Devops Data - practical data cases
Patterns for quick good realizations
Hardware performance Patterns as operational constructs.

Understand os performance, why is it critical?
There are a lot of questions to answer:
📚 Information data is describing?
⚙ Relationships data elements?
🎭 Who is using data for what proces?
⚖ Inventory information being used ?
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.
Contents
| Reference | Topic | Squad |
| Intro | Hardware performance Patterns as operational constructs. | 01.01 |
| Os developments | Performance & Tuning - OS level introduction. | 02.01 |
| cpu memory io | Components Performance & Tuning - OS level. | 03.01 |
| Storage types | SAN, NAS, Cloud storage. | 04.01 |
| Storage tune | IO performance improvement strategies. | 05.01 |
| What next | OS performance - Executing & Optimisations. | 06.00 |
| | Following steps | 06.02 |
Progress
- 2020 week 07
- Page rebuild.
- New content, gathering old samples.
Duality service requests

sdlc: The workload for the machines is given by the software in use and the size of the organisation. When the software is bought (COTS) there are no options to change that behaviour in usage.
bianl: The tools are usually bought but most of the work is done in house. It is the internal organisation that is in lead. All dpends on the size.

bpm tiny: choose any tool that will do the job. As long the size and performance are not problematic there is no reason to overcomplicate things.
bpm big: choose machines and tools apprapiate for the services, analyses that are expected to be needed and that will be executed in the time it will run.

Performance & Tuning - OS level introduction.
The hardware and the operating system are the fundaments where tools middleware and business applications are landing.
That fundament should be aligned to what is needed for the tooling with the business usage.
Computer resource limits.
A nasty situation when the future computer resource usage request is not known or cannot be estimated.
The good thing in these days is that computer resources are not that expensive anymore.

Everybody has heard of Moore´s law, a predictions that every two year the number of components on a chip is doubled.
👓 -- The Free Lunch Is Over --
The growth in speed for a single processor has stopped around the year 2000. The growth in components has gone into multiped cores and more internal memory.
Optimizing is balancing between available resources on the moment and expectations for the future choosing the fittest algorithms.
Scaling up, Scaling out.
The advance in hardware made it affordable to ignore the knowledge of tuning and multi tenancy services.
Scaling up as free lunch is still possible.
Newer hardware has more cores, more memory and I/O network speed often goes better, although it is by adding more physical connections.
Advantage:
- no change in software, tools and or business applications.
Disadvantage:
- good practice alignment required in system setup, tools and business applications
Scaling out is using more machines that are operating as a single service.
Advantages:
- Different machine workload types having their own environment.
- Isolation in network layers is possible when having different security requirements (DMZ external world).
- When the number of cores and / or size of internal memory is the resource problem to overcome not able to sole by a single machine.
Disadvantages:
- Adding complexity having an increasing number of machines to manage.
- Data transport and data locking issues when using a shared data access approach.
- Standard machines delivered are usually not tuned aligned to load requirements.
An astonishing approach is buying hardware that is capable of doing the job and than splitting the machine in many small machines to go for a grid parallel solutions of machines.
Asking for the argument for this and getting the answer that that is how it should be done because we should go for a "grid".

Components Performance & Tuning - OS level.
Using computer resources efficient is requiring understanding what will happen when the software will cause a workload.
That workload can be influenced by:
- Algorithms exchanging one resource for another
- Workload planning spreading in available time.
- Eliminate unnecessary overhead at the cost of algorithm redesign & rebuild.
Considerations on the resulting workload.
There are three levels in the considerations:
- cpu & internal memory
- connection to external storage
- external storage
Accessing information and needing all three of them is evalutation on cooperation of tasks.
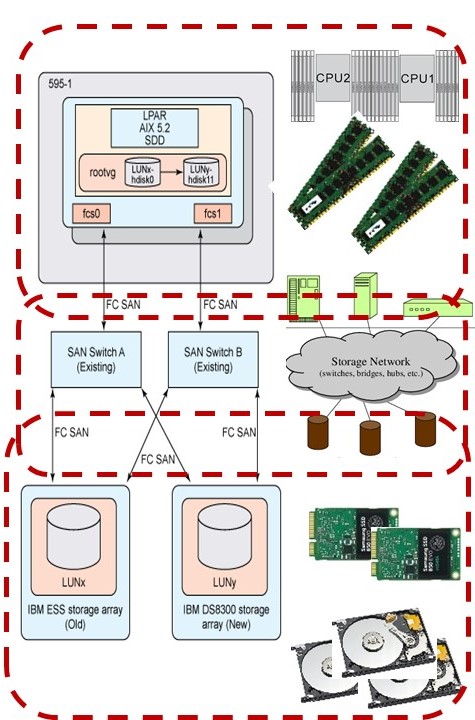
Tuning cpu - internal memory.
Minimize resource usage:
- use data records processing in serial sequence. (blue)
- indexes bundled (yellow).
- Allocate correct size and correct number of buffers.
- Balance buffers between operating system (OS) and DBMS. A DBMS normally is optimal without OS buffering (DIO).
🤔 In the DBMS approach the assumption is made that not all data will fit into memory.
When all data fits into memory the network and storage io considerations are moved to another moment in time.
With the growth of internal memory at hardware level, this not obvious anymore. These days many tools are expecting all data will fit into memory.
The spreadsheet usage approach at another scale. Asking for 32Gb internal memory being used for a program and getting it, is not impossible.
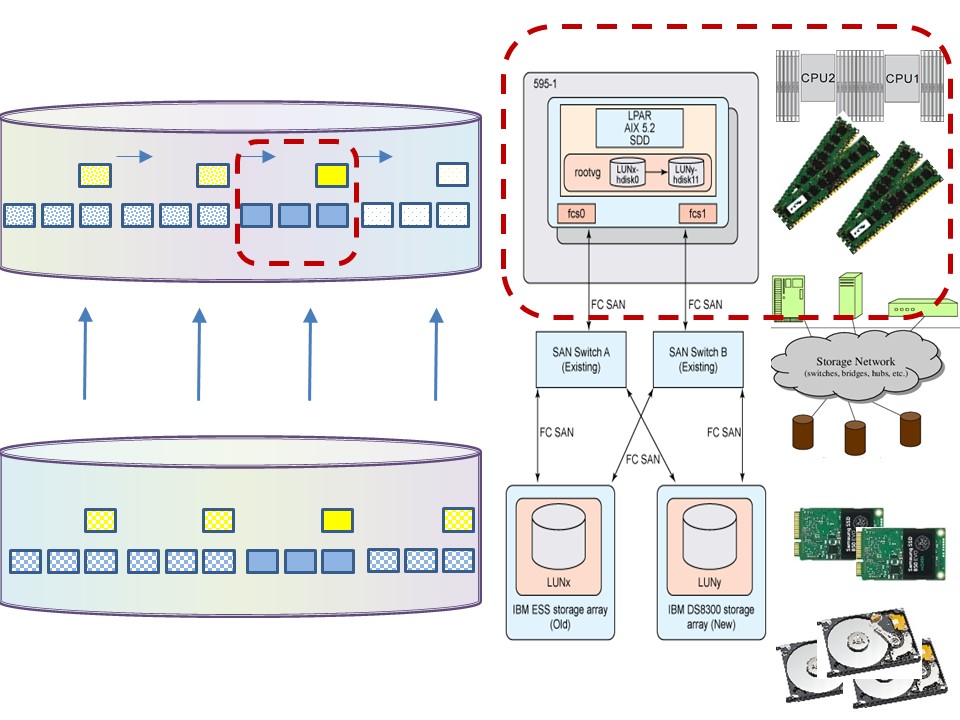
Network throughput.
Minimize delays, use parallelization:
- When using a SAN and having local storage, think on what to do with, paging, scratch, temp, work storage.
- Have no serialisation on the multiple communication connections.
Stripe logical volumes (OS).
- Parallelize IO, transport lines.
- Optimize buffer transport size.
- Compress - decompress data at CPU can decrease elapse time.
- Avoid locking caused by: shared storage - clustered machines.
⚠ Transport buffer size is a coöperation between the remote server and local driver. The local optimal buffer size can be different.
Resizing data in buffers a cause of performance problems.
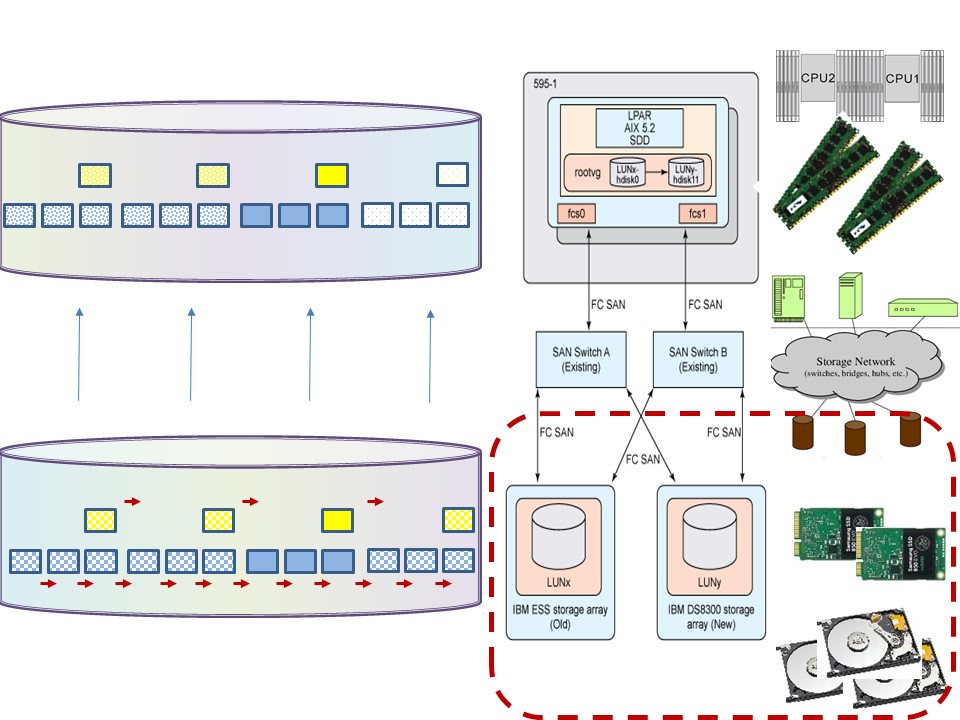
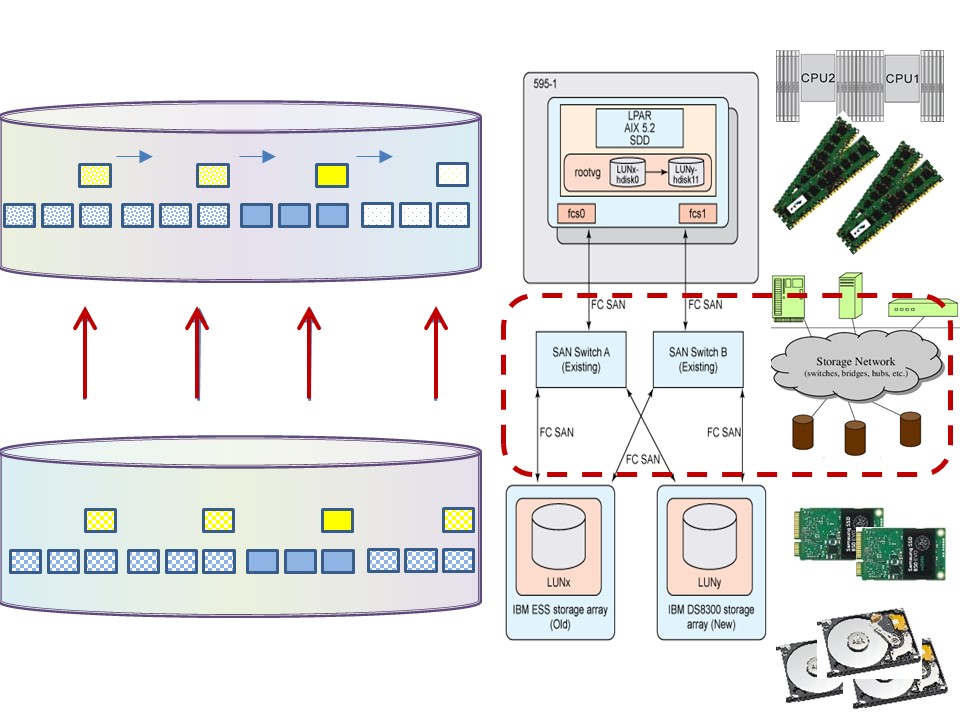
Minimize delays in the storage system.
- Multi tiers choice SSD- fast Hard disk, slow hard disk.
- Use raid technology 10 (duplicate and one parallel) or raid 6 for reducing access time.
- Tape, backup used in a SAN environment.
- Prefer: sequential or skipped sequential with read ahead.
- tuning with analytics usage is big block bulk sequential instead of random small block transactional usage.
⚠ Asking for storage he easy understanding is the size of storage needed. The needed performance speed in data delivery is as important for the quality of service.
💣 Neglecting the performance speed, quality of service can result in a system that is not acceptable functioning.
⚠ Using Analytics, tuning IO is quite different compared to a transactional DBMS usage and incompatible with a web server.
💣 This different non standard approach must be in scope with service management. The goal of sizing capacity is better understood than Striping for IO performance.

DAS, SAN, NAS, Cloud storage.
The abbreviations are hiding what the expected behaviour is. That behaviour can make an important difference for choices in practical usage.
Storing information at rest is an important topic. Information in transit is another one.
Starge types.
How the sorage types are different is:
📚 DAS, Direct Attached Storage, is traditionally connected to the machine not using any network. Well known form the personal computer, laptop, equiped with that type of storage.
📚 SAN, Storage Attache Network, is the solution for terabytes (1012) of storage and multiple, simultaneous access to files, such as streaming audio/video.
📚 NAS, Network Attached Storage, is used for low-volume access to a large amount of storage by many users.
In an overview some characteristics:
| | DAS | NAS | SAN |
| Storage Type | sectors (eg 512 bytes) | shared files | blocks (eg 64k). |
| Data Transmission | IDE/SCSI | TCP/IP, Ethernet | Fibre Channel. |
| Access Mode | clients or servers | clients or servers | servers. |
| Capacity | apx 500 Gb | apx 10 times DAS | from 10 times of DAS |
| Complexity | Easy | Moderate | Difficult |
| Management Cost | High | Moderate | Low. |
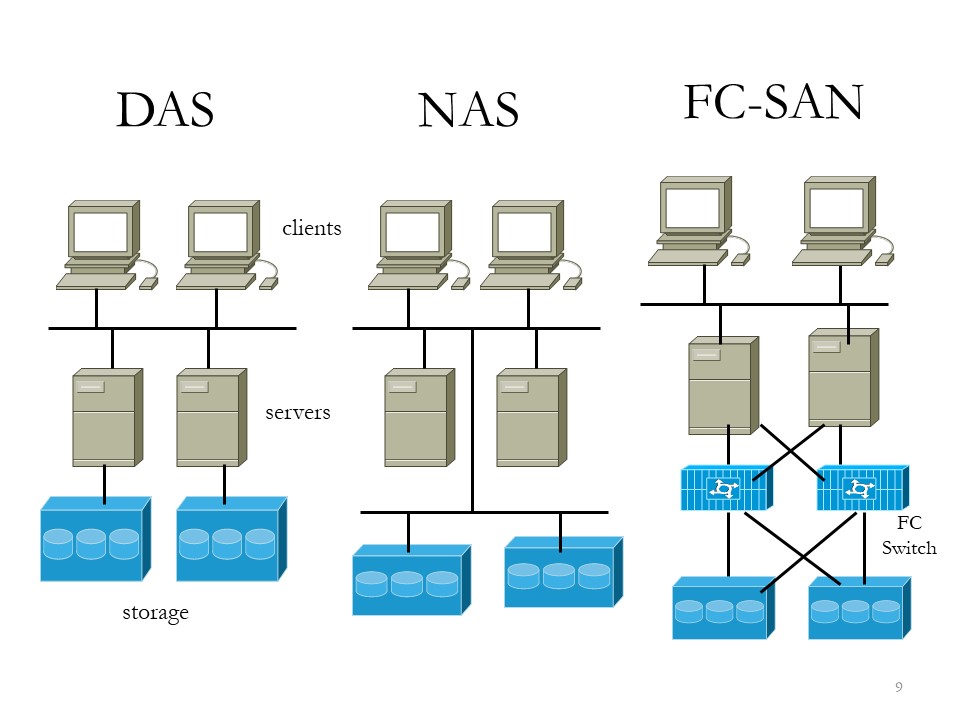
With DAS every machine has his own storage, sharing information is diificult to manage.
File servers (NAS) are sharing files, there is no segreagtion in servers and clients in the network.
Moving the storage into a network (SAN) isolates the data managed for servers from clients. There are two networkconnections on each server.
SAN, enterpise environment.
A Storage Area Network (SAN) is a specialized, dedicated high speed network joining servers and storage, including disks, disk arrays, tapes, etc.
Storage (data store) is separated from the processors (and separated processing).
High capacity, high availability, high scalability, ease of configuration, ease of reconfiguration.
Fiber Channel is the de facto SAN networking architecture, although other network standards could be used.
👓 From IBM redbook: sg245470 "Introduction to Storage Area Networks"
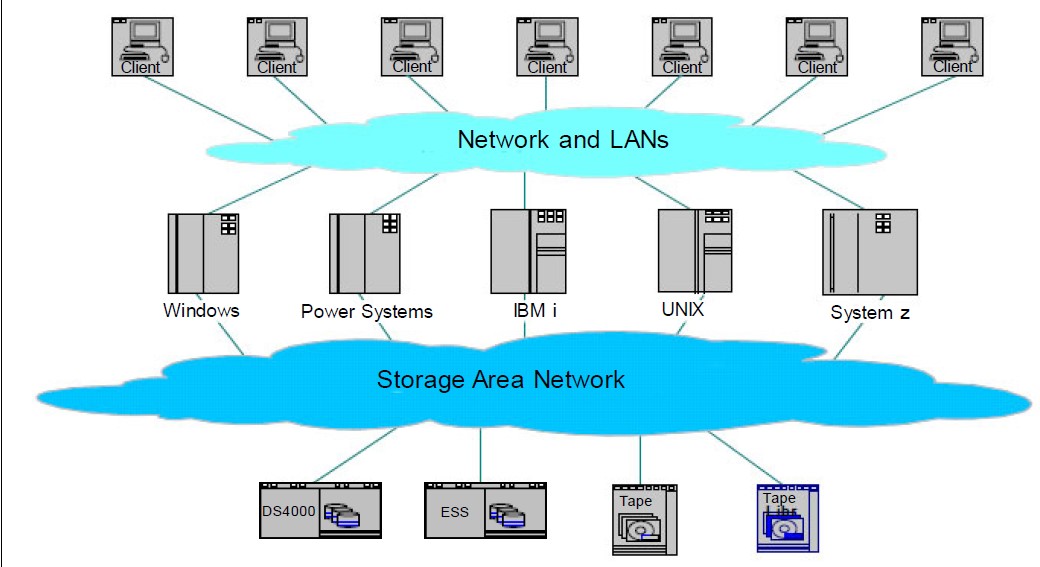 SANs create new methods of attaching storage to servers. These new methods can enable great improvements in both availability and performance.
SANs create new methods of attaching storage to servers. These new methods can enable great improvements in both availability and performance.
The SANs of today are used to connect shared storage arrays and tape libraries to multiple servers, and they are used by clustered servers for failover.
The SAN is an evolution of the DAS. Advantage: isolated central mangement.
Network attached storage.
NAS is a dedicated storage device, and it operates in a client/server mode.
It is connected as file server to other servers and clients via LAN.
Properties:
- Protocol: NFS (or CIFS) over an IP Network.
Network File System (NFS) ? UNIX/Linux
Common Internet File System (CIFS) Windows Remote file system (drives) mounted on the local system (drives)
Evolved from Microsoft NetBIOS, NetBIOS over TCP/IP (NBT), and Server Message Block (SMB)
SAMBA: SMB on Linux (Making Linux a Windows File Server)
- Advantage: no distance limitation
- Disadvantage: Speed and Latency
- Weakness: Security
Object storage, cloud.
👓 From IBM:
IBM Cloud Learn Hub - Object Storage
Objects are discrete units of data that are stored in a structurally flat data environment. There are no folders, directories, or complex hierarchies as in a file-based system.
Each object is a simple, self-contained repository that includes the data, metadata (descriptive information associated with an object), and a unique identifying ID number (instead of a file name and file path).
This information enables an application to locate and access the object. You can aggregate object storage devices into larger storage pools and distribute these storage pools across locations.
This allows for unlimited scale, as well as improved data resiliency and disaster recovery.

IO performance improvement strategies.
The choice of what hardware is a sufficient fit for business usage, is under pressure of misunderstanding in the application stack.
The application stack is setting a lot of requirements on the technical infrastructure.
Page space, system work, scratch area, application work.
⚙ The "page space" is
A page space is a system data set that contains pages of virtual storage. The pages are stored into and retrieved from the page space by the auxiliary storage manager.
A page space is an entry-sequenced cluster that is preformatted (unlike other data sets) and is contained on a single volume. You cannot open a page space as a user data set.
The os system administrator responsibility. A DAS is the best fit, there is no need for backup this kind of data.
There are more storage area&actues like this, a limited list:
⚙ syswork /tmp %temp% - Storage that is used for temporary purposes, there is no need for backup this kind of data.
It should perform very well when used in the spplication stack expecting that. The sizing of these storage area´s is a problem for agreement. A DAS is the best fit.
⚙ scratch area, scratch space, saswork, java-temp - These are all dedicated storage area's for temporary usage for a dbms, a tool or virtual machine.
They can have a preformatted layout (dbms). The content is not useful for a backup. A DAS is the best fit.
Common sense how to achieve good performance when the hardware is understood is needed. The temporary data is one to configure appropriate at the administration of the tooling.
Use of intermediate data is not always visible neither form the OS administration perspective nor from business application.
When this component is behaving badly the solution needs understanding of the root cause by several involved parties.
Practical cases from others are helpful. Papers to underpin assumptions and giving more advices what to do.
The location of the directory used to hold temporary files is defined by the property java.io.tmpdir. The default value can be changed with the command line used to launch the JVM.
Changing the value at start-up:
java -Djava.io.tmpdir=/home/../temp
Striping.
When you have the hardware and the tools on the machine, you want it to be used efficient.
Parallel processing is the way to achieve that. A Word in that context is striping. Just a paper full of advices:
Optimizing SAS on Red Hat Enterprise Linux (RHEL) 6 & 7
When you construct a logical volume segment from a volume group containing multiple LUNs, by default, LVM takes each successive LUN and appends it logically to the end of the prior one.
This is known as a concatenated volume. This behavior makes it easier to remove a LUN from LVM but can be a serious performance bottleneck.
The reason is if there isn't enough parallel activity across the file system then only certain LUNs will be performing I/O while others remain idle.
⚠ Managing the size of storage is more easy when ignoring the performance throughput. Because of that it will be a preferred method by storage managers not the preferd one when operational using.
SAS processing puts a huge demand on the I/O subsystem.
It is extremely important to make sure you have excellent connectivity from many / all sockets of your servers. When multipath I/O is available it should be utilized.
There are several approaches for the scratch storage work and utilloc.
A restart of an process in coded as an option and describes for operations is hardly done. A full job restart is more convenient.
Customers who seek even more performance at the cost of losing re-animation ability and additional IT management can create local SASWORK file systems on each node.
There is no question that a local SASWORK file system (when given the proper I/O resources and configuration) can outperform a shared file system.
The local file system should be XFS. Again, you have to weigh the pros and cons.
concurrent IO
Other words are Direct IO (DIO), concurrent IO (CIO). These are better known from tuning a DBMS DataBase Management System.
The DBMS know more about what data is changed and expected to be necessary. The system will perform better when the DBMS does the caching an not the operating system.
Old mainframe didn't have any caching for IO because memory was scarce. A modern OS Linux Windows will use all avalaible internal memory.
There are options to change the caching by the os.
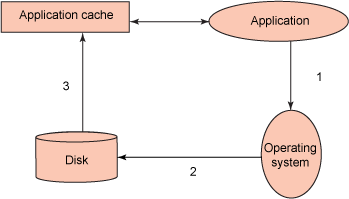
👓
As was mentioned previously, an Inode lock enables write serialization at the file level to maintain data consistency in the case of cached I/O and direct I/O.
Concurrent I/O bypasses this Inode lock and allows multiple threads to read and write concurrently to the same file.
Figure 3 shows the following steps for how concurrent I/O works.
The application issues request for data.
The operating system initiates disk read.
Requested data is transferred from disk to application cache.
⚠ Note the possible contention on Inodes, that are the directory entries of the datasets / file.
⚠ Caching by the OS can cause an delay in when the process is ready and the process is allowed to stop by the os.
All updates of files have to be finished, that is the wirtes in the cache must have taken place before ending the process.
The timing of data integrity and availabilty can cause surprising issue´s.

OS performance - Executing & Optimisations.
Pattern: Plan the expected hardware usage (cpu memory) by the types workload.
Every workload is unique by used os, tools and business applications. For a well behaving system the alignment of all components tools and intended usage in considerations.
Starts having some idea what is necessary and than choose hardware accordingly. Don´t start with hardware hoping it will do.
⚠ Keep in mind that there are also storage requirements in the connections to scratch storage and the external permanent storage.
Pattern: Plan the expected scratch storage usage by the types workload.
Scratch storage is needed when running workload for many reasons. Some adjustments can be postponed until the moment they are becoming critical.
Not wanting to get an overloaded machine, monitoring resource usage is necessary.
🤔 Coding guidelines for Business: considerations in code logic and the impact on scratch storage.
Pattern: Plan the expected permanent storage usage by the types workload.
Permanent storage for the business can have varying requirements in time. Not only size and perfomance but also those of becomin unchangeable and archived.
⚠ May be several locations for different types is a better solution than having it all on the same location.
Moving data wiht the goal of making it readonly will work better when the storage location is the same.

Forgotten history.
Performance & Tuning once upon a time was an important skill. Assuming it does´t matter has lead of ignorance of the basics.
🚧 Systems going into a
thrashing behaviour not being recognized in 10´s. Not experienced as problematic as at sometime desired processing is finished.
Avoiding thrashing using queue´s for load-type and implementing load balancing were basic skills using mainframes in the 80´s.
🚧 Tempory work data- internal memory.
When internal memory grew into a size not that scarce anymore, temporary storage could moved into internals memory.
Using a system driver simulating a storage device is fast, very fast.
⚠ A problem arise when the operating system is running out of memory and moves pages to external storage, paging page.
When the page is needed again the OS/application has to wait for getting that page back.
A multiuser application waiting for IO to complete is not nice.
✅ Having SSD based on the same components like internal memory the spinning delay of classic hard disks is eliminated.
✅ Using data segments not part of the operating system but data segments of user application that is granted to have use that memory (isolated) is no problem.
Modern analytics systems are loading all data into internal memory and than do the processing.
🚧 Algorithmic plans IO usage
Using SQL and packages for some language is hiding what is going on in the machine. A SQL cartesian join,
A cartesian join is a multiple-table query that does not explicitly state a join condition among the tables, it creates a Cartesian product.
A Cartesian product consists of every possible combination of rows from the tables. This result set is usually extremely large and unwieldy, killing application performance.
How was this solved in the old days with scarce computer resources?
❗ The
"balance line" algorithm is the best.
A join of data that are both sorted in join order is the logical approach. A DBMS will do that with SQL when possible and guided by indexes and the way data is stored.
Dependicies other patterns
This page is a pattern on OS performance.
Within the scope of metadata there are more patterns like exchaning information (data) , building private metadata and securing a complete environment.
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.