
Using defined Jabes Metadata
J-1 Concepts & Basic standards
Patterns as operational constructs.
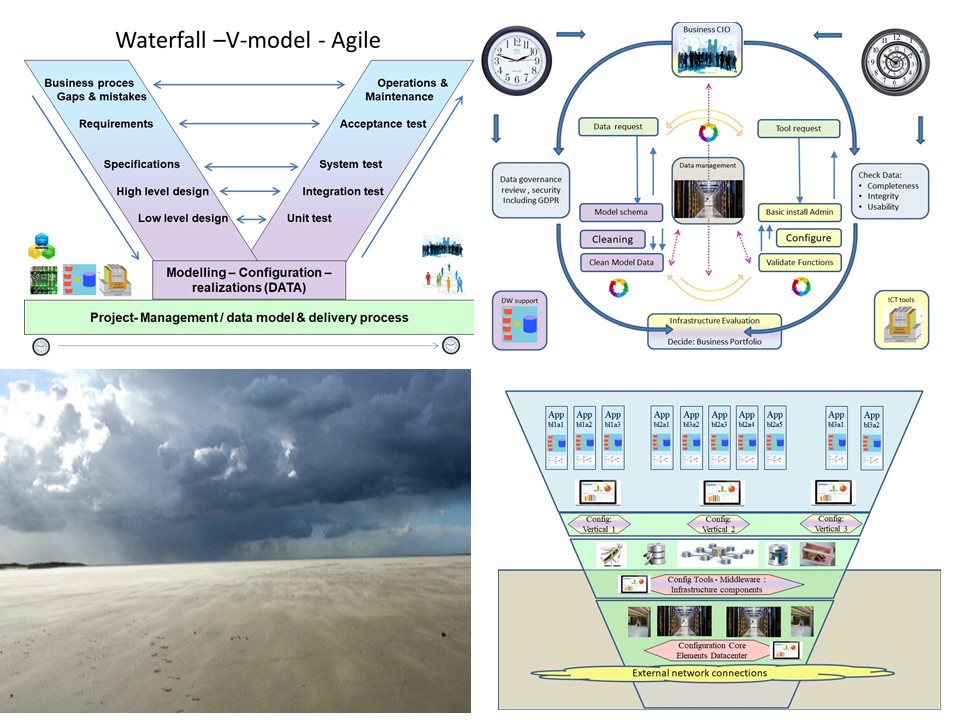
Doing implementations of solutions is normally using building blocks that have been used before.
The first thing understand the reasoning of those building block patters.
This requirement in understanding is always needed. No matter whether get bought or build in house.
🔰 Too fast ..
previous.
⚙ J-1.1.2 Local content
🎭 Y-1.1.3 Guide reading this page
Why is Jabes interesting?
Everybody is looking for a solution to mange the challenges with information processing.
As far I know there is nothing on the market for solving those challenges.
There are many tools for detailed topics but no one covering all the interactions.
Where to start in the existing organisational culture?
There are several issues:
- Starting with a framework and tools without having the problems understood will not solve those problems. (Needs are not clear)
- Alignment tot the missions by visions is impossible when they are not clearly defined or not well explainable. (Values are not clear)
- Holistic functionality knowing how the flow of work at operations on the floor is lacking. (Principles are not clear)
- Deatials functioning knowing how the work at operations on the floor is done, is lacking. (Practices are at the level always has been)
SIMF: the creation and optmizing cycle
As a building block for controlled improvements the SIMF cycle is understandable.
The real value of this is only seen in the system as a whole.
Understanding the eight deliveries by the anatomy by their goals and activities:
- 1,2,3 geomappped roles by functions persons supporting the value stream
- 4,-,9 Profitable value streams by a well managed portfolio.
- 6,7,8 Technology for the product, service.
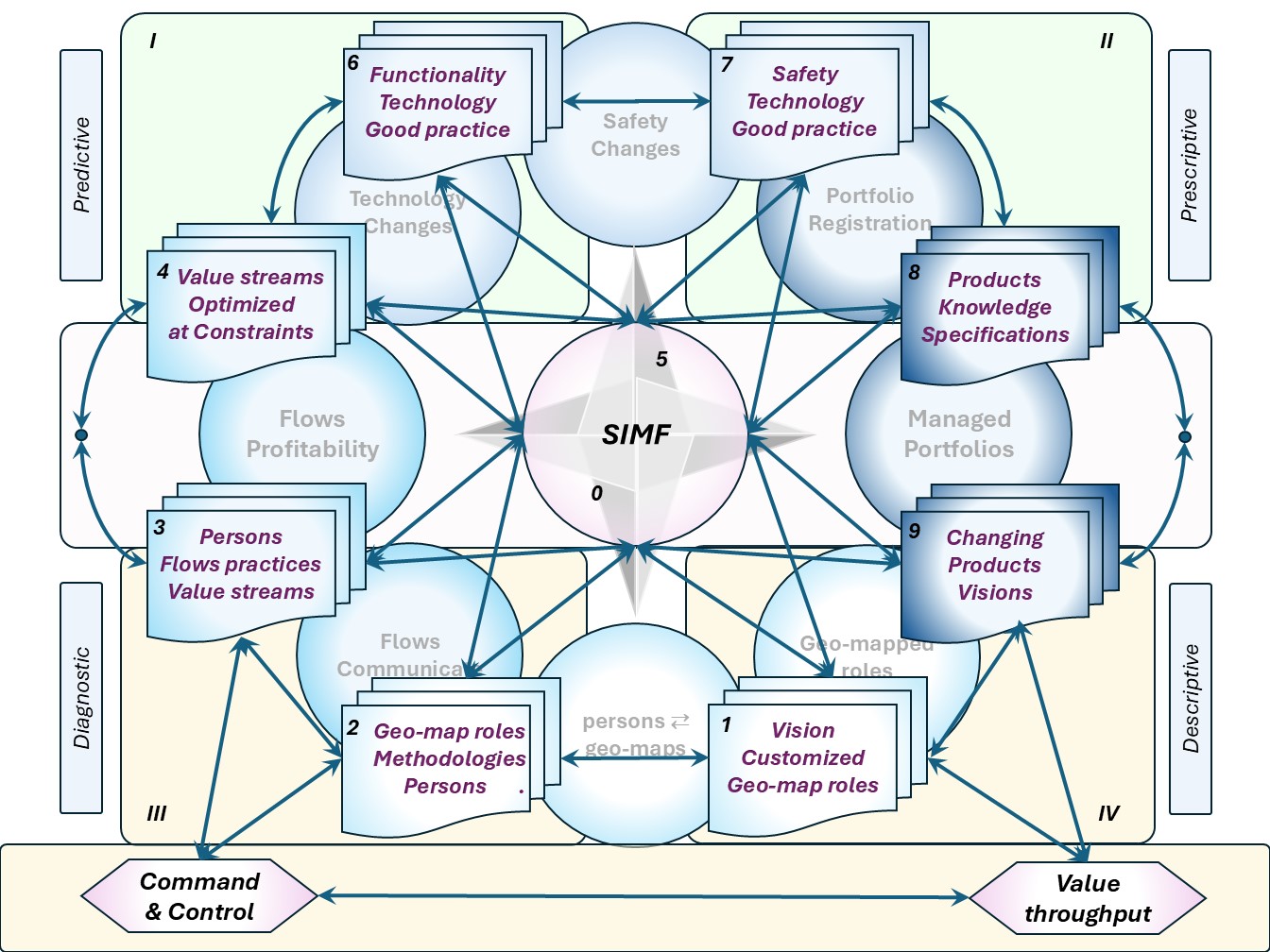
in a figure:
See right side.
The real value of this is only seen in the system as a whole.
Applicable for:
✅ Internal process improvements.
✅ product purpose usage improvements.
When portfolio management is critical than why there are no products nor standards for it?
💡 The Jabes idea and proposal is covering that including change.
Jabes building up understanding metadata Scontexts
As a building block for controlled improvements the SIMF cycle is understandable.
- Metadata describing geo map roles (DDES) data definition enterprise structure ,
Mapping persons to geo-map roles practical content
- Information metadata glossary data dictionary masterdata (DADD), data administration data dictionary
content of master data, describing the structure of information
- Information processing functionality PPIC from free mind idea,
content of how information transformations are processed
- Details PMIT from a Word approach, platform machine information transformation
metadata for describing information technology platforms
⚒ T-1.1.4 Progress
done and currently working on:
- 2024 week 48
- Moved all old content to data devops
- Ready to put Jabes meta content here.
Planning, to do:
- Getting to the word document for Identifications enabling trade
- Getting to the word document for platforms
- All other content to add

J-1.2 Goal & Principles
The Jabes goal is:
- Bring information processing to a higher maturity level.
- Enable what is done for information processing to get understandable documented.
- Enable better continuous improvements of organisations by using more mature information processing.
These goals seems to be that very common sense logical that the question is: why is this not already done?
🔰 J-1.2.1 What are the issues with information processing?
The challenges with inoformations processing are numerous.

J-1.3 Identification naming standard
Jabes was triggered by the question how to implement a new version of a tool in a controlled planned way.
Changing the portfolio by an update an obvious action.
A glossary and data dictionary not needed by the limited number of involved persons.
What was not realised as "Proof of concept":
- 👁 Important in all cases is a well understanding by all being involved by a shared "glossary" shared "Data Dictionary" (DD).
- 👁 Important is also that the maturity of tthe product and/or process is measurable.
Doing changes improvement without any feedback on the achieved impact is a walk in the dark.
Important in all cases is an accepted method of standard recording of what has been executed for the documented achievements.
🔰 J-1.3.1 Understanding Logic, Concept, Context
A good understanding is a prerequisite. A attached list of used definitions is a common approach.
J-1.4 Foundation & commercials
The knowledge of the Jabes metadata and framework should not be closed.
The split in a Foundation for regulation supervision and commercial usage result into:
- The non commercial Foundation being a requirement.
- Knowledge maintained by the Foundation to be open source.
- Funding of the foundation is mandatory by commercials that will use.
There is an impediment by dependicies by this to start building Jabes.
🔰 J-1.4.1 Recap basics Jabes mindset
⚒ The V-model, Concurrent engineering.

J-1.5 Spin offs - preliminaries
Jabes is not a silver bullet for everything. A lot is to use from other sources.
Some ideas for: Spin off, addons:
- Tools adding functionality
- Maintaining information in a 3*6 canvas conform Zachman.
- Metadata artifacts for BI reporting
Preliminary is a knowledge wiki "data dictionary", " data glossary".
💡 J-1.5.1 Adding visualisations and other tools
Example: a software solution showing marvellous visualisations
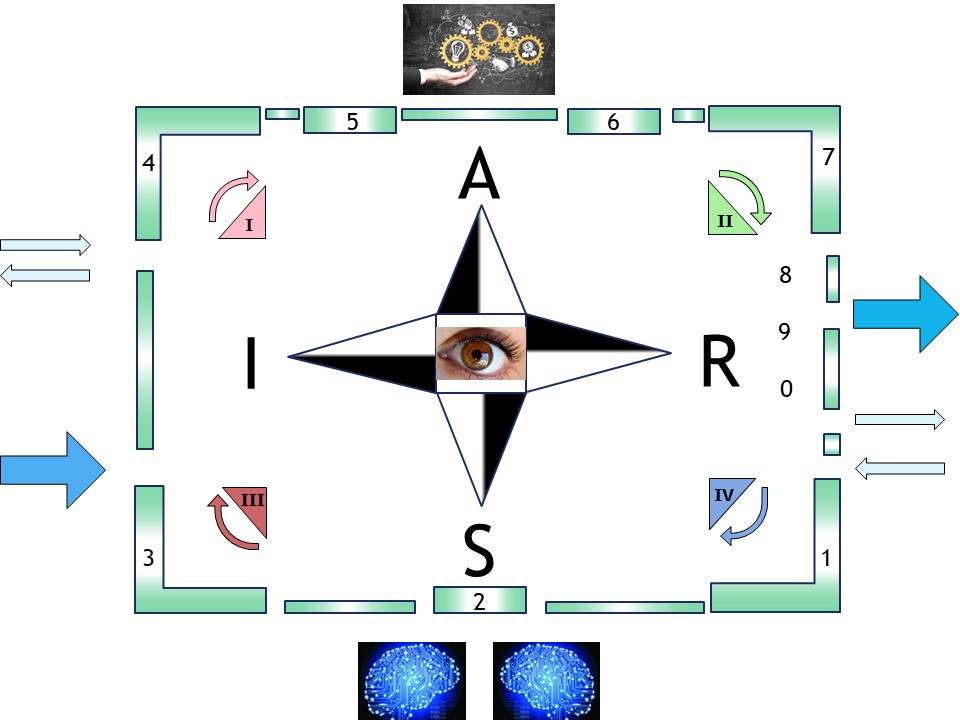
J-1.6 Jabes maturity
The ecosystem Jabes is about:
- Foundation: Several metadata frameworks
- Foundation: regulation and supervision on usage
- Commercials: trade by interactions exchange at content
- Commercials: maturity auditing of product & processes
The components are all by bootstrapping artifacts using metadata having a maturity level.
Functionality building up by bootstrapping completing and improving continously.
👁 J-1.6.1 The organisation in a nine-plane
Interactions are either instructed by autority (vertical) or by regulated work alignment at the same context level (horizontal).
Y-2 Jabes Metadata

J-2.1.1 Demand: backlog, proposals, issues
Building a product for storing, manipulating, export, import, information requires a data model and a metadata model.
Metadata for PMIT (technology) , PPIC (information value stream) are the ones most appealing.
🎭 J-2.1.1 Knowing what is going on
⚒ Knowledge: prodcut specifications
Y-2.2 Design: product building - validations
Building a product for storing, manipulating, export, import, information requires a data model and a metadata model.
Metadata for PMIT (technology) , PPIC (information value stream) are the ones most appealing.
🎭 Y-2.2.1 Change initiation
⚒ Activating teams for a change
Y-2.3 Build: product & validate
Building a product for storing, manipulating, export, import, information requires a data model and a metadata model.
Metadata for PMIT (technology) , PPIC (information value stream) are the ones most appealing.
🎭 Y-2.3.1 Product build realisation
⚒ Realisation - validation execution
Y-2.4 Consolidate into specifications - operations
Building a product for storing, manipulating, export, import, information requires a data model and a metadata model.
Metadata for PMIT (technology) , PPIC (information value stream) are the ones most appealing.
🎭 Y-2.4.1 Product service evaluation
⚒ Evaluation of the new product

Y-2.5 Decoupled ERP connections
Having a product, Jabes, that supports life cycles of:
- Technology: Platforms - middelware tools,
- Functionality: Information / data products,
- Product: portfolio complete with specfications,
- Product: construction usage instructions,
is no guarantee of correct usage of the Jabes product.
Knowing what to do, what has been done, is important information for improvements in the life cycle processes.
📚 Y-2.5.1 Completeness of metadata artifacts
Adding ERP & maturity
Y-2.6 Jabes Metadata maturity
The ecosystem Jabes is about:
- Foundation: Several metadata frameworks
- Foundation: regulation and supervision on usage
- Commercials: trade by interactions exchange at content
- Commercials: maturity auditing of product & processes
The components are all by bootstrapping artifacts using metadata having a maturity level.
Metdata building up by bootstrapping completing and improving continously.
⚒ Y-2.6.1 Cargo Cult
Pretending being in control

Y-3.1 Muda Mura Muri
Going for lean, agile, doing more with less is mostly about cost saving. Only having the focus on cost saving is not real lean.
The leading example or lean is TPM, toyota car manufacturing (Japan). That approach embraces avoiding evils. Similar to the "law of conservation of energy" there is "law of conservation of evil".
🤔 waste, the only problem ❓
⚖ Y-3.1.1 Enabling motivating the workforce
Work to do: solving cultural challenges by their root-causes.

Y-3.2 Technology
Only having the focus on IT4IT, getting a mature Technology Life Cycle Management (LCM) requires understanding an acknowledgment of layered structures.
Understanding an acknowledgment of the ALC-V* types .
Dedicated characteristics for:
- This technology pillar
- Each layer in this technology pillar
- Way to manage this technology pillar
⚖ Y-3.2.1 Technology enablement
There are several challenges. They are a complex myriad on their own:
Y-3.3 Information (organisation) and Technology
Combining IT4IT with then organisation requires mature alignment of Process Life Cycle Management.
Acknowledemtn of hierarchical and matrix structures.
Understanding an acknowledgment of the ALC-V* types.
Dedicated characteristics for:
- This business / organisation pillar
- Each layer, ALC-V*, in this business / organisation pillar
- Way to manage this business / organisation pillar
⚖ Y-3.3.1 Enable the organisation using technology
There are several challenges. They are a complex myriad on their own:
Running processes for missions
Y-3.4 Information Communication and Technology
Optimizing an organisation is also optimizing their products.
Analysing value streams, analysing financial options with predictions, preferable prescriptions, are required activities.
Understanding an acknowledgment of the ALC-V* types.
Dedicated characteristics for:
- This reporting & analytics pillar
- Each layer in this reporting & analytics pillar
- Way to manage this reporting & analytics pillar
⚖ Y-4.3.1 Enable the organisation using technology
There are several challenges. They are a complex myriad on their own:
Supporting running processes for missions

Y-3.5 Visualisation Inquiry & Auditing
Measuring the maturity for a scope goal is the way to go.
Scope at a high level reflects:
- ✅ culture, organisation, vision
- ✅ operational mission: value streams
- ✅ state of the art technology
Note there is perspective change for evaluating maturity.
The mentioned aspects are behaving quite different when wanting to measure them using some metrics.
Different visualisations are needed for eauy understanding.
👁 Y-3.5.1 "culture, organisation, vision" What to measure?
Determining Maturity (CMM) in a dashboard
Y-3.6 Maturity of Maturity
The ecosystem Jabes is about:
- Foundation: Several metadata frameworks
- Foundation: regulation and supervision on usage
- Commercials: trade by interactions exchange at content
- Commercials: maturity auditing of product & processes
The components are all possible build by bootstrapping. Bootstrapping will create many versioned results.
Metadata artifacts have a maturity level by improvements.
Maturity building up by bootstrapping will be completing and improving continuously.
⚒ Y-3.6.1 Maturity scopes
Pretending being in control
👁 J-3.6.5 Following steps

These are practical data experiences.
technicals - math generic - previous
data, generic toolings 👓 next.
Others are: concepts requirements: 👓
Data
Meta - including security concepts - Math
© 2012,2020,2024 J.A.Karman