to taking a family vacation.
If we use the dictionary definition of immutable, "not subject or susceptible to change or variation in form or quality or nature," we can apply these principles to any project in any business or technical domain.
The questions that need to be answered:
- Where are we going?
- How are we going to get there?
- Do we have everything we need?
- What impediments will we encounter, and how will we remove them?
- How are we going to measure our progress?
The five practices derived from the five immutable principles keep the project on track.
- Identify needed capabilities
- Define a requirements baseline
- Develop a performance measurement baseline
- Execute the performance measurement baseline
- Apply continuous risk management
Choice in product type, obvious - complicated or complex chaotic
Expections dichotomy wanting something obvious is not the correct change approach:
misunderstandings by project work (LI G.Alleman 2024 )
It is popular to construct charts showing the strawman of deterministic and waterfall approaches, then compare them to stochastic approaches and point out how much better the latter is than the former.
Deterministic:
- Technologies are stable no one believes this that has been around in the last 50 years.
- Technologies are predictable anyone with any experience in any discipline knows this is not the case.
- Requirements are stable no, they're not, not even in the most straightforward project.
- Requirements are predictable no, they're not. Learn by reading requirements guidances, observing requirements elicitation processes, or working on non-trivial projects.
- Helpful information is available at the start this would require clairvoyance.
- Decisions are front-loaded, ignores the principles of microeconomics of decision-making entirely in the presence of uncertainty.
- Task durations are predictable all task durations are driven by aleatory uncertainty.
- Task arrival times are predictable the same as above.
- Our work path is linear and unidirectional. When a system of systems becomes the problem, any complex product,—the conditions of linear and unidirectional go out the window.
- Variability is always harmful That violates the basis of all Variability in systems, where Demings Variability is built into the system.
- The math we need is arithmetic complete ignorance of the fundamental processes of all systems, they are statistical generating functions creating probabilistic outcomes.
The only explanation here is the intentional ignorance of basic science, math, engineering, and virtual computer science.
This is a clear signal on what is wrong with seeing how systems are working.
- Complex systems are not deterministic. Most needing attention are complex.
In this post there is a reaction from
T.Gilb
How to improve systems?
There is a lot existing information to combine:
Standing on the Shoulders of Giants (A.Shalloway 2024)
Instead, I build on the shoulders of giants and have integrated the main teachings of Dr. Russ Ackoff, Dr. Christopher Alexander, Dr. W. Edwards Deming, Don Reinertsen, Dr. Eli Goldratt, and Tom Gilb into one cohesive perspective to improve the way people think.
The mindset that we need to be adaptive using only empiricism to drive us only takes us so far. To truly be effective, we need to add systems thinking and understanding of our system of knowledge work.
There is some hope for getting things better.
Systems thinking:
- Cose (US) Goal: develop and disseminate the transdisciplinary principles and practices that enable the realization of successful systems.
- SCIO (UK) Goal: develops, supports, and promotes systems thinking practice for technical and ethical competence,

W-3.2 Floor plans, optimizing value streams
Building any non trivial construction is going by several stages.
These are:
- high level design & planning
- detailed design & realisation
- evaluation & corrections
Non trivial means it will be repeated for improved positions.
👉🏾
Practice what your preach. ✅ When as a service provider the real lean culture is promoted for customers the service should be according the real lean service culture.
⚖ W-3.2.1 Information quality & risk rating
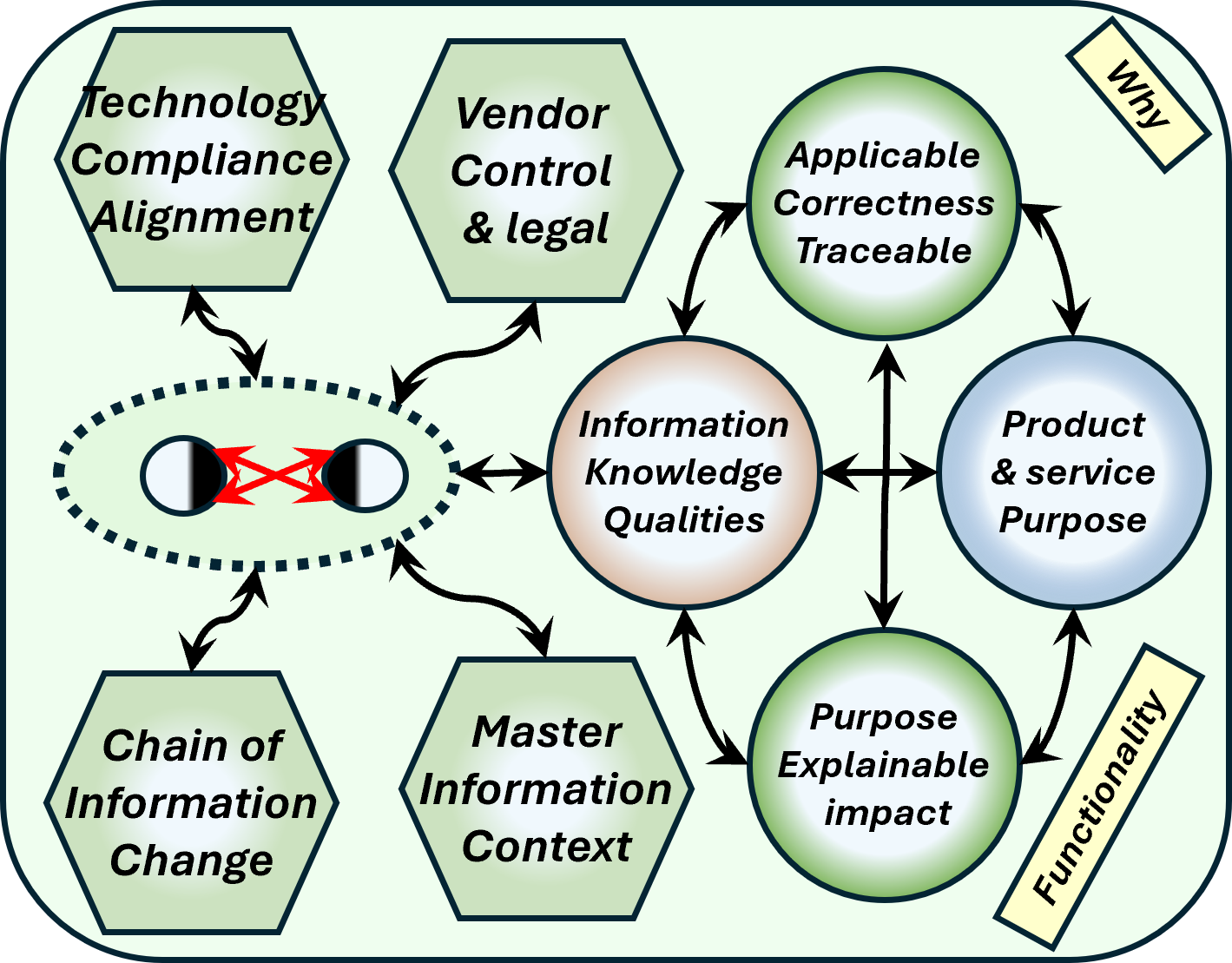
Service as a Product, Information processing
Communication acting at the viable system
CapCom: the primary point of contact and source of truth about the state of the system.
- Strong communication skills.
- High-level knowledge of the viable system.
- Sharing open communication with all that could possible help.
- Able to make quick, confident decisions how to proceed, know to who to delegate.
- Switch the interaction at the best moments to ones that give a signal to help.
- Access to all accountable roles, tasks within the viable system relevant solving evenets.
In IT Service management the goal of acting reacting got lost,
incidents, problems, changes.
👉🏾
CapCom these are not the attributes known from ITIL but are reverted to the source: the incident with apollo 13.
The time to react on an issue is important.
Variations:
- immediate like the nerve system,
- midterm like the oxygen with blood circulation
- long-term like the overall system body condition
Able to communicate within all levels is a prerequisite for able to react in time.
👉🏾 There is a duality in being very safe but not having the service available and running the service but that service has known safety issues.
To balance in the conflicts is a task role not to combine with either of the conflicting sides, segregation in duties.
Incident response readiness, education mandatatory internal
EU directive NIS2, the CapCom:
article 1
Member States adopt national cybersecurity strategies and to designate or establish competent authorities, cyber crisis management authorities, single points of contact on cybersecurity (single points of contact) and computer security incident response teams (CSIRTs).
EU directive NIS2, Also requires educations for executives:
article 20
Member States shall ensure that the members of the management bodies of essential and important entities are required to follow training, and shall encourage essential and important entities to offer similar training to their employees on a regular basis, in order that they gain sufficient knowledge and skills to enable them to identify risks and assess cybersecurity risk-management practices and their impact on the services provided by the entity.
Confusing:
prodcuts with digital elements is not technology neutral defined.
The assumption of simple devices would be different to complicated and complex or even chaotic is not underpinned.
Risk rating, readiness
This is a standard activity.
A split in technology related risk and fucntionality risks is not made yet although this is by nature of a system logical to do.
An open source option:
Ravib
The purpose of this tool is to register risks in order to control them.
Controlling risks requires knowing your risks, assigning them to people who actively deal with them and keeping track of the measures that mitigate those risks. This tool supports in that.
This register is just a tool.
👉🏾 How well risks are controlled depends on how well the responsible people deal with them.
Technical resource qualities
Metrics:
kpis
- MTBF mean time before failure: the average time between repairable failures of a technology product.
- MTTR mean time to (◎), the average time it takes to:
- repair: repair a system (usually technical or mechanical). It includes both the repair time and any testing time.
- recovery: recover from a product or system failure. This includes the full time of the outage—from the time the system or product fails to the time that it becomes fully operational again.
- respond: is the average time it takes to recover from a product or system failure from the time when you are first alerted to that failure. This does not include any lag time in your alert system.
- resolve: fully resolve a failure. This includes not only the time spent detecting the failure, diagnosing the problem, and repairing the issue, but also the time spent ensuring that the failure won’t happen again.
- MTTF (mean time to failure) is the average time between non-repairable failures of a technology product.
- MTTA (mean time to acknowledge) is the average time it takes from when an alert is triggered to when work begins on the issue. This metric is useful for tracking your team’s responsiveness and your alert system’s effectiveness.
⚖ W-3.2.2 Chain of Information change & Master data Context
Service as a Product, Information processing
At first sight this is there is no difference with the technology.
The question to rethink: Why is there an important difference?
- Technology is commodity, tools for what is commodity looks an easy business.
It is not that easy because the competition is very high.
The disadvantage for all attentions attracting effort is that the real questions what is important to get more safe is obfuscated, lost in confusion.
- Understanding the important information artifacts with their related processing is far more demanding in non trivial situations.
- Documenting the designed safety, driven by requirements, and what is achieved in safety, validated in specifications, is a gap at information processing.
There is no standard, neither a framework nor tools for this. That is what triggered "Jabes" and "SIMF".
- Aside the difference in primary processes, operational IT, there are several important secondary ones.
In information processing all looks the same from a technical perspective but the functionalities are the real important differentiators.
Business application security
What is application security (AppSec)? (2024-06 )
Application security (AppSec) is an integral part of software engineering and application management.
It addresses not only minor bugs but also prevents serious application vulnerabilities from being exploited.
An ongoing process rather than a single technology, application security (AppSec) is a crucial component of cybersecurity, encompassing practices that prevent unauthorized access, data breaches and code manipulation of application software.
As applications have become more complex:
- AppSec has become increasingly important and challenging.
- This evolution necessitates new approaches in secure software development.
DevOps and security practices must take place in tandem, supported by professionals with a deep understanding of the software development lifecycle (SDLC).
The choice of being in control over processes:
Some organizations choose to manage application security internally, which enables direct control over processes and tailored security measures by in-house teams.
When not managed on-premises, organizations outsource application security, a part of managed security services (MSS), to a managed security service provider (MSSP).
An MSSP can provide:
- a sophisticated security operations center (SOC),
- security information and event management (SIEM) solutions and
- access to specialized skills and application security tools.
These can benefit organizations that lack internal resources and expertise.
Whether managed internally or outsourced, strong security measures are essential to safeguard applications against evolving cyber threats and vulnerabilities.
⚖ W-3.2.3 Information knowledge qualities by product, service
Applicable correctness, traceability
The categories in information safety, cybersecurity:
- Technology:
- Information at rest. Examples: the storage system, DBMS tabels records usage .
- Information in transformations. Examples: the code executing, netwrok transfers.
- classifications in Confidentiality Integrity Availablity to support
- Functionality:
- Primary processes. Operational back-end and front-end ones
- Secondary processes.
- Legal obligations, what has happened
- Future continuity, what could happen
- classifications in Confidentiality Integrity Availablity to get supported
There is an important change needed when this all is going to be well in control.

Safety products, primary processes
Primary processes for information processes are referred for safety as: cybersecurity.
Safety for primary processes is an "AppSec" topic not to be confused with "TechSec" although "TechSec must be in place there is an important difference in accountability.
- "TechSec" is wat others, suppliers are delivering for enabling the needed "technology".
Although accountability cannot be transferred (data controller), responsibility is (data processor).
- "AppSec" is wat the organisation delivers as product to customers.
Neither accountability or responsibility can be transferred although suppliers by sub-processor is possible.
Safety for delivered products is very generic, the scope culd be extended to all kind of information products.
Regulation on horizontal cybersecurity requirements for products with digital elements and amending Regulations (EU) No 168/2013 and (EU) No 2019/1020 and Directive (EU) 2020/1828 (Cyber Resilience Act),
CRA act (eur-lex/2847 )
Annex I, Essential Cybersecurity Requirements.
Part I Cybersecurity requirements relating to the properties of products with digital elements
- Products with digital elements shall be designed, developed and produced in such a way that they ensure an appropriate level of cybersecurity based on the risks.
- On the basis of the cybersecurity risk assessment referred to in Article 13(2) and where applicable, products with digital elements shall:
- be made available on the market without known exploitable vulnerabilities;
- be made available on the market with a secure by default configuration, unless otherwise agreed between manufacturer and business user in relation to a tailor-made product with digital elements, including the possibility to reset the product to its original state;
- ensure that vulnerabilities can be addressed through security updates, including, where applicable, through automatic security updates that are installed within an appropriate timeframe enabled as a default setting, with a clear and easy-to-use opt-out mechanism, through the notification of available updates to users, and the option to temporarily postpone them;
- ensure protection from unauthorised access by appropriate control mechanisms, including but not limited to authentication, identity or access management systems, and report on possible unauthorised access;
- protect the confidentiality of stored, transmitted or otherwise processed data, personal or other, such as by encrypting relevant data at rest or in transit by state of the art mechanisms, and by using other technical means;
- protect the integrity of stored, transmitted or otherwise processed data, personal or other, commands, programs and configuration against any manipulation or modification not authorised by the user, and report on corruptions;
- process only data, personal or other, that are adequate, relevant and limited to what is necessary in relation to the intended purpose of the product with digital elements (data minimisation);
- protect the availability of essential and basic functions, also after an incident, including through resilience and mitigation measures against denial-of-service attacks;
- minimise the negative impact by the products themselves or connected devices on the availability of services provided by other devices or networks;
- be designed, developed and produced to limit attack surfaces, including external interfaces;
- be designed, developed and produced to reduce the impact of an incident using appropriate exploitation mitigation mechanisms and techniques;
- provide security related information by recording and monitoring relevant internal activity, including the access to or modification of data, services or functions, with an opt-out mechanism for the user;
- provide the possibility for users to securely and easily remove on a permanent basis all data and settings and, where such data can be transferred to other products or systems, ensure that this is done in a secure manner.
Why is the scope not made generic?
- Cybersecurity has a long history of being important, there are a lot of standards what to do, no generic accepted one.
- Although cybersecurity has a long history of being important, documentation conforming standards is missing.
Documenting the cybersecurity knowledge is what Jabes covers.
Part II, Vulnerability handling requirements
Manufacturers of products with digital elements shall:
- identify and document vulnerabilities and components contained in products with digital elements, including by drawing up a software bill of materials in a commonly used and machine-readable format covering at the very least the top-level dependencies of the products;
- in relation to the risks posed to products with digital elements, address and remediate vulnerabilities without delay, including by providing security updates; where technically feasible, new security updates shall be provided separately from functionality updates;
- apply effective and regular tests and reviews of the security of the product with digital elements;
- once a security update has been made available, share and publicly disclose information about fixed vulnerabilities, including a description of the vulnerabilities, information allowing users to identify the product with digital elements affected, the impacts of the vulnerabilities, their severity and clear and accessible information helping users to remediate the vulnerabilities; in duly justified cases, where manufacturers consider the security risks of publication to outweigh the security benefits, they may delay making public information regarding a fixed vulnerability until after users have been given the possibility to apply the relevant patch;
- put in place and enforce a policy on coordinated vulnerability disclosure;
- take measures to facilitate the sharing of information about potential vulnerabilities in their product with digital elements as well as in third-party components contained in that product, including by providing a contact address for the reporting of the vulnerabilities discovered in the product with digital elements;
- provide for mechanisms to securely distribute updates for products with digital elements to ensure that vulnerabilities are fixed or mitigated in a timely manner and, where applicable for security updates, in an automatic manner;
- ensure that, where security updates are available to address identified security issues, they are disseminated without delay and, unless otherwise agreed between a manufacturer and a business user in relation to a tailor-made product with digital elements, free of charge, accompanied by advisory messages providing users with the relevant information, including on potential action to be taken.
Top down structuring safety
Governance frameworks for cybersecurity al start with a vision for structure for vision in strategy.
An
cognitional structure shortlist:
- Policies : Roles - responsibilities, segregation of duties
- Relations and communication: governmental agencies, interest groups, stakeholders
- Adaption to Issue & incident solving: continuous learning, continuous improving
- Supplier Management: Relationships, agreements and supervision
- Documented compliance: policies & standards, independent assessments verifications
- Business Continuity : readiness for actions by disruptions
- Legal requirements & Privacy : personal data safety, Legal - contractual compliance
Other list are for:
- Staff measures: screening, education, monitoring, access segmentation, safety alerts.
- Technology processing: Access segmentations & zones, safety spaces, safety machines.
- Technology platforms: identity & access control, network segmentation & encryption etc..
⚖ W-3.2.4 Information impact by product, service
Applicable correctness, traceability
Those interacting to the external customers should have this in liablity of the organisation.
What is application security (AppSec)? (2024-06 )
Application security encompasses various features aimed at protecting applications from potential threats and vulnerabilities.
These include:
- Authentication: ensures that only authorized individuals gain entry.
- Authorization: verifies user privileges against a predefined list ensuring access control.
- Encryption: to safeguard sensitive data during transmission or storage within the application.
- Logging: Vital for tracking application activity and identifying security breaches.
- Testing: Essential in validation of the effectiveness of security measures.
A frequent challenge to application security lies in intra-organizational confusion about who exactly is responsible for it.
This ends up with a lot of pointed fingers and not a lot of positive action.
It’s difficult to protect something that you aren’t aware you have, and it’s also not so easy to convince people you’re doing something if you aren’t even sure yourself.
To provide transparency in whats is in use there should be a Software Bills of Material (SBOMs)
Limiting Potential: -If It Works, Don’t Touch It-
😱 A blocking culture is not wanting to understand the infromation process.
The issue:
Many programmers and organizations stick to the mindset:
"If it works, don’t touch it". (Li post michael-tchuindjang).
It feels safe and reliable; after all, if something isn’t broken, why change it?
But this way of thinking has its limits.
Instead of exploring why and how things work, it can lead us to avoid improvement and miss opportunities to innovate.
This has a relationship with not documenting attempts and experiences.
The real challenge is not the coding but understanding what the code by fucntionality does.
 In dynamic fields like cybersecurity, AI, and technology, this approach can actually prevent us from keeping up with new challenges.
On the other hand, the scientist’s mindset pushes us to constantly question, investigate, and refine.
In dynamic fields like cybersecurity, AI, and technology, this approach can actually prevent us from keeping up with new challenges.
On the other hand, the scientist’s mindset pushes us to constantly question, investigate, and refine.
Scientists:
- don’t stop at "It works."
- They ask:
- “Why does it work?” and
- “How can it work even better?”
This curiosity leads to breakthroughs and solutions we wouldn’t find if we only focused on the status quo.
By shifting from “If it works, don’t touch it” to a mindset of discovery, we open doors to growth and advancement.
👉🏾Let’s embrace the scientist’s curiosity to not just keep things running, but to improve and evolve them.
(Credits to @Cyber Writes)

W-3.3 Why to steer in the information landscape
Managing the goal for any non trivial construction follows several stages.
These are:
- high level strategy, vision & planning
- detailed strategy, missions & realisation
- evaluation & corrections
Non trivial means it will be repeated for improved positions.
Managing the process, information is needed for understanding what is going on.
Without knowing the situation or direction there is no hope in achieving a destination by improvements.
⚖ W-3.3.1 Understanding information: data, processes, actions, results
What is a business application?
❶ A
business application is defined by:
- Composed of two complementary components.
- Information at the value stream seen materialised as "data".
- Transformations of information in the value stream, "processes".
- Materialised data is seen at some type of storage.
- Transformations are processed by tools, platforms.
- Covers the value stream for customers and
all related activities, documentation, registrations.
What is a Platform?
❷Platforms are the combination of tangible goods (hardware) and intangible and services (software & support) that are enabling the business applications.
Detailed atributes are:
- A platform is composed of many complementary components.
- Tangible products, goods (hardware): servers CPU-s GPU-s-s memory, network components, cables, storage, etc.
- Intangible products, services (software): operating system, databases, communication, programming tools, etc.
- All products, goods &services, are at some support level by a suplier for support
- Have a defined functionality.
Specficiations are how functionality is defined and communicated.
- Have a defined way for functioning.
Usage instructions are how that is defined. An education and certfication program is a way for communication when usage is non-trivial.
- have a defined set of maintenance instructions.
Business applications, transformation types
❸Three types of business applications transformations:
- ALC-V1 A process that is run once.
When after each run many adjustments are needed, then it is also a one-off.
- ALC-V2 processes with transformations are based on rules set by human decisions.
Development and verifications is done with fake, synthetic information.
❗ Only the production environment uses operational information.
- ALC-V3 processes are based on what is seen at operational information and what is known by operational examples.
Development and verifications are done with operational information.
❗ All environments are using operational information.
Segregation between the stages is important but not the same as at ALC-V2.
The AI act, what is an algorithm
Artificial intelligence is getting a lot of attention.
There are a lot of misunderstandings and confusing opinions not resulting in clear guidelines.
From a post on Li:
To classify an AI system as high-risk under the AI Act.
This is a formal process: either you are a regulated product (Annex I) or a high-risk use case (Annex III), or you are not.
There's little room for debate.
There are four exceptions to this classification:
- The AI performs a narrow procedural task
- The AI merely improves previously completed human activity
- The AI detects deviations from prior decision-making patterns
- The AI performs a preparatory task
There is an indication on what was done by science and what it assuming what is the new approach.
When a data scientist manually builds these models, selecting variables and validating results step by step, it's clearly traditional statistical analysis.
But modern credit scoring systems are a different beast entirely.
They use automated logistic regression that:
- Autonomously selects which variables to consider
- Tests thousands of variable combinations automatically
- Dynamically updates coefficients as new data flows in
- Makes thousands of credit decisions daily without human intervention
This autonomous inference of patterns from data is exactly what art. 3(1) AI Act targets when it defines AI systems as those that "infer, from the input it receives, how to generate outputs such as predictions." The logistic regression algorithm itself is performing this inference by mathematically determining which combinations of input variables best predict creditworthiness, without being explicitly programmed with these relationships.
This assumption essentially declares what has been achieved by e.g. medical science, improving the living standards and survival chance improvements, as a forbidden high risk.
❹ Paradoxial: how information processing was done, interepreted, by scientists.

The AI act, how to understand an algorithm
History repeats itself with the uncertainty of predictions about the future.
However there is progress possible when accepting that uncertainties in the predictions are intangible part of the systems.
"They were shocked when two actuaries, calculations differed by 10%, as if writing down formulas could somehow eliminate the variation in underlying assumptions."
The distinction between "pure statistics" and "automated inference" isn't about the mathematical technique, it's about how autonomously the system operates in drawing conclusions from data.
Consider three phases in actuarial evolution:
- Early days: Actuaries manually calculated probabilities using statistical formulas
- Computerization: Automated calculations but human-guided model building
- Modern systems: Autonomous selection of variables, dynamic updates, minimal human oversight
This states the problem of expectations that are expected to be defined in very certain definitions.
Once the predictions from an oracle (Pythia), these days the predictions from "algorithms".
Business applications, context
The everlasting duality of control & command vs fulfiilment effectuation implementation.
❺Two contexts to see, evaluate business applications:
- Running, operating, executing, the value stream mapping process: VaSM
- Control of the value stream process within the viable system model: ViSM
⚖ W-3.3.2 Understanding goals with needed associated change
Symbiosis between humans and computers
Changes for humans at the information age.
Generative AI and the Ethical Risks Associated with Human-Computer Symbiosis
The central philosophy of the tech pioneers proposed a synergy, a symbiosis or a partnership between humans and computers.
For them, it would be preferable for humans and machines to work together cooperatively instead of not at all.
At the big-picture level, it questions whether society would be better if people were to use GenAI.
It may also be considered in a much more nuanced, detailed way; that is,
- for a particular use
- in a particular way
- at a particular time
- by a particular person,
is it preferable to use or not use GenAI?
While it may not be necessary to maintain the exact same values, it is important to note their early cautions.
Their philosophy urges us to foreground education on the ethical use of AI, leaving a potential choice not to use it as the preferred ethical choice, and emphasizes the priority and value of human thought, creativity, and responsibility.
Together with education, the social responsibility of tech companies and the need for rigorous governance systems have been highlighted in support of successful human-computer symbiosis using GenAI
7s mckinsey model
The 7S Model is designed to help organizations achieve their goals and implement change.
It focuses on the importance of coordination over rigid structure in driving effectiveness.
7-s-framework (LI post)
To use the 7S Model effectively:
- Identify the seven key elements.
- Assess each element.
- Align them and identify gaps.
- Develop improvement strategies.
- Implement changes.
- Monitor and adjust as needed.
 ❻
❻ It is a nice good model.
Adjustments: alignment with the SIAR model structure in 4 quadrants and 9 areas
Added:
- supply, suppliers
- Service Serving
- Social Intelligence
Combined:
- Strategy
- Servant Leader
- Shared values
When introduced in the late 1970s, the 7-S framework was a watershed in thinking about organizational effectiveness.
A previous focus of managers was on organization as structure: who does what, who reports to whom, and the like.
As organizations grew in size and complexity, the more critical question became one of coordination.
The lack of hierarchy among these factors suggests that significant progress in one part of the organization will be difficult without working on the others.
Today, more than ever, structure alone isn't organization.
7-s-framework
⚖ W-3.3.3 Activities in the organisation for the organisation
Value Chain, primary & secondary activities
Value chains
Streamline the processes that take a product from concept to market.
The integral linkages are supported by both structure and effective communication between direct, indirect, and support components.
Activities, such as hiring and training human capital, are further supported through activities, as record keeping and quality control.
When analyzing the effectiveness of a value chain model, the economist Michael Porter introduced 10 cost drivers that help identify areas for improvement:
- Economies of Scale: cost analysis for the size of the demand (local, national, or global).
- Learning: Activities that change the environment for efficiency or improvement.
- Capacity Utilization: efficient levels preventing under-utilization or unnecessary capacity.
- Linkages among Activities: Identifying areas of cross-functional improvements.
- Interrelationships among Business Units: Opportunities information and resources sharing.
- Degree of Vertical Integration: Identifying areas of joint integration or, de-integration.
- Timing of Market Entry: Driven by external conditions and competitive positions.
- Firm's Policy of Cost or Differentiation: Identified value integrated into the process.
- Geographic Location: Including wages, climate, and raw materials, quality - quantities.
- Institutional Factors: Include taxes, unions, and regulations.
❼ In the model:
primary and
secondary activities that relate to an organisation.

In a figure,
see right side:
Adjusting primary & secondary activities
A gap in activities by Porter is how to initiate and manage the activities by changes.
How to do that must be universal applicable, have a relationship with the backlog, issues, wishes, ideas.
In a figure,
see right side
❽ An universal service approach.
The flows:
- Operational:
- reactive using the product:
- Service request: the defined expected acceptable flow outcome.
- Incident: correction of an unwanted or not expected flow outcome.
- Pro active correcting the product:
- Change request: improvement of the prescribed actions in a flow.
- Incident to change: improvement for unwanted or not expected flow outcomes.
- Risk driven control & external:
- Improving existing product (good, service):
- Change in the external environment: regulation, information supplier chain.
- Change in the quality and/or quantity by requirements to processes.
- Innovating new product (good,service):
- Existing components, adding possible some new. Goal creation new product.
- The wish for a new not yet existing product for desired functionality.
⚖ W-3.3.4 6C-Control is not specific it is very generic
A guide, manual on leadership
11 Timeless Principles of Leadership (T.Deierlein).
"The same skills that companies today need to prevail in a climate of intense economic uncertainty." (Harvard Business Review).
- Know yourself and seek self-improvement
- Be technically and tactically proficient
- Seek responsibility and take responsibility for your actions
- Set the example
- Know your people and look out for their welfare
- Keep your people informed
- Ensure the task is understood, supervised, and accomplished
- Develop a sense of responsibility among your people
- Train your people as a team
- Make sound and timely decisions
- Employ your work unit in accordance with its capabilities
❾
Why are they still unchanged after being reviewed every few years for 60+ years by different people over the course of time?
Changing products, services
Obeya
Is a team spirit improvement tool at an administrative level, originating from a long history of learning & improving. ...
Considered a component of lean manufacturing.
Obeya objectives are rapid decision-making, reduction in rework and reconsiderations, and reduction in unnecessary discussions.
The Obeya Association enumerates 11 Obeya Principles that define Obeya and guide its improvement. ...
- Mindset:
- People come together to respectfully see, learn & act on vital information
- People are committed to engage in continuous improvement, resolving obstacles
- Alignment:
- In the Obeya, we communicate a strong sense of purpose
- Purpose is recognizably tied to our organizational strategy through meaningful objectives
- Connects strategy to execution with visible orientation on customer experience
- Meetings have a rhythm in sync with the operational heartbeat of the organization
- Workspace:
- Visuals provide a logical and practical information and conversation flow
- The Obeya reflects a good understanding of the flow of work from start to delivery
- The Obeya is an attractive and available area, in proximity to the workfloor
- Content:
- In the Obeya, we use analytics-driven-evidence to make business decisions.
- Data owners ensure information is easy to consume, readily available, up to date, and visually attractive
😉 It is the alignment of all involved persons.
Changing the organisational structure
❿ Vision and culture the foundation in the information age.
- Empowering all involved persons.
Unleashing the power of small, independent teams (2017)
Small, independent teams are the lifeblood of the agile organization.
Top executives can unleash them by driving ambition, removing red tape, and helping managers adjust to the new norms.
The empowering executive:
- Focuses small teams in customer-facing areas
- Stacks small teams with top performers
- Gives teams a clear, direct view of customers
- Allocates resources up front, then holds teams accountable
The independent team:
- Authorized to conduct activities without first seeking approval
- Has minimal dependencies on internal functions
- Builds and launches digital solutions on its own
- Draws on preassigned funding with no formal budget requested
The enabling manager:
- Defines outcomes for teams to pursue as they see fit
- Acts as a steward rather than superior
- Prioritises problem solving over decision making
- Spends more time than usual on coaching and learning

W-3.4 Visions & missions boardroom results
Managing the working force at any non trivial construction is moving power to the edges.
The cultural changes are:
- Accepting uncertainties and imperfections
- Trusting the working force while getting also well informed
- Respect for people, learning investments at staff
Non trivial means a complex or chaotic situation to get improved
Managing the working force at processes, information is needed for understanding what is going on.
Without understanding there is no hope in achieving a destination by improvements.
⚖ W-3.4.1 How to Structure engineering the enterprise
Inseparable product documentation layer
The operational performance of the organisation is having many dependencies.
"The core business" is the one that matters. The flow of that activity is a value stream.
Once the structure of information processing and the structure of the enterprise, organisation is understood optimizing to survive can become a part of the system to survive.
Learning by example of succesfull organisations
Only looking at how the success looks like and just simulating the appearance is a failure by design.
Used references are given some foundation on "how to do it".
"Use cases" or in normal words "stories and experiences" are another source for learning.
⚖ W-3.4.2 Learning structuring the enterprise by examples
High performance organisations
high performance organisations with
Steve Spear (agile podcast - M.Robinson)
Explaining how to use a developmental leadership approach with collaborative problem solving, workflow visualization and iterative improvement to become a high performing organization with an unbeatable competitive edge. ...
What's motivated over many decades is to identify those organizations able to deliver so much more value with so much less effort and then figure out what it is that explains their ability to do so versus everybody else. ...
Paradoxical examples exist and they're not limited to a sector, a phase, it's just a common human condition that some organizations are much better run in terms of generating and delivering value than their counterparts.
A summary from the podcast:
We started out with a existential threat.
The US looked at manufacturing organizations in another country and said, they are so much better than what we're doing that actually we've got an existential threat.
And that drives change because you had no choice. It's either a change or disappear.
And when you started looking at those organizations, everything you looked at they were markedly better than the competitors.
- So it wasn't just that they were lower costs.
- It wasn't just that they had a better time to market.
- It wasn't just that they made more revenue.
- It wasn't just that they were better at risk management or better at change.
They were better at everything.
And then you talked about this idea that those organizations were hyper focused on solving problems.
But the key was, they then tested their hypothesis for a solution on how to fix that problem.
- They tested it again and again until it was proven, and then they implemented it.
- They were iterating before they pushed the big green button.
- They weren't iterating after pushing the button.
So they were ensuring that they were not bringing in more bugs.
- They were not bringing in a more defects.
They were not bringing in more faults because they were testing iteratively until it worked.
This quite different than the agile software hype of delivering features fast no matter of the quality.
Another important difference is in the reporting, metrics.
... If we don't understand who we depended on when, and who's dependent on us then we optimize our location.
It's local optimization, not optimization of the system because that's what we paid for.
Those metrics aren't important.
It's really is the organization haphazard in their way of merging many into one?
So focus on:
- how much time are they taking to understand their environment?
- How much time are they:
- taking to get the things they need to be able to do their job?
- spent hunting, gathering and foraging rather than just doing the thing they need to do.
In the podcast is more.
😉 Notes on software information processing:
- Development and deployment of new software is exactly like the challenge of the development and deployment of new industrial equipment.
Because the problem is not the technology of the thing you're working on. The problem is:
- engaging the creativity of the minds of many into a well integrated harmonious collective action towards a common purpose.
- creating conditions in which the human mind can give fullest expression of its innate potential to be creative and have that come together collaboratively and collectively.
- There's a more thoughtful way that the high performers take, which is they view management, not as transactional, but as developmental.
- Where there's not the physical generation and transmission of something solid, it does become easier to lose visibility of the process and that invites chaos because we're not really aware of on whom we depend.
We're not really aware of who depends on us. For what they depend on us. ...
This organization did like a thousand of these maps, making it more obvious who did what dependent on whom dependent on by whom.
- With that kind of clarity, people could act more purposefully and less arbitrarily.
😱 Notes on confusing misunderstandings:
- What happened in the nineties is people confused the outcome of a superior management system to put half in and get twice out, and thought that if you just went into a factory, fired half the people, ripped out half the equipment your productivity would go up.
- Those who think that this lean thing or agile thing or minimal viable thing is just a matter of cut the resources and hope for the best. They get what the logic would suggest.
Of course there is some promotion,
See to Solve is about enterprise engineering, business processes in flows.
Not explicitly mentioned it is systems thinking, viable systems.
Agile project management
No wikipedia page but sure related to what is Project Managemenmt (PM) in the agile world including PMI.
agile project management johanna rothman with Johanna Rothman (agile podcast - M.Robinson)
A summary from the podcast:
Some things that aren't important and you could probably outsource those if you have to, but apart from that, if it's part of your core business and that's what you're there for why would you give it to somebody else to build for you?
- Testers are testing the solution against out of date requirements document, not against solving the customer problem.
- Command & Control by cost accounting instead of just reporting via cost accounting.
- People that are focused on problem space and people focused on the solution space.
That's where the role, skills of a product manager was meant to fix frictions.
- So our natural reaction when we want to scale teams, is to put hierarchies in place.
Even teams of teams is a form of a hierarchy.
In the podcast is more.
😱 Notes on software information processing:
- Fake agility is really the norm. I rarely see any real agility.
- Cost accounting can only work if you treat people like they are resources.
- The worst part is, it is not about working in slices through the architecture, they're all working across the architecture.
- Organizations are all very concerned about capitalization (CapEx) versus operating expenses.
- CapEx: the more to tend to divide and conquer, the worst way to capitalize.
- My experience is if you want a really helpful product that satisfies your customers, it's much more important to figure out how do we develop and deliver software products ourselves.
- I think managers are very afraid of initiatives or projects that don't meet their executives expectations.
And so they try and control everything and nail everything down.
It might work if you're running a factory producing pencils, but it doesn't work when you're doing software development.
In software development, there's always considerable uncertainty about what the problem actually is and what the solution actually is.
You don't learn those things until you do it.
😉 Notes on confusing misunderstandings:
- The core problem is a project has a beginning and an end. And when we look in software or organizations, it never ends. It's continuous, itt always lives.
- When we build a product, we are saying that product will be continuously developed and maintained.
When we have a project, we bring in all the bad behaviour that is related to a beginning and an end.
- one of the reasons managers use less than logical decision making is because they don't know any better.
What passes for leadership and management training is all about spreadsheets and nothing about people and value.
- The only difference these mediocre Agile approaches are doing any good is because they're shortening some of the feedback loops.
- Like a program team, which is composed of the software program manager, a program architect for the entire product, and often a program product owner.
You might call this the product manager for the entire product.
- We need to focus on the risks to the customer and we need to focus on the risk of us being able to deliver something to that customer.
Of course there is some promotion, expertise in
Managing Product Development is about more effective project and program management so customers receive products they love when they want them by applying agile and lean principles.
The combination is breaking usual silo's in the dichotomy of project management vs. product management. Avoiding the binary logic assumptions:
Estimates are guesses. That doesn't prevent people from wanting to know the estimate.
You can make better estimates, predictions, and increase their usefulness and accuracy.
⚖ W-3.4.3 Beliefs, social networks influencing the enterprise
The boardroom tribal politics turning the situation
Why Your Product Transformation Will Fail and
Surviving organisational politics with John Cutler (agile podcast - M.Robinson)
on product management and service design.
The review of the Sense Maker Survey by J.Cutler:
Backgrounds are in product management and UX research with some sort of business analyst type roles or just general tech roles thrown in for good measure over the years.
It's very tribal at the moment and my sense is that when times are though, you get this infighting you get this heavy asymmetries of experiences within companies.
The situation described is one of full of misunderstandings, unsafety and fear for the future.
From the "product transformation", the positive advices in what to avopid.
😉 The challenges,
your product transformation will fail if you:
- treat a transformation as a project.
- devalue the present.
- don't let your team lead the change.
- put "the best" on a pedestal.
You can learn a lot from studying how other teams work, but you need to do so with a curious mind and a good dose of systems thinking.
Encourage your team to be students of the craft and students of different approaches, but mindlessly copying and pasting how other people operate will not get you where you need to get to.
- ignore the continuous improvement muscle.
Simply put, you will need to get good at changing and adapting, which is hard and uncommon, but you'll need to do it.
- don't let go.
Change starts with subtractive change. What will you stop doing?
What behaviors will you stop doing immediately to make room for the new behaviors that need to emerge?
- lose sight of customers.
What is a win-win approach that allows you as a business and helps your customers as businesses or individuals?
- copy/paste frameworks.
Think of frameworks as a good starting point, but you better move quickly on improving and customizing. Otherwise, you will become a captive to the framework.
- ignore architecture.
You cannot have teams working independently if they have to collaborate with 30 other teams to get anything done.
- don't use "working examples" to inspire change.
It's critical to focus on fostering conditions where real-world examples can emerge that other teams can learn from and then making sure that avenues exist for those stories to be told and shared in the organization.
How are things improving? How is it benefiting customers? How did the team locally adapt the general principles to make progress? What can the team learn?
The paradox in this is: it is easier to mention a list of causes were each of them is a possible root cause for failure than a list what not to miss.
The boardroom organisational politics driving situations
Executive influence with
Rich Mironov (agile podcast - M.Robinson) on the difference in physcial goods to software development.
The review of organisational politics (J.Cutler):
Nothing in there that was a surprise.
There was nothing I haven't heard every week for the last 6 or 12 months.
Folks in the product and engineering and design spaces are hurting, their jobs are being reduced.
They often don't have representation in the executive suite.
Much of the company doesn't really understand what they do and nobody's helping them understand that.
it's a great job for a very narrow group of people who have a certain odd set of skills and capabilities.
But it is hard, I've stopped doing that CPO, VP of product job because it was too hard.
it's a job that has a lot of responsibility and very little authority or budget.
People are complaining every executive gives them a different goal or they give them a goal and then change their mind a week later.
There's no unified goal that people can gather around.
Product folks at every level need to suggest or propose possible strategies or maybe alternatives on the assumption that maybe actually nobody else knows what a strategy is, or they haven't thought it through.
In the podcast is more.
😱 Notes on software information processing:
- The language of money is what all the executives except the VP of engineering the VP of product speak.
We as product and engineering and design folks want to get the rest of the world to deeply understand all the details of everything we do and appreciate us as people and designers and product managers and engineers.
-
Well, let's think about a whole executive team:head of marketing, head of sales, head of support, head of professional services, head of finance.
Each of them has their own list, the overlap in those lists is generally small.
Each of them is starting from the assumption that it's a very reasonable list and if we just cared more about their list, we could do all of those things.
- As the head of product, I reserve the right along with my design and engineering leads to make the final call on what we're building.
We have to recognize this is a people problem not a process problem, no process is going to fix the people problem.
😉 Notes on confusing misunderstandings:
- Everybody I know in enterprise sales believes that creating software is trivially easy, and they confuse typing with writing code.
They confuse writing code with building product.
So whenever they need something, their assumption in their head is: "Oh, I should just ask for it because it's important to me.
It can't be more than ten lines of code. I bet it'll only take five minutes.""
- On the other side we're lecturing about how our backlogs are sorted instead of talking about the money we're going to make for the company, when we ship the most important thing
- There's quite often the sales narrative versus the product narrative versus the engineering narrative.
- If we've got a culture issue and a people issue at the C level in the company, then we have to address it as such.
We might bring in some consultants who are organizational design, psychiatrist consultants who are going to sit with the CEO and help the CEO understand who's blowing a lot of smoke and blowing up the company.
Of course there is some promotion, expertise in
Managing Product Development is about product executives, product management teams and revenue software organizations.
Larger companies face product/portfolio issues more complex than single-product market validation.
How do we balance competing interests and technology roadmaps?
⚖ W-3.4.4 The closed loop in structuring the enterprise
The Hoshin kanri, X-matrix loop
Discovering Hoshin Kanri (Verka Alexieva)
In a translation the intended meaning gets easily lost. The name X-matrix is meaningless.
👉🏾 Ho Shin, Kan RI (13m14) some translations:
- Vision:
- Direction
- Needle, compass
- Management:
- channel, tube
- administration, Logic
The validation is the last bottom right corner, getting too little attention.
We identified the need for more regular reviews and adaption of objectives - min Quarterly!
Leadership is the key to ensure Commitment. (21m55, 25m55)
Scalable Industry 4.0
An EnterpriseArchitecture (LI: R.Grover 2024-12)
Phases Product vs production an X:
- Foundation: current situation assessment & core implementation
- Integration: capabilities implementation, deployment & full automation implementation
- Optimization: implementation capabilities, deployment
- Innovation: Ecosystem integration, advanced capabilities, embedded transformations
In an era where hashtag#technology evolves daily and data drives business decisions, organizations need more than just digital tools—they need strategic clarity and practical innovation.
The challenge isn't just modernizing systems; it's about creating sustainable value in a rapidly changing landscape.
WS Work Standard vs SW Standard Work
💣 Everything that is documented is now referred to as STANDARD WORK. NO!
Confusion in the Lean Community WS vs SW (LI: M.DeLuzio, C.Roser 2024-12)
There is a need for best practices by the worker how to do the work (what most call work standards).
Different from technical specifications (which below were also called work standards).
- WS: A work standard is an organizational description on how to do the work.
- SW: A standard work is about when and where to do the work.
This visual closes the theories for the gaps in:
- lean and the hierarchical mind in: strategy tactics operations
- using the 6w1h Zachman 6*6 plane frame work
- viable systems with the involved dichotomies e.g. organisation vs technology

W-3.5 Sound underpinned theory, improvements
Knowing the position situation in by observing several types of associated information .
These are:
- Kind of task in the process by role
- Art of the role by observed input and results
- Art of the role by follow up interactions
Non trivial means it will be repeated for improved positions.
Command & control needs information for what understanding what is going on.
Without knowing the situation or direction there is no hope in achieving a destination by improvements.
⚖ W-3.5.1 A structured enterprise, the organic cycle
SIMF understanding the management improvement cycle
An understandable visual for what is going on, what will go on, is not easy.
Pitfalls: undercomplex, overengineered, too many not relevant details.
The logical steps for understanding and improvements looks to be dependent in a cycle.
The reality is:
- in an existing situation there is always something there,
- in a new situation only partials are done to achieve some result
The question in this is where to start for better understanding, better improvements.
in a figure:
See right side.
The context of the audience: organisation.
Switching into a another approach, not focussing on what could be dependencies but on options in the system to change some thing for the better.
The question of what and how to start for changes:
- Organisation:
- Standard work, vision: Product knowledge by specified objectives
- (coordination - alignment - mediation)
- Geo-mapped roles: Knowing what should be done.
- Persons methodologies: Knowing who should do it.
- Flows, value streams: knowng who is accountable for what is done.
- Technology:
- Optimizing for constraints limited to local interests
- (coordination - alignment - mediation)
- Functionality, technology: optimizing for the system as a whole
- Safety, technology: having the system as a whole safe for all.
- Working standard, practice: Product knowledge by defined specfications
In a different presentation acknowleding a level of autonomy in system components that are systems on their own:
| Cid | Organisation | Technology | Cid |
| description | VSM | VSM | description |
| 9 | Start-up: Vision & Execute | system-5 | system-1 | Start-up: Operations & Planning | 4 |
| Scaled: only Vision | Scaled: only Operations |
| 0 | Coordination | system-2 | system-2 | Coordination | 5 |
| 1 | Enabling system actvities | system-4 | system-3 | Planning & processing | 6 |
| 2 | Portfolio planning | system-3 | system-4 | Enabling system Products | 7 |
| 3 | Local: people execution | system-1 | system-5 | Local: synergy technology | 8 |
| Global: synergy people | system-3 | system-1 | Global: system realisations |
Surprising interactions by the transformations during scaling and way of growth in dichotomies.
SIMF understanding the technical improvement cycle
Suppose the same figure but mirrored, same actions for the technology audience.
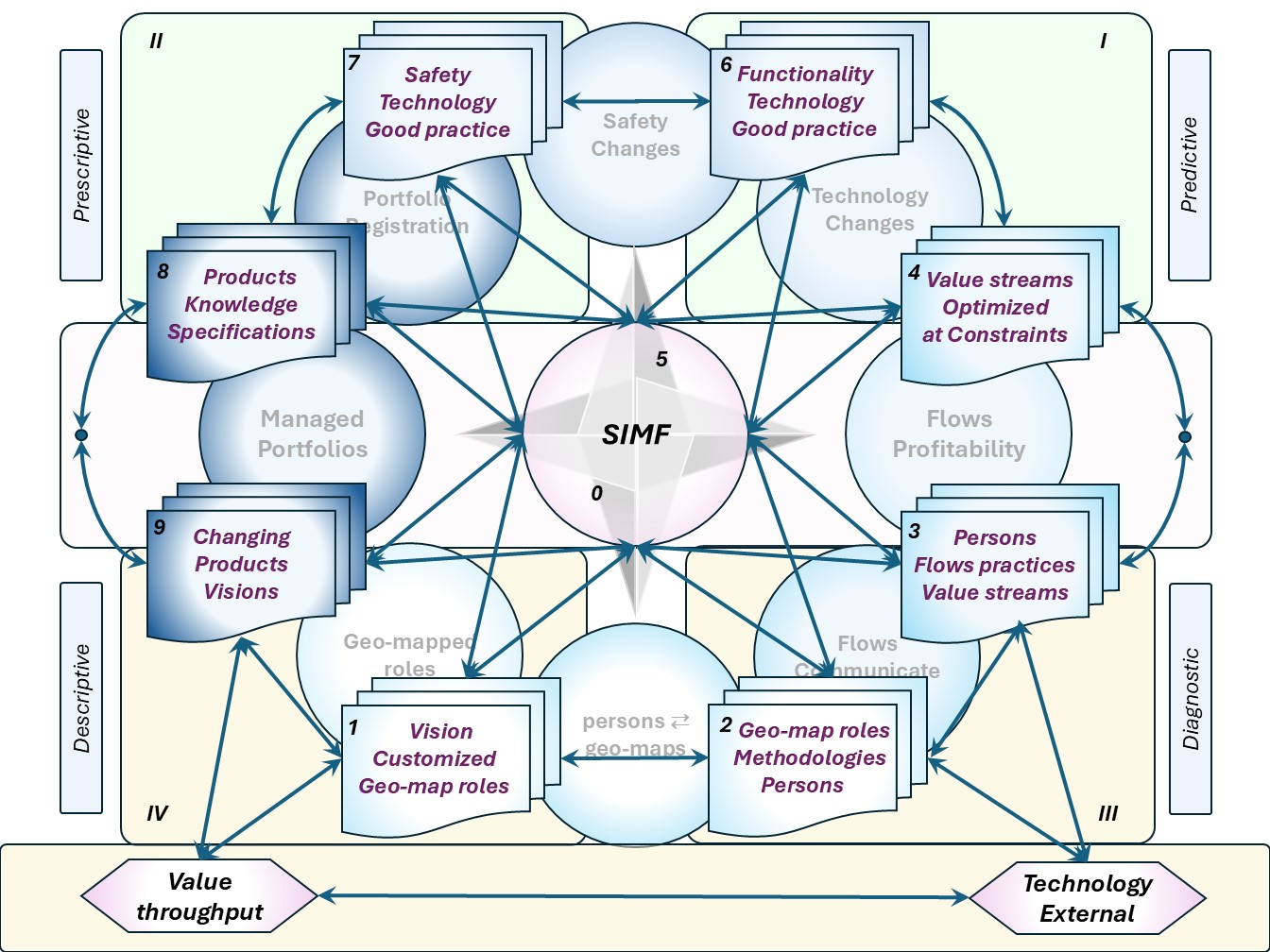
in a figure:
See right side.
The context of the audience: technology.
It is missing the ultimate system improvements for the intended purpose(s), the goal being changed into technology hypes.
Building products goods, services (new sytems) from components is forgotten.
The association reading left to right and following cycles clockwise is very strong.
⚖ W-3.5.2 The structured enterprise, backend and frontend
Mastering the purpose, the backend perspectives
Searching for processing structure, interactions:
- There are no clear independent cycles to see.
- The interaction preference in mediation coordination changes at each floor level between technology and organisation.
- The development perspective is strong related to clear expectations (backlog, suggestions, ideas).
in a figure:
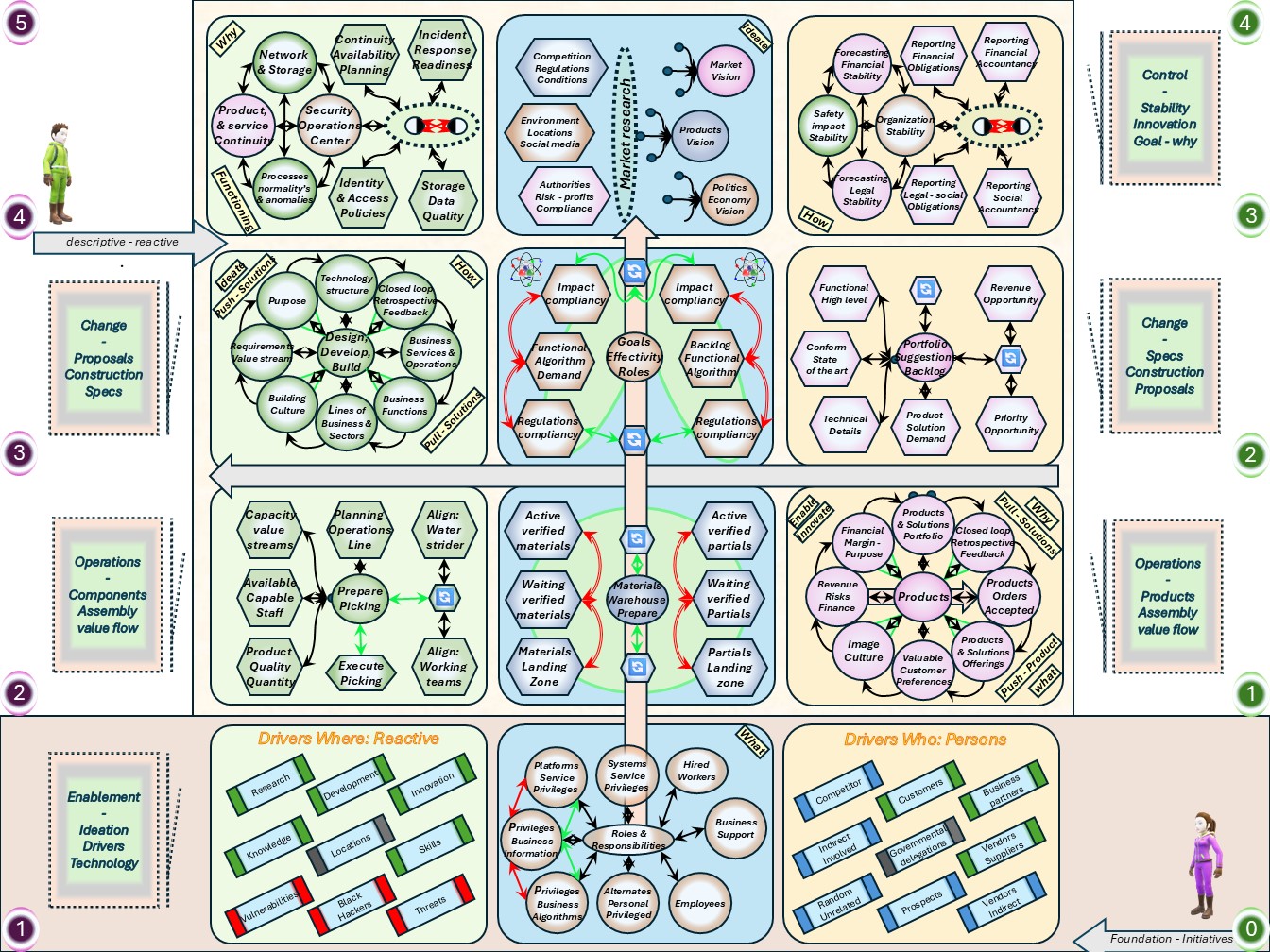
Mastering the purpose, the frontend perspectives
Searching for processing structure, interactions:
- There are no clear independent cycles to see.
- The interaction preference in mediation coordination changes at each floor level between technology and organisation.
- There validation perspective is strong related to customer delivery.
in a figure:
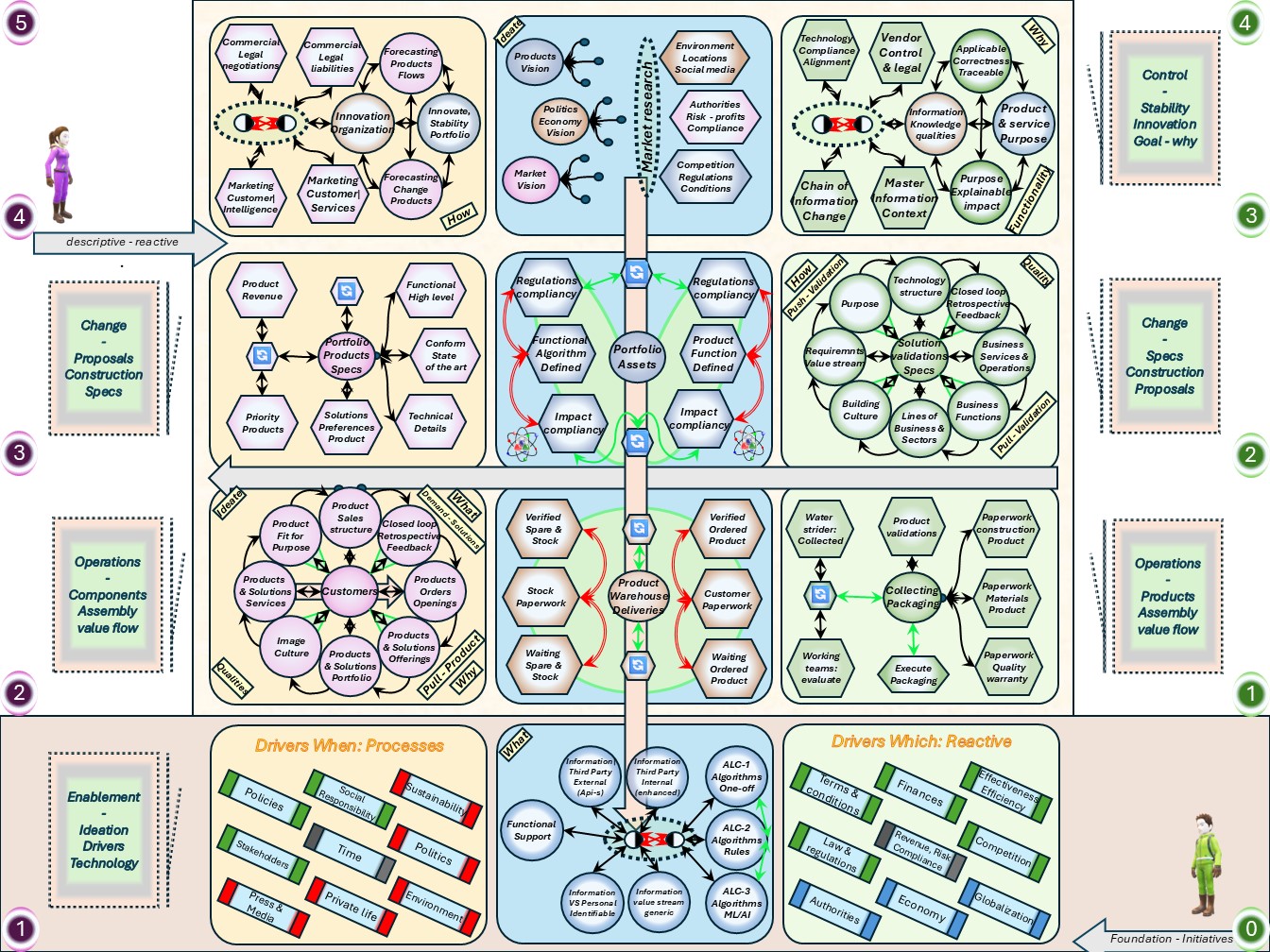
⚖ W-3.5.3 A structured enterprise, the hidden organisatonal synapse
Improving the organisation
Given a purposes working top-down to tools.
Both tools and purpose are left out in the generic approach, four of the six levels are left.
- The reversed symmetry, upside down of the pillars, is more visible.
- The challenge of the different worls of developement and operations is more visisble.
in a figure:
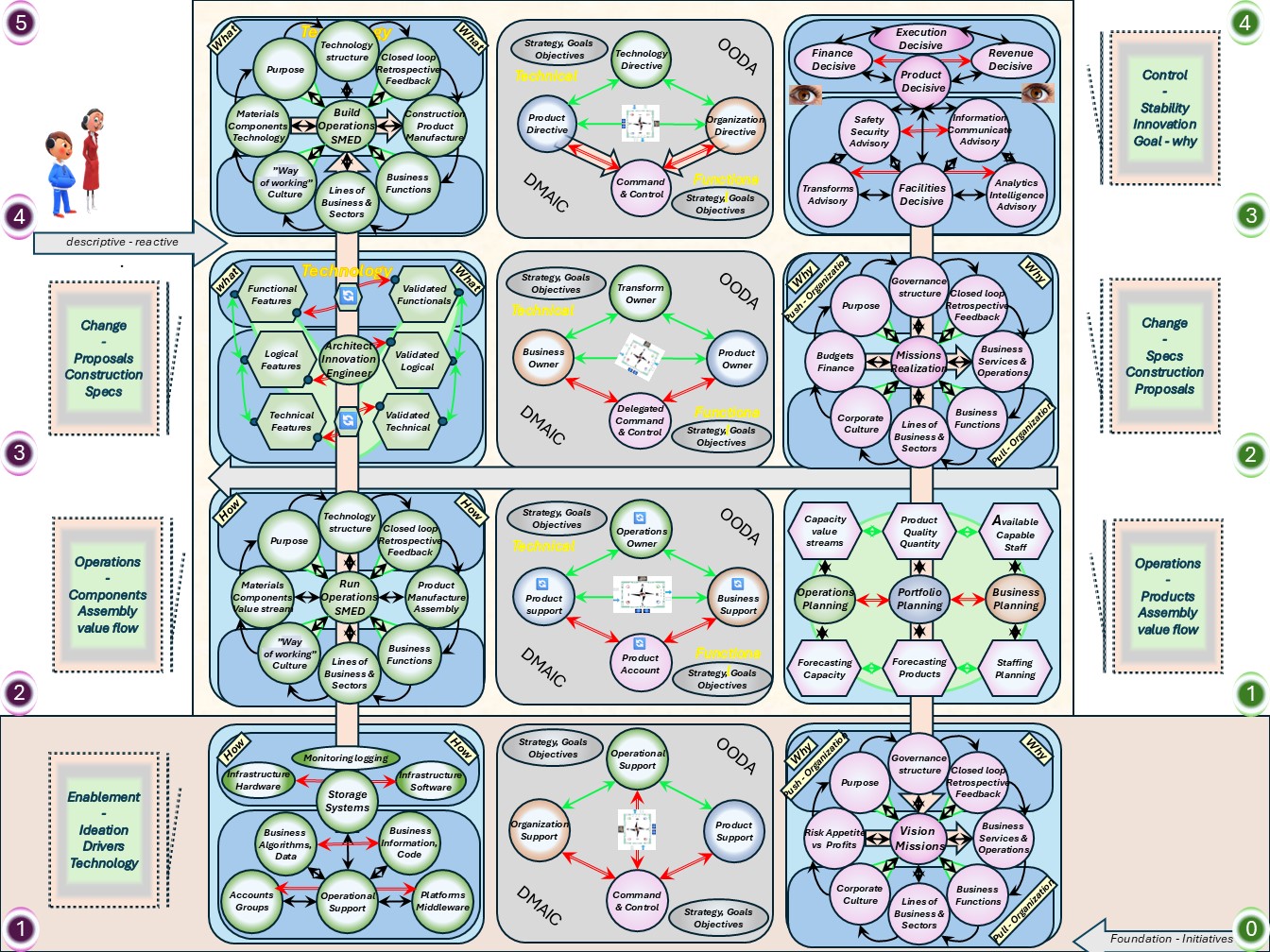
⚖ W-3.5.4 Primary and indispensable secondary processes in the whole
Extending dimension-4 to include important secondary processes
Integrating corporate identity, corporate branding, corporate communications, corporate image and corporate reputation (Researchgate: J.M.T.Balmer 2006)
It was during the 1950s and 1960s that the marketing philosophy and function began to be elucidated by scholars and adopted by managers.
Key proponents of the above include Drucker (1954), Levitt (1960) and Kotler and Levy (1969).
In terms of the marketing mix the contributions made by Borden (1964) and McCarthy (1960) are noteworthy.
In a similar vein, Robert Keith made a clear distinction between having a production/manufacturing orientation, a sales focus and, finally, a truly marketing orientation.
Greyser (1997) reflecting on Keith's tripartite categorisations observed that each is underpinned by a central question/concern which he detailed as follows:
- Production and manufacturing orientation: “Can we make it?”
- Sales orientation: “Can we sell what we can make?”
- Marketing orientation: ”Can we determine what consumers, or a group of consumers, want that we can make and sell profitably within our zones of skills?”
- Relationship marketing orientation: “Can we generate continuing business via consumer/customer satisfaction with what, and how, we make, sell, and service?”
reconnect into diverging by dichotomies
Seeing the marketing activities got that autonomous it has worn organisations into disfucntional parts it is strange seeing it has the same origin as many of the other changes.
The conclusion for this only can be that management has failed into better converging actvities.
Root-cause most likely are:
- being overwhelmed in the fast on-going changes.
- being overwhelmed in conficts in many dichotomies.
The question:
- Are dichotomies representable in a visual?
- Could it be something like a plant?
A simple manual attempt with all imperfections.
in a figure, see right side.

SIMF dichotomy to important secundairy procesess
There are several indispensable secondary processes, most noteworthy legal financial obligations and customer intelligence, information management closed-loops.
These are in a position to bypass the normal information processing approaches where they should be part of the whole.
The problem is this that they are not seen or not evaluated as important as should be by the technology pillar.
A logical line would by a system-5(ethos policy) by technology and system-4 at the organisation for adapting change.
Going into the system-3 and system-1, there is a that big challenge in technology alignment the usual gap in misundertandings:
- Technologies that are fore sure not the same as in primary processes.
- Functional requirements that are fore sure not the same as in primary processes.
Servicing technology important secondary processes:
SIMF_DSEC_01: Support for mandatory legal obligations e.g. financial reporting.
- Rationale:
- When mandatory legal obligations are ignored the whole system is in danger.
- Behaviour and requirements are a category on their own.
The goal is usually on what has happened, the paste.
- There must be a CapCom Information role for enabling the fast reactions
- Implications:
- Interactions with a dedicated segmentation is preferable
- Accountability at the organisation. GDPR: Data controller
- Responsibility at the technology: GDPR: Data processor
SIMF_DSEC_02: Support for research e.g. customer intelligence and decision information provisioning.
- Rationale:
- Any impact on the system as a whole matters the system as a whole
- Behaviour and requirements are a category on their own.
The goal is usually on what is likely to happen, the future in scenarios.
- There must be a CapCom Information role for enabling the fast reactions
- Implications:
- Interactions with a dedicated segmentation is preferable
- Accountability at the organisation. GDPR: Data controller
- Responsibility at the technology: GDPR: Data processor
W-3.6 Maturity 5: Strategy visions adding value
From the three PPT, People, Process, Technology interrelated areas in scopes.
- ✅ P - processes & information
- ✅ P - People Organization optimization
- ✅ T - Tools, Infrastructure
Only having the focus on others by Command and Control is not complete understanding of all layers, not what Command & Control should be.
Each layer has his own dedicated characteristics.
⚖ W-3.6.1 SIMF-VSM Safety with Information at Technology
A Paradigm Shift in the Information and Cybersecurity Mindset
From Compliance to Culture
Heisenberg’s Paradox in Information Security
Focusing on compliance offers a challenge that parallels the uncertainty principle, also known as Heisenberg’s indeterminacy principle, introduced in quantum mechanics.
The principle explains that we cannot simultaneously measure two complementary properties of a system, such as position and momentum, with absolute precision.
The more accurately you measure one property, the less precise the measurement of the other becomes.
In the context of information security, this principle offers an insightful analogy.
By focusing intensely on measuring and documenting compliance (a static attribute of security), organizations lose clarity on the more dynamic and contextual aspects of security:
- How well users adopt measures.
- How effectively these measures improve resilience and protect against existing and evolving threats.
❶
This creates a paradox:
- The harder we try to document and measure security compliance with detailed precision, the more we risk losing sight of achieving the actual secure processing of information.
- Instead of acting as a means to an end, compliance often becomes a standalone goal, disconnected from its real purpose of supporting organizational success.
When organizations pour resources into proving compliance, they often fail to anticipate future risks. These blind spots leave them vulnerable to emerging threats, as their efforts focus on past performance rather than adaptive resilience.
Measuring and documenting security is important, but it shouldn’t come at the expense of actually being secure.

Principles: Safety with Information at Technology
There is a lot of autonomy expected from the information processing perspective by the organisation.
The challenges:
- Too often ignored or only poorly getting some attention are the expectations for the organisation by technology.
- A categorized list in defintions for understanding and alignment is required.
❷ SIMF component: Safety at Information processing at Technology, SaIT:
- SIMF_SATS_04: An open algedonic channel between the organisation and SaIT.
- Rationale:
- Any impact on the system as a whole matters the system as a whole
- A fast immediate response requires fluent trained cooperation
- There must be a CapCom Information role for enabling the fast reactions
- Implications:
- Accountability at the organisation. GDPR: Data controller
- Responsibility at the technology: GDPR: Data processor
- SIMF_SATS_05: Organisation alignment to SaIT for dedicated scopes.
- Rationale:
- Any impact on the system as a whole matters the system as a whole
- Every organisation has to go through the mandatory alignment for all their details.
- Every organisation is required to maintain the alignment for all on going internal and external changes.
- Implications:
- The variety: Organisations are not all the same although they share a lot.
- All channel types (1-6) are used for achieving an alignment.
- The complexity: every channel act at his own speed, using own regulator types.
- SIMF_SATS_06: Alignment details SAIT for: People, Processes, Machines and Structure.
- Rationale:
- Any impact on the system as a whole matters the system as a whole
- Regulations are mentioning explicit CIA:
- People ⇄ Confidentiality,
- Processes ⇆ Integrity,
- Machines ⇄ Availability
- Regulations are mentioning structure by:
- Segmentation in the three CIA topics, internal and external
- Supplier management, e.g. required safety at their side
- Physical spaces, e.g. controlled monitored access
- Communications spaces, e.g. clean desk policy.
- The structure of the system is component not mentioned by regulations.
- Implications:
- There are a lot of attentions point to fulfil.
- There is a lot of mandatory administration related to products.
- The structure of a system needs dedicated attention for threats.
⚖ W-3.6.2 Structuring viable systems with competing dichotomies
Systems thinking, differences between the systems
Another challenge:
correctly manage the work
There's a vast difference in types of work.
- Routine work - should be highly predictable both in execution and outcome.
- Delivery work - should be highly predictable in outcome.
- Creative work - is hardly predictable.
Two fundamental mistakes people make, especially in the management and consulting space:
- Misunderstanding: nature of the work. Not understanding why the outcomes are suboptimal.
- Misapplying management approaches that are intended for a specific type of work to others.
That leads, at best to waste. And at worst, to complete and utter failure.
❸
Now, the difficulty is that you may need to be an expert in the work itself to determine which is which.
And that's why the concept of "manager experts" is fundamental to complex environments where all types of work are present.
- Can you classify what percentage of the work your team is doing belongs to which category?
That's already hard.
- But can you correctly predict it for everything being worked on?
That's hardly possible - as a simple routine might explode in complexity when circumstances suddenly change!

Systems thinking, optimizing KISS principle
Kiss "Keep It Super Simple" is the fundament for many good viable systems.
Introduction to Karakuri Kaizen
Industry 4.0 is currently all the rage.
Yet, karakuri kaizen with its focus on mechanical solutions is pretty much the opposite!
These gadgets are not connected wirelessly, and not online as part of the internet of things or cyber physical systems.
Heck, they don’t even have a microchip! So why use them? After all, any of these actions can also be done using sensors , actuators, and processors.
Yet, karakuri is often better. In my view, there are a few advantages.
- Cheaper ...
- Easier to maintain ...
- Much Easier to Improve ...
Hence, karakuri devices allow for a grass-roots continuous improvement in lots of little steps.
Computer systems are big steps, usually initiated by management when they notice the problem (often too late, and only the biggest ones), and implemented by engineers and programmers when they have the time (rarely). In sum: Kaizen is so much easier with karakuri!
❹ In the information landscape there are no known nice examples of simplicity. Why not?
The four seasons are well understood, it is hard in a X-matrix, (Hoshin Kanri).
Systems thinking, variety undercomplex
When acknowledging a dichotomy between two competing subsystems lead to undercomplexity.
undercomplex - variety Systems (Li C.Dethloff).
Organizations are often modeled too trivially: with exactly one center and exactly one periphery.
Management is allocated in the center and teams that create value for customers are in the periphery.
Why is this view too simplistic?
- Management in the center is far too overloaded, by all those teams on the periphery.
- The larger an organization becomes, the greater the overload will become.
In the language of organisational cybernetics, the variety to be managed would be far too high.
The question:
- Is a dichotomy representable in a visual?
- Could it be something like a plant?
A simple manual attempt with all imperfections.
in a figure, see right side.
❺ The world of chaotic systems that are predictable full of uncertainties unordered orderings.
Mathematical:
The famous visual,
Mandelbrot fractals (1980).
The set is defined in the complex plane as the complex numbers for which the function
f_{c}(z)=z^{2}+c} does not diverge to infinity when iterated starting at z=0 remains bounded in absolute value.
⚖ W-3.6.3 People authoritative leader "PAL" - Operational Units "OUs"
Systems thinking, span of control
About:
managing variety (Li C.Dethloff)
In the context of leadership, the question is often about the level of span of control:
- How many people should be formally led by the people authoritative leader, "PAL".
The undercomplex answer usually a number: 12, 15 or 20 for Operational Units "OUs".
A suitable answer can be found using the "VarietyManagement" thinking tool from "Organisational Cybernetics".
This tool brings varieties of the vertical and horizontal control axis into a suitable balance.
The horizontal control axis describes the connection between people and their respective sphere of action (tasks and responsibilities of each person).
The following factors are horizontal "variety" (increasing):
- Number of people
- Diversity of people's sphere of action
- Freedom in self-organization of people
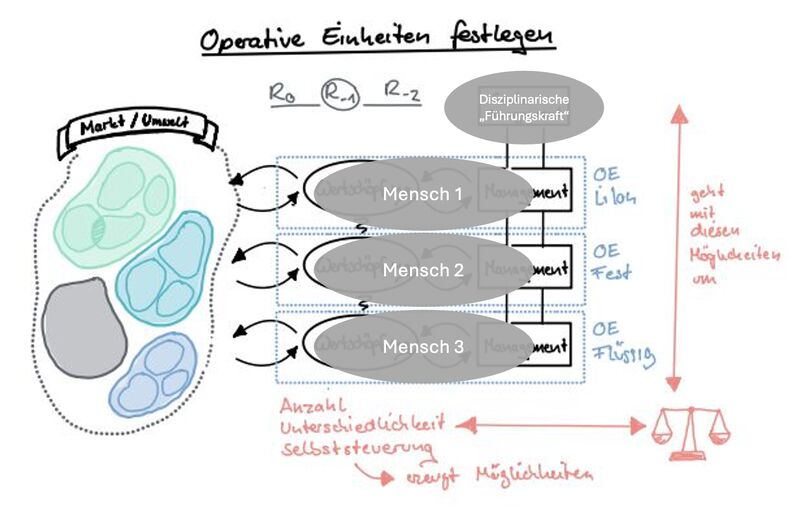 The autonomy of individual people should be high so that they can fill their sphere of action.
The autonomy of individual people should be high so that they can fill their sphere of action.
⇄
Horizontal "OUs" variety should be absorbed by the variety of the vertical control axis, the "PAL" task.
⇅
The vertical control axis describes the connection between people and the "PAL".
Freedom in self-organization, is restricted to achieve more alignment.
Factors that influence variety absorbtion (increasing):
- Overlapping service recipients between people
- Auditability in creating transparency
- Operational dependencies between people
- Shared use of resources
- Operational control by the "PAL" at people
- Coordination between people in the form of rules, principles, guidelines, standards, etc.
❻
When these options are not sufficient the "PAL" is overwhelmed.
The consequence: the span of control, i.e. the number of people to be managed, could be minimized by adding another management level.
This creates a suitable span of control without guessing numbers out of context.
The following applies:
- Higher "OUs" autonomy aspirations : "centrifugal force", outward diverging
- the stronger the senior management force "centripetal force", inward converging, must be in order to achieve a balance between autonomy and alignment.
This has been ignored in recent years, especially in the "agile bubble".
More emphaty has been placed on the "OUs" efforts for autonomy neglecting the alignment by management.

Floor: 0-1, 1-2, 2-3, 3-4 growing maturity
The indicator floor 0-1 was chosen because a start-up starts wirh nothing creating the first ones.
This for the first valuable product. The 1-10 journey for the company achieved a product-market fit and going for scaling its business.
❼ The transformation over the floors is a fit to VSM and CMM.
- floor 0-1: Small and Start-up.
Scaling up, foundation for: culture, people, processes, machines
- floor 1-2: Scaled up: operations, product deliveries, service - support
- floor 2-3: Scaled up: Product development, improvements, innovations
- floor 3-4: Specialisation for: Legal obligations, finance, marketing and
technical providence for safety, delivering synergy for the others.
What about floor 4-5, 5-6?
There are the parts for enabling to react, react for the whole wit on top the rules and ethos, the attributes that were emerging from a start-up.
Roles tasks Floor: 0-1, 1-2, 2-3, 3-4
❽ Now we have a system model in floors, the questions is: what roles are a good fit at what location?
Key tasks roles by the verticals:
| floor | Organisation | Mediation | Mediation | Technology |
| system-5 | system-3 | system-3 | system-5 |
| 0-1 | Executive officer | Human facilities | Process planner | Technology specialist |
| Captain, Driver | Purser | Loadmaster | Machinist |
| 1-2 | Resource manager | Account Manager | Project Manager | Operations Officer |
| Sales Manager | Customer Service |
| 2-3 | Portfolio manager | Program Manager | Product Manager | Product Engineer |
| 3-4 | Financial specialist | Business analyst | Market analyst | Technology Officer |
| Risk specialist | Product officer |
⚖ W-3.6.4 A generic context of the 6C in viable systems
Improving vs innovation for products, services
❾ The military sources are mentioning the concepts are generic valid, is that all there is?
The philosophy of a corporate-level how people think and behave
Integrating corporate identity, corporate branding, corporate communications, corporate image and corporate reputation (Researchgate: J.M.T.Balmer 2006)
Like the Roman God Janus, we gain perspective by looking both backward and forward.
In looking forward we conclude that marketing is undergoing another paradigm shift and is increasingly characterised by having an institutional-wide focus.
The label “corporate marketing” to the area. ...
 A corporate marketing philosophy represents a logical stage of marketing’s evolution and introduce a revised corporate marketing mix (the 6Cs) as an illustrative framework representing the key concerns that underpin this expanded viewpoint of marketing. ...
A corporate marketing philosophy represents a logical stage of marketing’s evolution and introduce a revised corporate marketing mix (the 6Cs) as an illustrative framework representing the key concerns that underpin this expanded viewpoint of marketing. ...
- "Can we, as an institution, have meaningful, positive and profitable bilateral on-going relationships with customers, and other stakeholder groups and communities?”.
- In essence, the philosophy of corporate-level marketing should permeate how people in the organisation think and behave on its behalf.
Each model employs different assumptions about the power/balance in the marketplace,
- the origin of consumer needs and desires,
- the type of consumer power exercised,
- the “warning” to consumers or business that pervades the marketplace,
- and the role of the marketer.
- To us, corporate marketing represents a logical fourth stage in terms of the above. ...
❿
For this reason the mix of elements should be seen as informing an organisational-wide philosophy rather than as encompassing a mix of elements to be orchestrated by a department of corporate marketing.
This closes marketing philosophy back into the culture of the enterprise:
| internal | Culture | ⇄ i 1 ⇆ | What we feel we are | |
| Character | ⇆ i 2 ⇄ | What we indubitably are | |
| Communication | ⇄ i 3 ⇆ | What we say we are | |
| External | Constituencies | ⇆ e 4 ⇄ | Whom we seek to serve | Stakeholders |
| Covenant | ⇄ e 5 ⇆ | What is promised and expected | Brand |
| Conceptualisations | ⇆ e 6 ⇄ | What we are seen to be | Reputation |
⚖ W-3.6.5 Following steps

These are practical data experiences.
MetaData Information generic - previous
bianl, Business Intelligence & Analytics 👓 next.
Others are: concepts requirements: 👓
Data Meta Math
© 2012,2020,2024 J.A.Karman