
jakarman - ICT - My profession
D-1 Who I am, the early years
D-1.1 Contents
D-1.1.1 ⚖ What there is at this page
The infromation factory
The mindset for a circular flow must always have been in my mind. Similar to a factory the value stream left to right but the question on what to do right to left.
Just rather recently I made this visualisation. The kind of passion is not an easy position, changing and not blind following is not appreciated in social groups.
Pull: 0 ,1,2,3
Demand request
Push: 4,5,6,7,8,9
Delivery result
Value stream materials: Left to right
See right side:
D-1.1.2 ⚖ Local content
D-1.1.3 ⚙ Progress
- 2024 week 35
- Redesign of this curriculum vitae page. Converted into something that is similar to the Foreword.
The change of 2020 redesigned
- Added specials in what has been done, relocating old content.
- Added the start of Jabes. Running and changing a portfolio conforming standards.
- 2024 week 37
- A first draf version, publised. Freeing up content at devops/sdlc r_serve page
D-1.1.4 ⚙ jakarman, ICT - My way of thinking

In my working lifetime there are many periods while changing the technical details and changing attention to issues I did want getting solved.
There is gap between the passion and what was possible getting done.
Not being dependent anymore for payments gives the freedom for sharing proposals that are not conforming to usual commercial interests.
👓 link for proposals introduction.
D-1.2 Entering ICT areas (I)
D-1.2.1 ⚒ IVO (ISS, Individual Sales Support)
📚
The business goal was delivering pc´s to the sales people (600) at their home having all the information they needed for their customers (1984).
🎭 The available technology was:
- pc´s were just coming at affordable prices into the market.
Specificiations: processor 8086, memory 640Kb ram, harddisk 10Mb, OS PC/Dos 2.1.
- Connected to an IBM mainframe, screenscaping Irma 3270 cards.
- A modified Viditel modem 1200/75 bps. Calling out to the pc´s at home.
Planned schedule time in evening hours.
Operational limit duration 4 hours.
- Controlling environment by classic operators. Task within the middleware IDMS DB/DC.
- Using languages: batch script, Assembler, C, Cobol, ADS (IDMS).
⚙ What was done:
- Building Implementing and supporting the protocol for the data exchange between pc´s. Optimized within technical limitations switching directions being 0,2s.
- A b-tree (no_sql) like dbms was build in C for doing the DBMS fucntionality. Extended maintenance was done in indexes and data blocks, improving performance & reliablity.
- Connecting PC-world to Mainframe with dedicted calling out pc´s.
- Supporting developers testers, a dedicated helpdesk and edcuational staff.
D-1.2.2 ⚒ Performance & Tuning, Mainframe
 📚
📚 The goal was setting up, delivering Management Infomation (MIS EIS) by applications and tools in system resource usage.
Multiple goals:
- Pinpointing on possible issues that could be improved, delaying exteral investments
- Enable to plan, JIT, costly hardware upgrades
- Cost accounting to the several cusiness lines based on measured usage.
🎭 The available technology was:
- Needing to aqcuire tools. Chosen was SAS (5.17) with MXG to process the SMF records.
- Configuring adjusting settings for the SMF record processing.
- In house available scheduling and system resources.
⚙ Having done:
- Building up a weekly PDB (Performance Database) in several incrementals.
- Weekly archive and cleanup. Cost account minimized and summarized weekly.
- Appending summaries into a SDDB (System Data Database). Cost account summary added.
D-1.2.3 ⚒ JST, structuring JCL (Job Control Language)
📚 The goal a structured practice enabling JST.
❶ JCL is the script language coding tool in a classic IBM Mainframe used to run processes for the business.
Before you can do anything to optimize the JCL process running business processes you must structure the way of how JCL is coded.
 ❷
❷ It has a huge advantage in disconnecting the physical data reference out of source code to this JCL storage location (punch cards).
What you do by that is defining which data should be used on the moment the job is run, JIT (Just In Time).
❸ Any business software, logical program, can be reused in the DTAP setting without modified application code.
Avoiding not necessary modifications in business software (production, acceptance) is a quality and compliancy requirement.
🎭 Available technology and information source:
- An integrated technical development environment: TSO (time sharing option)
- Electronic datasets contiaining the converted hollerith punchcard JCL scripts
⚙ Having done:
- designed and implemented procedure patterns (JCL)
- designed and implemented at procedure patterns Input Output components
- With the Output patterns a dedicated pattern for printing output
D-1.2.4 ⚒ JST, a Generic approach for automated testing
 📚
📚 It is automating manual work of several IT-staff lines.
This is a very unusual part of IT optimization as it is internal IT.
After all this years I am considering the approach still a revolutionary.
⚖ Experiences:
- With this approach the generating of the statements and the re-usage in development & testing is an enabler to highly optimized process.
🎭 Used technology and limitations:
- The available program language ISPF dialog with REXX running in a TSO environment.
⚙ The solution design and realization:
- Well-designed JCL in a DTAP (Develop Test Acceptance Production) approach.
- The operational execution DTAP approach connected to application DTAP (Endevor).
D-1.3 Entering ICT areas (II)
D-1.3.1 ⚒ Database IDD - IDMS DB/DC
❶ IDMS was using an advanced approach using an "Integrated Data Dictionaries" (IDD-s).
A more modern word would be Multiple contextual Metadata Databases.
An integrated backend (DB Database) with frontend (DC Datacommunication) classified as a tool, middleware.
 ❷
❷ These dictionaries were setup in:
- a master (sys:11)
based from that master a logical DTAP segregated configuration.
- Development (sys:66)
- SystemTest series (sys:88)
- Acceptance series (sys:77)
- Production series (sys:01)
❸ Each of them having definitions:
- Technical definitions like terminals.
- Security eg: users groups and access control.
- Business applications menu tailoring, business logic and data.
❹ Cullinet was the preferred supplier.
In previous years no front end was available from any supplier.
An in house build front-end and middleware system was still running (VVTS).
📚 Goal operational support (system programmer) in a small team.
🎭
Used technology: suppliers Cullinet, CA (1990-s) now (2020+)
Broadcom and IBM toolset.
⚙
What was done:
- Automating generating definitions, versioning releases.
- removing home build exits, testing combined with JST.
- Supporting developers and testers in achieving their goals.
D-1.3.2 ⚒ Security (ACF2 RACF - MS AD )
❶ Bringing structured access to resources by roles, organizing who is allowed to what role and getting it to some natural person verifying really who is saying he is, is known as security.
There is a master security administrator task (design) and a restricted security administrator task (executing requests).
This is a required by segregation compliance in duties.
 ❷
❷ The old common approach is doing user input validation before handing over to the tool.
This was done by lack of integrated security.
❸ The dark background has become very modern again recent years (2020).
The limitation was that number of lines * columns was limited, often used sizes were: 80*24 and 132*27.
The screen from the image is an example how TSO did look like.
The user interaction for any application had to be intuitive according to user expectations in the same approach.
Any modification to this kind of tailored menu had to be organised.
📚 Goals implementing security with tools:
- Manageable explainable centralized security.
- Monitoring with Incident Response. It are the fundaments for:
-
just because two organizations both call their response team a CSIRT ,
for example, doesn't mean those two teams have the same goals or methods, or conform to an idealized definition.
-
ENISA CSIRT maturity framework is taking into account requirements of relevant EU policies (e.g. NISD).
🎭
Used technology: suppliers "ADR" later "CA"(Broadcom), IBM, Microsoft (AD).
⚙
What was done:
- Collaborated at the design of logical acces, aligned with DTAP policies (ACF2).
- Collaborated in the transition moving from Roscoe to TSO, implementing ACF2.
- Build ae tool to support in quick roll out for all involved platforms changing access rights.
D-1.3.3 ⚒ Scheduling (UCC7 TWS - homebuild)
 ❶
❶ Scheduling Jobs in the old times was all manually hard work. Operators had to carry all the physical paper cards in time to the readers to execute them.
Planning was done as preparations on paper using previous experiences on load and durations.
The operator was the person you should be friends with.
❷ This all changed when that work became automated and shifted for some parts to persons inside the business (functional support, production support).
❸ There is big shift in time impacting jobs.
Many kind of jobs have gone and replaced by others in the era of applying computers AI ML.
📚 Goals:
- Replacing manual activity by a robot program (scheduler).
- Reducing failed deadlines for job readiness by learning and predicting what is going on. Being aware in daily weekly monthly runs.
🎭
Used technology and limitations:
- UCC7 later CA7 was the CA scheduler, it was the first one being implemented.
- Tivoli (TWS ppc) is the replacement delivered by IBM replaced the CA7 software.
- There are many more options to trigger jobs. JST was home build just using standard tools.
⚙
The realization was being adjusted in level of acceptance at departments.
D-1.4 Lean processing TOC = JST: Job submit tool (I)

D-1.4.1 🚧 The situation, analyse the floor for improvement
The JCL JOB guidance Form (JBF)
❿ Working on the middelware for changes I found myself blocked by some jobs running.
I could not figure out who was running them. At that moment I knew the Operations (OPS) and "production support" (PB) teams well, so I went to them asking what those jobs were.
That is the moment I got to learn the work of the "permanent test group" PTG group.
There were not that many PTG persons. One person of the PB team being busy there.
❶ The PTG persons had to fill a hardcopy paper "test request form" (TRF), using a lot of correction paint.
The PB person used that, making notes on it to create Jobs to run for that group.
The throughput limit was about 100 jobs a day.
❷ There was another hardcopy paper coming in from the Development department that described how the programs were supposed to be used with a lot of details on how data was defined (JBF).
When the papers were found to have wrong information the paper had to go back and being corrected before further processing.
There was no business analyst for processes at ICT.
JCL JOB guidance Form (JBF)
❸ Found this form as guidance for workers and then got these questions:
- Why?
- Possible improvements?
- Who can help?
- What can I do?
- When to do it?
The answers for myself to start change by taking the initiative:
- It was historical grown
- remove the form by trying to automate in what is in there
- Allowance of managers team leads at involved departments
cooperation with workers at those departments fro changes
- I could build a tool for submitting those jobs.
- Just start and do what is acceptable to most of te involved persons
D-1.4.2 💡 Starting simple improvements
The often used jobs for testers (Pareto)
❹ I got some time and cooperation for doing a little small things.
PTG was willing to do more themselves, the generic data preparation and reporting jobs mainly used for test as test tools too start with.
❺ Interesting discussions started on whether:
- Test tools did have a DTAP life cycle or not
- Hard coded data in code made it business logic where it was logical data
- Datasets intended to implement business logic made it not belonging to data it was and is real logic
- Where testers allowed to operate jobs themself or not.
In that era the operator was the only person having access to the expensive computer.
Terminals were just getting rolled out.
- The democratization everybody becoming the operator.
Structuring JCL, a requirement along with operations (JCL2000)
PTG needed more time for acceptance new things, but that other form paper was bothering me.
I found an ear at the PB department to improve that process.
❻ When all jobs would be build in a standard common job approach it could be automated.
The question was what the best and acceptable option for new standard JCL coding would be.
We made several examples of possibilities doing steps in normalisation.
Showing this to other persons the most structured one was surprisingly acceptable preferred.
👁 Explaining it to another PB person, as soon he did understood the intention, he wanted to start changing.
We were not ready at that moment.
Of course not everybody did like it, but we could go on.
D-1.4.3 ✅ Starting simple improvements
All kind of batch jobs for testers additional tools (compare)
❼ Running the test by PTG rather well additional questions were asked.
Some of those:
- Can we archive (backup) and restore all data for a test plan ourself?
That includes a lot: databases input datsets and results.
- Can we have some tool to compare the results of several test jobs?
 ❽
❽ Backup restore tools for test activities.
These are coming in with the operating system.
We delivered those backup & restore as system support to the OPS department.
Using those tools also at the test group was not that difficult at that moment.
Comparing data is included in TSO/ISPF environment.
The compare tool could be automated when the data, results, is in datasets.
Automatization of automation engineers.
❾ Covering all of the DTAP, Development, Test, Acceptance, Production, combined with release management by header and trailers.
The organisation did work with a DBMS.
Release management tools and manage releases were there and got replaced.
D-1.5 Structuring practices = coding guidelines, JCL2000 (I)
D-1.5.1 🚧 The situation, analyse the floor for improvement
The JCL script pattern challenge
The main technical issue and question was structuring JCL so it could be automated and reused.
The tool was build with TSO/ISPF using REXX at no additional cost with those common available tools.
The structured approach is very generic. At Quality Assurance it is applicable.
A disadvantage: naming conventions and standard way of work are characteristics. A technical solution is not easily copied into another organisation.
The JCL script pattern glossary
Defining all globals, job environment settings by artifacts:
| symbol | meaning | explanation |
 | Header or Tail | Defining all globals, job environment settings
Defining actions, jobs after this one |
 | Bodies - Frames | Business logic software application programs
Used by business functional owners |
 | Common procs | Technicals you can reuse very often
These technicals are a limited number of types JCL proc steps |


 | Data Definitions | DBMS definition
Input, Output, Report -log for every step |
Somehow defining the datasets output / print / mail / databases / transfers to be used is needed.
These definitions may not be hard coded in the business logic code. Why not?
- Having them managed in a release process would become impossible.
- Acceptance testing would be impossible using the same artifacts.
D-1.5.2 💡 Starting simple patterns
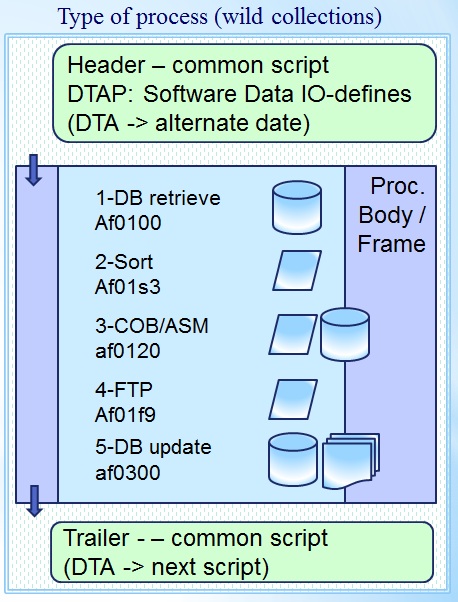
First basic conversion to automatization
Simple using a monoltitic application flow.
Head :
- Joblib statement, location for Business Software Logic.
- Jcllib statement, location:
- procedure Bodies,
- Data Definitions.
- Prefix setting, first levels Data Definitions (DTAP)
- Output destinations (external). Fail safe, security (DTAP)
- Dedicated alternate date for Business Software Logic
Application flow procedure & IO
- segregated or monolithic data definitions
- Unstructured full application flow
- IDE notebook approach
Tail :
- DT(A) usage, triggers next process, next actions.
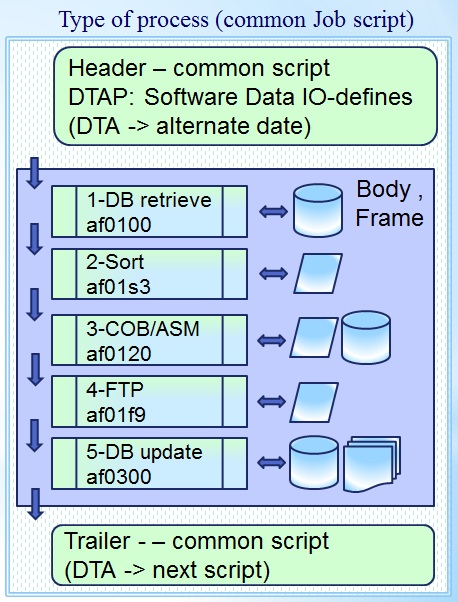
Normalised basic conversion into automatization patterns
A modulair proc step in this way is like an api (program interface) options.
The normalising of the data into segregated components is creating new artefacts.
Head :
- (unchanged)
Application body using procs & segregated IO
- related DBMS data, local datasets, local outputs
- database retrieve application
- database update application
- 3GL Business processing on files
- Information transfer - delivery
Tail :
The word local is used in context to the machine where the process is executed.
Not the location as where the human worker, operator is.
D-1.5.3 ✅ Backups and more
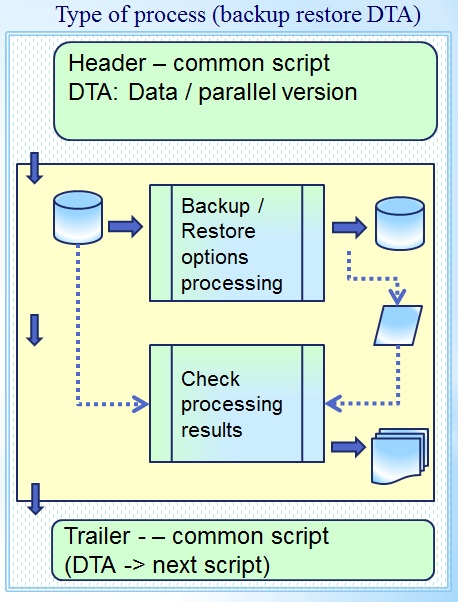
Backup Restore script D, T, A
Backup & restore is essential to D,T,A Develop & Test.
Head :
- Joblib statement, location for Business Software Logic.
- Jcllib statement, location:
- procedure Bodies,
- Data Definitions.
- Prefix setting, first levels Data Definitions (DTAP)
Backup procedure
- Definiton of test environment
Tail :
- DT(A) usage, triggers next process, next actions.
Acceptance environments are important business assets.
- Reason: Evidence of quality (auditable)
- Segregation by naming, environment should be in place
- Verifying content of backups must be possible
D-1.6 Notes: the good bad and ugly - early years
D-1.6.1 😉 Experienced positivity by activities

ISS, Individual Sales Support
This was a revolutionary approach:
- Working home by sales in the era without internet.
- Daily updates replacing the hardcopy mail communication.
- Feedback on gaps additional questions after the next day.
Automated processing at the office no human reading and additional data entry typing of hardcopy prints.
- Opening up the option doing more work more activities with less effort.
Job Submittool - Lean process toc (I)
It survived all years several reorganizations, the year 2000 testing, Euro testing, outsourcing to India.
Created around 1996 after more than 20 years mostly untouched it was still in use.
Job Submittool - Lean process toc (II)
After mare than 20 years it stumbled over: Removing constraints, being Agile. Explaining what I have done a long time ago.
The Bottleneck Rules (Clarke Ching 2018) has a nice story on a development team.
bottleneck-rules-table
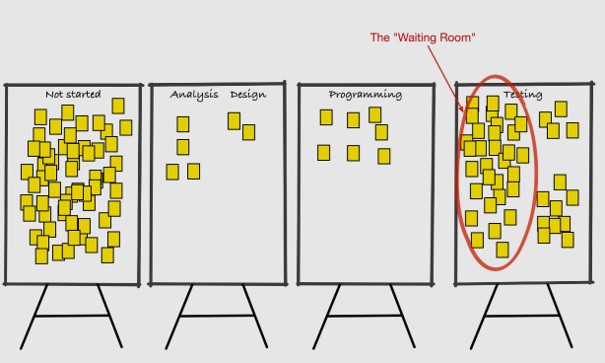
There was a waiting room for work in progress in the flow. Testers could not work faster.
It is mura (unbalance) in the system.
Unbalance and Muri (overburdening) are too often negelected only mentioning waste (muda).
Developers changed tools for testers to improve their throughput.
The end situation, Work got managed by what testers could finish:
- Not too much
- Sufficient they would not run out of work.
Improving the throughput of testers by better tooling is also what JST did.
Even more, there were other bottlenecks, eg at the operations delivery department and some hidden at development.
D-1.6.2 😱 Experienced negativity by activities
ISS, Individual Sales Support
This was a revolutionary approach, it harmed the ones in the culture of "work as was always was done".
The resistance was :
- Not allowed to use its full potential from the concern perspective
- No associated improvements in the automated administration that was complicated silo based.
- Avoiding the dependencies on internal innovations, framing those as out of control.
Job Submittool - Lean process toc
Although the goal was helping in the daily activities of everyone the resistance by some was tremendous.
- The resistance was by techical people was well understandable. The only explanation is passing their borders of assumed competencey.
- In some cases involved people could not manage the change. It was going to fast for them.
- Avoiding the dependencies on internal innovations, framing those as out of control.
Structuring Security
Changing the security from input validation into using standard tools:
- In some cases involved people could not manage the change. It was going to fast for them.
D-1.6.3 🤔 Ambiguity complex uncertain volatile emotions at activities
ISS, Individual Sales Support
This was a revolutionary approach, but never achieved the full potential:
- Distinctive products vor achieving more profitabitity were not introduced.
The only thing done was about efficiency of the existing ones.
- After some years there was a fall back into a following of others mindset.
Job Submittool - Lean process toc
Because of the business optimization that is done:
- The whole is not available as a commercial solution.
- Converting the whole as a commercial solution is hardly possible.
Job Submittool - Test Methodology
All work at JST - JCL was done accordingly to the documentation found at ISTQB.
🤔 However, it was done years before the ISTQB organization did exist.
Just the mainframe approach is what I have documented here. It is according to the ISTQB design concepts chapters.
The JST approach can be used using by any tool in any environment.

Structuring Security
Roscoe was an multi user mainframe integrated devlopment environment, program editor.
The roscoe administrator tried to implement security by parsing and than reject or allow that docuemnted command.
It never succeeded to become reliable, that was in 1985.
Question: What is new?
In modern times we are parsing code, preventing code injection, crating dedciated api's, trying to secure the web browser interface (2024).
D-2 Internal at a big company
D-2.1 Operations planning & executing services

D-2.1.1 🎭 Personal tools & coding preferences
Coding when required
❿ I never had a coding preference, tools middelware.
The only preference is reusing as much what is already in place and sufficient applicable for the case.
It has been:
- 2GL: Assembler, C for the low level tasks needing special attribute or performance behaviour
- 3GL: Cobol, Fortran or whatever what I alike SQL any DBMS or even no-sql, Basic, Java, .NET, python, JCL, bash for any set of basic procedural tasks.
- 4GL: SAS, REXX (ISPF), PowerShell that are combining more to an object approach automating some of labour intensive task of 3GL-s
❶ In project management is a different, there is a step after understanding the problem of the customer, tools middleware selection is done.
This is the opportunity for external suppliers getting a stronghold without any responsibility for results.
❷ Learning PowerShell was only done recently (2022), I felt comfortable when getting realized what the similarities to SAS was.
The metadata for data with SAS is included in the middleware system. Part of the dataset or at a dedicated repository.
For PowerShell it is part of the system there is no dedicated repository. PowerShell has the goal of system administration and is not runed for mass data processing.
Limiting the area scope but extending the scope area
❸ By reorganisations I was forced to concentrate and specialize more on the usage with SAS tools.
An interesting area because:
- Technical installing configuring on alle type of machines was included
- Supporting analysts in a diversity of specialized areas from risk, security, financial to marketing. Those contacts were very interesting.
- Going into requirements for getting safety cyber security more compliant into regulations and guidelines (27K series)
D-2.1.2 🎭 Data modelling
Extending into more structures data flows
❹ The stability of delivering is automating what information is coming into what can be used by the information consumers (push).
What should by delivered is a reaction on what information consumers are expecting (pull).
When the demand variety is high, requests for changes in the delivery will be high.
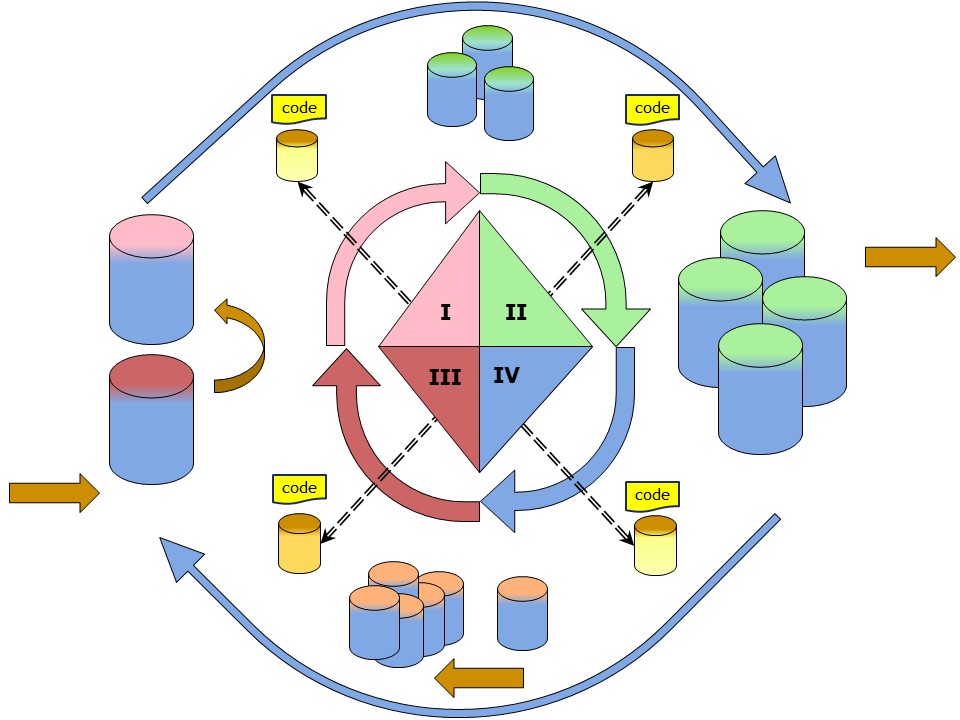 ❺
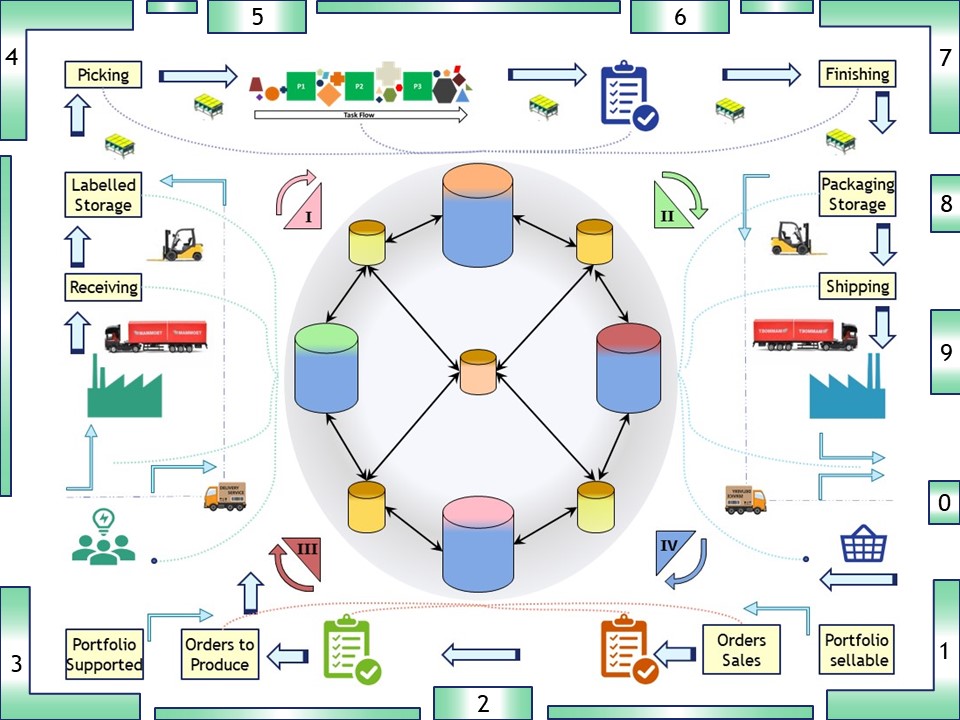
❺ Thinking in a infromation value stream from left to right,
The Information request & delivery in a full pull-push cycle is a little bit different.
The numbering looks not very logical, there is divergence between a linear and circular order.
In four steps:
- I , II push delivery
- IV , III pull request, control
The push was already there. Numbered in that order I, II numbering left to right.
The pull for a flow is added, right to left IV III.
The full operational cycle: IV, III, I , II
Extending to continous & disruptive improvements
❻ In the material flow form left to right both DMAIC (counter clockwise) and PDCA (clockwise) have their place.
➡ possible disruptive change PDCA: III, I, II, IV
It doesn't make sense to start with Plan without first getting insight where to act on. The most logical start evaluating is at IV A (PDC).
Small incremental changes can use the PDCA path.
➡ small improvement DMAIC: II, I, III , IV, IV
The Control step is going together with a next iteration.
D-2.1.2 🎭 Process scheduling
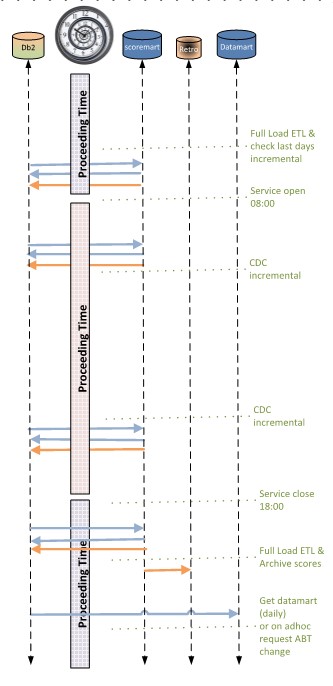
Running information transformation processes
❼ Running the operational processes for the business lines, planned in a way everything is delivered in time.
The mindset in this is completely different to the ones that are trying to do changes.
- Stability - no changes
- Predictable processes, In behaviour for results and load
- secured applications, tools middleware and business
- monitoring is in place
❽ Planning the operations is by using tuned applications in a automated time frame not overloading the system.
The service delivery moment is to agreed with the intended usage. There are several plannings possible to spread the load over a day.
Example material operational flow:
- In the morning, before office hours, a full data load for what is possible accessed used that day
- During office hours incrementals for what is changed are optional added.
Started bij time events for near real time experience or determined logical events.
- In the evening after office hours a full synchronisation is done on all what is possible changed
- Moments shoud be planned with th option that somebody is able to react when there is sometnhing going wrong.
This was extended later more in detail somethimes having the tools and sometimes misssing those.
D-2.1.3 🎭 Deliveries by missions sales, marketing
EIS BI - sales, marketing
❾ Organising deliveries results.
Aside the daily operational planning there is more:
- MIS, EIS, BI, AI 🤔
For Management information systems critical in daily deliveries will be almost never the case.
A daily weekly quarterly yearly moment is more likely to be normal.
- Mandatory regulatory obligations ❗
When there is a high impact to achieve deadlines in regulation delivery deadlines than just in that period the needed service class is high.
- Sales - marketing 😲
Promotional actions, market research, customer satisfactions polls have their own type of planning and load. Their own goals, but impacting standard operations.
D-2.2 Supporting ICT areas (I)
D-2.2.1 ⚒ Hosting, multi tenancy - *AAS - stacks
 ❶
❶ Software As A Service (SAAS) is a great idea.
Implement it by yourself if your requirements are more strictly then can be fulfilled with SAS on demand e.g. cloud services.
Dot it by yourself when you are you are big enough to do a SAAS implementation yourself.
❷ Another reason can be having multiple business lines (tenants) needing the same solution the same application.
Sharing computer resources can bring huge benefits. There is a whole industry based on that.
When doing it wrong, possible risks are also high.
❷ Solving the SAS environment challenges with all my knowledge and experience in all years, it is brought to a much higher level as is common practice.
The approach is valid for all kind of middleware, tools.
📚 Goals
- Defining borders of segregations in logical security.
- Defining release management for used tools & middleware.
- Defining release management for business applications.
- Segregation of duties in support and administration and being part of relapses management while using tools & middleware for business applications.
🎭
Used technology doesn´t really matter, it is about all kind of dependicies in the full stack.
⚙
Having implemented:
- Achieved hosting (*AAS), SAS as middleware supporting a full multiple tenant service.
- Got alignment to security policies. E.g.: implemented "sudo" for dedicated functions.
- A full supported approach for business release management and another for middleware..
D-2.2.2 ⚒ Release management (versioning)
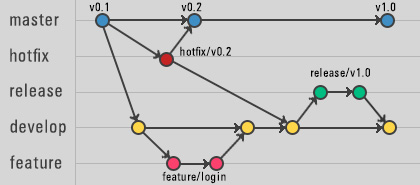 ❶
❶ Within the Information technology guidelines and technics are evolving fast.
However release management for business applications, middleware - tools, ICT infrastructure is still hardly well understood let be acceptable implemented.
A simple example is that Excel maintained by Microsoft is the "application". Question: when excel is the application what is the artifact a worksheet usable in Excel?
❷ Within the Information technology guidelines and the technology are evolving fast. Many tools for release management went along with technology.
Endevor was the one with a lot resulting issue.
Recent hyping tools like GIT are getting the most attention.
❸ A generic DTAP Approach DTAP - seeing the levelled three layers is far more important.
❹ Being in a silo you are having just one layer, your own layer, your own mindset.
📚 Layered DTAP Release management
- Business Applications, business Logic. Segregated from business data.
- Middleware tooling like SAS, a DBMS or managed filetransfer (MFT)
- Infrastructure changes impacting middleware tooling and business applications
🎭
Used technology doesn't really matter as long the goal by release management is met.
⚙
Having done and being involved with:
- A well set up DTAP environment, always required scripting (some language).
- The approvement steps are organisational mostly being managed with other tools (ITIL).
D-2.2.3 ⚒ Disaster recovery, data retention policies

Disaster recovery
❶ The Disaster Recovery, a fall back system, and more for availability are part of delivering a technology service for middleware and tools.
📚 Verifying the assumed DR infastrcuture service:
- Test critical applications using middleware are able to continue.
- Using the alternatives provided by the infrastrcuture service.
🎭
Used technology isn't important, it is about the disaster recovery goal.
⚙
Having done and being involved with:
- yearly DR test planning and executions.
- testing the tools, middleware were functioning in the alternative environment.
Archiving - retention policies
❷ Being compliant at data retention policies is too often ignored. It are basic information requirements that should be part of the system.
📚 Verifying the assumed DR infastrcuture service:
- How long must information kept available at the first line?
- What and how must information archived at a second or third line?
- When should information be destroyed?
🎭 Used technology isn't important, it is about the retention goal.
Having done and being involved with:
- Implementing technical options archiving historicals.
- Simplified the technical realisation enabling relocation.
D-2.2.4 ⚒ Operational Risk (OpRisk),
 ❸
❸ This OpRisk departments and their work is interesting.
OpRisk is doing things like Advanced Measurement Approach.
Using Monte Carlo simulation modelling with public known situations is the way to go.
❹ Required: release management, Quality testing - DR, data retention and security policies.
Delivery deadlines (quarterly) critical moments.
📚 Goals
- A technology IV system that is according to regulatory standards.
- An IV system delivering results saving money at regulatory controls.
🎭
Technology used and limitations:
- SAS 9.1.3 AIX, SAS 9.3 Linux. Licensed under a Solution.
- Oracle connection started in first approach (removed later).
⚙
Having done:
- Installation & implementation according to in house Risk management policies.
- Helping tot run those regular reliable and archiving old versions.
- Support developers: guidelines building & maintaining those special analyses prediction.
D-2.3 Supporting ICT areas (II)
D-2.3.1 ⚒ DWH, BI, Data connections, Unix
 ❶
❶ In a growing environment this topics became the only working area.
The first problem to be solved was a generic desktop roll out for SAS clients as the desktop got another standard.
The next one was adding and consolidation of midrange servers using SAS (see hosting *AAS stacks).
❷ This was a Unix environment (AIX) using a SAN (not NAS). Not that different in the technology approach compared to Linux.
It made to set of experiences at different type of operating systems complete: Mainframe, Windows, Unix (Linux).
📚 Supporting DWH BI Goals:
- Supporting Several business lines not completely abandoning the relatively small office origin.
At the small origin also supporting actuary, marketing (CI) and more.
- Doing the complete release lifecycle support at several layers.
- Getting alignment into security policies, risk managment.
🎭
Used technology:
- AIX, Windows, Mainframes and all dedicated scripting tools
- SAS 8.2, SAS 9.1.3 with several solution lines. SAS/intrnet SAS/AF
- Oracle, DB/2, Sql server SSAS Oros, Samba
- ITIL support tools, schedulers (SAS-WA LSF).
⚙
Implemented:
- With the many siloed approaches, went to a hosting approach, consolidating many old implementations. The ODS and Dwh-s being included.
- Made all kinds of DBMS connections workable and available at business users.
- Changed the SAS Version Version SAS on all systems.
- Conversion of the manual (SAS macro-s) build schedule flow SAS/WA.
- Stuck in blocking SAS datasets behave like any other DBMS (SAS/Share).
- Solved unexplainable errors like the one being caused by the old 16Mb line in memory setting and the single to multithreaded order result effects (2010).
D-2.3.2 ⚒ Policies - Sox-404 ITSM Cobit IEC/ISO 27001, 27002 - GDPR
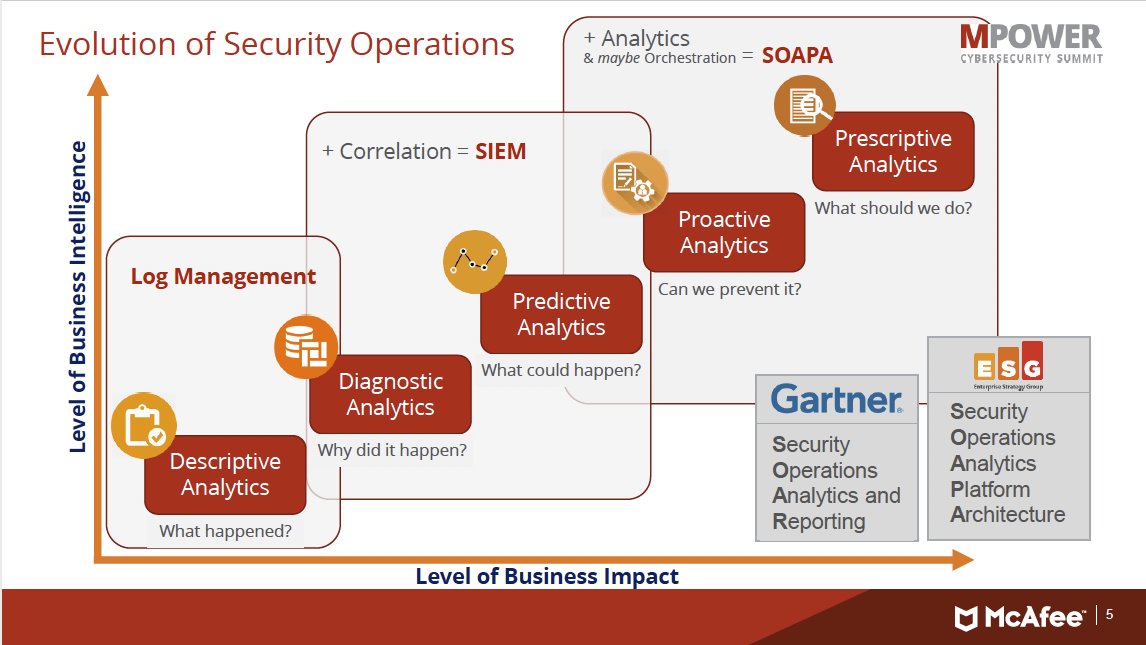 ❶
❶ Policies standards are becoming mandatory (legal requirement), but theres is a lot of work to do.
A valuable figure because very generic:
- What happened? - Descriptive Analytics
- Why did it happen? - Diagnostic Analytics
- What could happen? - Predictive Analytics
- Can we prevent it? - Proactive Analytics
- What should we do? - Prescriptive Analytics
At interent the figure is lost. Mcafee is merged with FireEye, the new name: Trellix(2021).
❷ Needed: internal agreement, archiving knowledge, on what & how to do safety at the organisation.
❸ Top down: You need to know the safety goals and than how to get those implemented.
Bottom up: the technology is having a history of doing things some way. External suppliers have their own "best practices", sometimes they are very bad practices.
📚 Goals
- Get technical realisations aligned with high level guidelines.
- Following or initiating adjustments on the internal policies.
Waivers are exceptions declaring not following internal policies.
- Within technical layers having those configured and used conforming those intern policies.
🎭 It is about compliant processes, not the details in technology.
⚙ Having worked on:
- Getting the hands on those high level guidelines.
- Documenting Operations Security Guidelines (OSG) and giving feed back on those internal policies. Experienced feedback by audit reports.
D-2.3.3 ⚒ Data mining, Customer Intelligence (CI)
 ❶
❶ Data mining, data science was hyping in 2016, sill hyping 2024.
The department CI, Customer Intelligence, was in my early years (1990´s) one of the business lines to support with tools.
Cross selling, customer segmentation, churn rate and more are words they are using.
❷ The development being indicated with the word modelling, operational usage of a model using the word scoring.
That is using another language to communicate for known processes.
❸
A weird fundamental difference in data usage.
In the operational plane, operational systems, normalisation is the norm. At the analytical plane denomralisations is required.
❹
The same questions as always with analytics.
➡ hindsight: What happened? Why did it happen? Evaluate, consider, think: What could happen?
➡ insight: Can we prevent it? What should we do?
❺ Marketing, Customer Intelligence, is commonly using more data sources than are available internally.
Geo locations, external open and closed data for input processing bringing into correlations with internal business processes.
Bringing these marketing operations into departments executing the normal classic mass operations is a challenge.
The "Analytics Life Cycle" (ALC) is not settled yet, not in 2016 not in 2024 .
📚 Goals
- The coding tool SAS Eguide being more used instead of classic SAS desktop.
- The low coding tool SAS/EM (Enterprise Miner) getting supported.
- Availability of dedicated external data delivery flows.
🎭
Used technology:
- From early years still running the SAS 8.2 migrating to SAS 9.3. Adding SAS/EM connecting to DBMS systems (Oracle)
⚙
Having done:
- Solved configuration limits on memory threading and total maximum number of workspace sessions to run at the same moment.
- Searching connection to PMML standards. Doing an EM course myself.
- Archiving and restoring of EM projects made possible.
D-2.4 Lean processing TOC = JST: Job submit tool (II)

D-2.4.1 🚧 The situation, analyse the floor for improvement
Interactive Transactional Systems
❿ There are two appraoches for processing. In information processing for en enterprise it is not different.
- Batch processing: The process takes too long to wait for by human operator.
- The result is delivered after some agreed time. There is an event for the delivery.
- The order, request is visible, traceable, in several steps, stages.
- Processing is optimized by:
- decreasing manufacturing cost in an assembly flow
- simplifying activities that creates the product/service.
- Interactive systems (transactional, OLTP): the human operator gets results in acceptable wait time.
- The result is delivered in a time window with in a short time interval.
- The request actions are very small and short living.
Only details are noticed when an analyses requested and done (micro level).
- Processing is optimized by:
- investment for skills an inventory in delivering
- simplifying the product/service
❶ Batch vs online processing is full of emotions.
Technical descriptions for what batch is and what interactive are indeterminate.
The functional characterises are better understandable when accepting both of them are possible used in products / services.
Mainframe workloads: Batch and online transaction processing
 Most workloads fall into one of two categories: Batch processing or online transaction processing, which includes Web-based applications.
Most workloads fall into one of two categories: Batch processing or online transaction processing, which includes Web-based applications.
Perform end-of-quarter processing and produce reports that are necessary to customers or to the government. E.g. generate and consolidate during nightly hours reports for review by managers.
In contrast to batch processing, transaction processing occurs interactively with the end user.
Optimizing throughput, optimizing resource usage
 ❷
❷ Understanding technology components in information processing is full of emotions.
There are three important geographical levels:
- Local Machine: (fast) memory, processing units (CPU GPU)
- Communication lines to the machines
- Massive remote storage reachable by the machines
Valid for: "on premise" datacenters and cloud services.
❸ Balancing load over technology components optimizes resource usages, reduces elapsed time (clock time).
Total used time by several processing units easily exceeds the clock time.
Humans are educated to fulfill tasks sequentially.
Parallel processing, planning scheduling, is a more difficult concept to get reliable predictable results.
❹ Balancing load over interactive usage by operators - users and by planned batch processes.
Requires understanding what activities by operators -users at what moment can be expected and what the options for the other processes are.
Integrated Data Dictionary
❺ All kind of masterdata and metadata should be easily accessable and maintanable.
The IDD (IDMS Cullinet) is a good example how this works. A central IDD (e.g. 11) referring to a full DTAP realisations (eg. 66, 88, 77, 01). Each of them having staged versions of a dictionary.
❻ Release management for an IDD is based on promotion management.
CA IDMS Reference - Software Management
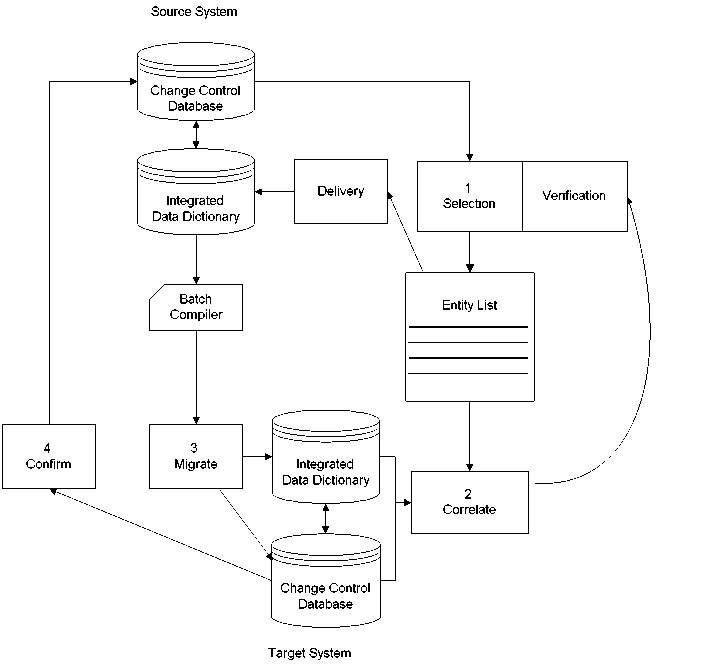 Promotion Management is the process wherein entities are moved from environment to environment within the software development life cycle.
When these environments consist of multiple dictionaries, application development typically involves staged promotions of entities from one dictionary to another, such as Test to Quality Assurance to Production.
This movement can be in any direction, from a variety of sources.
❼
Promotion Management is the process wherein entities are moved from environment to environment within the software development life cycle.
When these environments consist of multiple dictionaries, application development typically involves staged promotions of entities from one dictionary to another, such as Test to Quality Assurance to Production.
This movement can be in any direction, from a variety of sources.
❼ Release management for an IDD integrating with commercial tools is based on promotion management.
A choice for tools is very limited and a lot of scripting (programming) is needed for all dedicated naming conventions and requirements.
Endevor, Endevor-DB the only commercial external option with IDMS.
D-2.4.2 💡 Using holistic patterns QA testing
❽ Enabling a holistic environment using controlled released management and underpinned Quality Assurance is the holy grail.
The big problem to achieve this are: the assumed complexity and financial cost.
The first steps:
- Accepting the user customer is also the operator
- Solving the technical questions how a user is able to work in a safe way.
D-2.4.3 ✅ Release mangement, parallel testing development
Integration of relase management tools (Endevor)
❾ With the DTAP approach, home grown approaches are simply build and can be used for many years.
What should go into a release, what is verified (QA) and what is rolled out are the real questions to be solved by the organisations.
⚠ No tool is able to solve the real organisational questions in release management.
⚠ Those home grown approaches are similar to the usage of "Git". Copying, retrieving to a location is by a generic tool.
⚠ Disappointing: release management is not the same as running QA tests, validating, archiving test results.
➡ The list points of attention is a root cause for accumualting technical debt.
D-2.5 Structuring practices = coding guidelines, JCL2000 (II)
D-2.5.1 🚧 The situation, analyse the floor for improvement
The JCL script pattern challenge continued
Quality Assurance is testing the whole system holistic.
Just running a partial process or doing only a review how the coding is done gives no insight on quality.
Doing the same process in a test environment, not only partial batch-processes, but all their possible inter relationships and the interaction with the partial OLTP systems is the real challenge.
A complete environment simulation the operational prodcution is a pre requisite.
➡ Simulating is not the same as physical duplicates.
The JCL script pattern glossary
Defining all globals, job environment settings by artifacts:
| symbol | meaning | explanation |
 | Infra-Process | Used by Testers
Complete tetenvironment (image) backup - restore |
 | Infra-Process transactional | Used by Testers
Complete tetenvironment (image) backup - restore |
D-2.5.2 💡 Advanced patterns
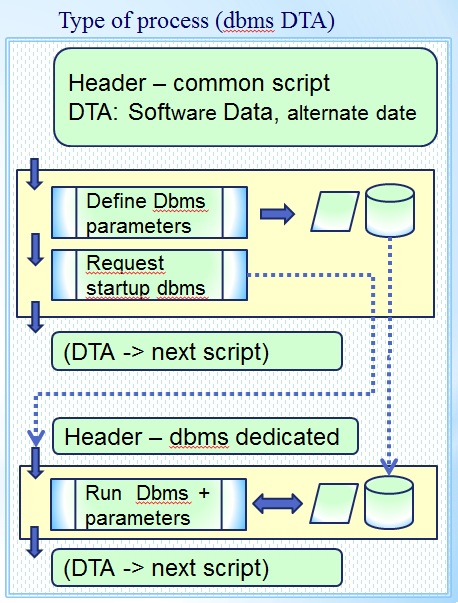
Dedicated DBMS script D, T, A
This feature essential to D,T,A Test environments when transactional systems are involved.
Head :
- There are several nested stages:
- Batch restore the database, define parameters transactional system
- At system privilege level start the transactional system with predefined parameters
Application body using procs & segregated IO
- related DBMS data, local datasets, local outputs
- database retrieve application
- database update application
- 3GL Business processing on files
- Information transfer - delivery
Tail :
- Starts after a normal stop of the transactional system
Support by functional - technical owners infrastructure components.
D-2.5.3 ✅ Running automated - hands free
Basic design, modelling the JST process
All kind of batch jobs for testers additional tools (compare)
Running the test by PTG rather well additional questions were asked.
Combining the whole testplan to be automated was the most advanced one.
🤔 This looks very complicated, the basics:
- When al Jobs-scripts are generated,
trigger the entire flow or at a dedicated point in the flow.
- An order, list of what to run in what order must be known.
- The usage of a production like schedule system is not an option.
During testing a whole flow representing multiple days weeks, months must be possible.
That whole flow must be easily repeatable.
- Selection by choices to build jobs <SubmitLib> out of <predefined processes
- Archiving and restoring of all made choices, ability to rebuild jobs completely.
- An option to define a flow of processes to run.
😲 The proces model for repeatabel planned testing has several dimensions:
- A dimension in Test plans
- Predefined processes: job bodies, step procedure definitions, dataset io definitions
- Jobs stored in a "SubmitLib".
Configured in environments: code, data, IO definitions, simulated run date
😉 The red arrows in the figure are indicating the optional selections for:
- jobs - All the defintions to get them run with predefined settings and values.
- testplans - The collection of jobs that make a testrun as unit.
- The fact in a star-schema ER-relationship is this the: "job".
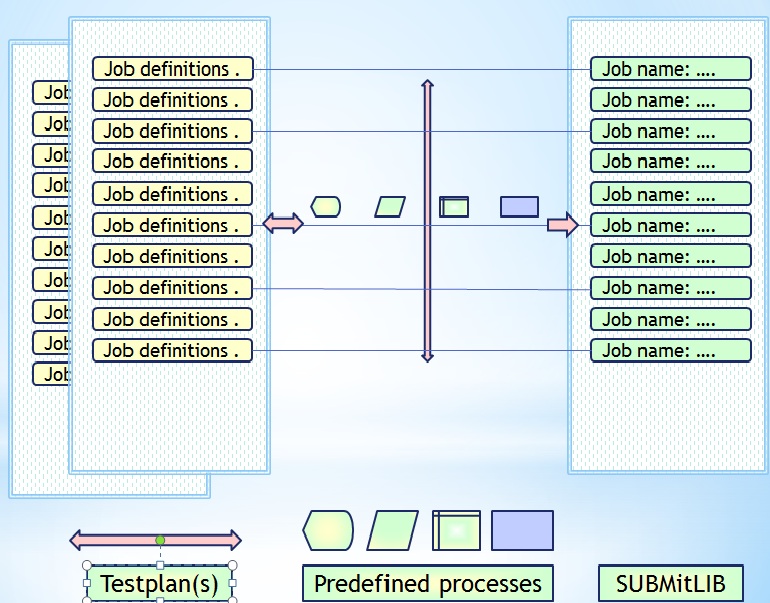
in a figure,
see right side
Running local batch vs central version transactional
Choosing run time technologies have a big performance impact.
- Running with a local version of the DBMS is going for locking area-s (files) not locking every record (OLTP).
In a relational DBMS this choice is by opening a table for bulk-load or not.
Bulk-load avoids journaling changes at every record.
A rerun, reload must be logical possible and designed for data-integrity.
- Creating indexes positioning of the physical devices (Striping) is an additional design task.
- Going for locking every record in a transactional way updating information has the advantages:
- 💡 Multiple jobs could run parallel on the same area
- 🤔 Same logic could be used in online, message driven, batch process.
D-2.6 Notes: Good bad and ugly - big enterprise
D-2.6.1 😉 Experienced positivity by activities

Used concepts & practical knowledge
Reconsidering all nice projects, nice because it has that many connections to a diverse set of activities.
Details to connect into this:
- Software Life Cycle (business)..
- Security ..
- Data modelling ..
- EIS Business Intelligence & Analytics ..
- Tools Life Cycle (infrastructure)..
- Low code data driven work as design..
The security association may not that obvious. It is embedded in all activities.
Good practice:
- Simulating the production using test-accounts, similar to production usage.
- Overall security and configuration in a way you can run a complete DTAP on a single box (Iron), containerized security anything.
- Understanding and configuring multi tenancy.
Operational Risk (OpRisks)
A nice team, staff of excellent people. I worked for their shared goal.
Marketing, CI, Credit risk, Actuary and others
Nice people to collaborate with helping them doing their work.

Job Submittool - Lean process toc
Words of thank to my former colleagues
We had a lot fun in stressful times working out this on the mainframe in the nineties.
The uniqueness and difficulties to port it to somewhere else realising the big challenge to do that.
A few names:
- 🙏 J.Pak co-designer of the common job approach.
- 🙏 D.Roekel inventing more proc-bodies faster than me.
- 🙏 J.Hofman, P.Grobbee working it out smoothly to testers
Many more people to mention, sorry when I didn´t.
(notes: 2008)
What about my collegues?
I had many of them, doublehearted feelings.
- Some were good still feeling as friends with all respect
- There were others being manipulative and without any human respect
- Others were locked in by the culture for the good bad and ugly
What about my teamleaders, management?
I had many of them, doublehearted feelings.
- Some were good, with respect
- There were others being manipulative and without any human respect
- Others were locked in by the culture for the good bad and ugly

D-2.6.2 😱 Experienced negativity by activities
What about my teamleaders, management?
💣 The merge with another organisation in 1998 was an example how it should not be done.
There was no vision insight on the goal, cost saving by accounting was the leading strategy but there was nothing more than that.
A battle of different cultures, different ideas was the result.
At the merge of that other organisation the our old management was set aside and that of the other got the power with the instruction to abandon their technology to use ours.
Even 25 year later nothing did exist anymore, former colleagues were still badly hurtled by wrong behaviour of the other side.
Printing services, Hardware consolidation
Printing in house by on prem mainframe. Cchosen printer technology:g Siemens.
🤔 This technology was already outdated when the machines were moved form the office to another location (1996).
The investment solving that technical debt could not be justified by only financial costs.
😱 Worse: the argument of cost-saving doing the relocation and consolidation failed dramatically for all involved parties.
Technical debt for printing was solved around 2010, allowing the print services to be outsourced. The technology change to the one what was used at other amchines.
Job Submittool - Release management
💣 With the merge of the other company their technology opinions were getting in.
One of those was purchasing Endevor would solve anything about release management, development and QA testing.
That was a very costly customer journey for the organisation by wrong perceptions.
Worse: the failure getting used in a personal blame claiming it was the JST tool fault.
Technology options- organisational consolidation
💣 With the consolidation ohter people com in with their technology opinions.
Instead of the claimed better
- JST: Backup restore used ADRDSSU virtual tapes.
This got into discussions because doing that was seen being a task only allowed to an operational ICT department (OPS).
- SAS: The BoKs sudo alternatieve failed in a technical async terminal line quirk.
- SAS: Not getting alignment with external suppliers and changing internal politics.
- SAS, security: Multi tenancy conatainerisation I got personal blamed being complicated.
Financial crisis, mandatory orgnsaitional split
💣
After growing by merges and consolidations the result of the financial crisis was an implosion and split.
Forcing people to leave in any way. I was lost not belonging anywhere.
It was a too much toxic attitude by too many.

D-2.6.3 🤔 Ambiguity complex uncertain volatile emotions at activities
Job Submittool - Release management
The effect of these perception mismatch for Endevors was that the JST tool got rolled out to development (DEV) and to acceptance environments.
In the end a full development line even for the operations department was in place.
Operational Risk (OpRisk)
Several ugly issues:
- Issue 1: The internal cost assessment became unexplainable high. The cause was: Oracle licenses and involved machines.
- Issue 2: Doing a DR test successful was almost impossible due to too many involved machines. Cause was: The Oracle database location.
- A strange quirk in dynamic prompting causing difficulties to run for different lines (tenants) having their own internal data.
D-3 Wandering contract roles
D-3.1 Creation of new innovative ideas
D-3.1.1 🎭 Information processing, DWH, Data Lake (I)
Soc, Security operations Center and Computer Operations
❿ This one of the beginning of the information age has influenced a lot of how I see information processing.
All kind of questions, what is really needed, what is possible available, in scope.
- Technical resource usage and abuse
- Functioning operational progress in normal and abnoral conditions
- Functional configuration and the possible operational deviations
- Technical resource cost allocation into functioning and functionality
Integrated Computer System Information (CSI)
❶ The basics of information processing using logs and other sources.
The DWH (data ware house), data lake, for a CSI is able to support security operations and others.
This started at the same moment with those other topics for Executive Information Systems (EIS).
A spreadsheet, these days Excel is the standard, and a more easy presentation on a personal computer.
Spreadsheets, websites, are a very simplified approach only having that interface of security access.
System management facilities (SMF) collects and records system and job-related information that your installation can use in:
- Billing users , Scheduling jobs
- Reporting reliability , Analyzing the configuration
- Summarizing direct access volume activity , Evaluating data set activity
- Profiling system resource use , Maintaining system security
❷ That are a lot of goals with a different kind of usage.
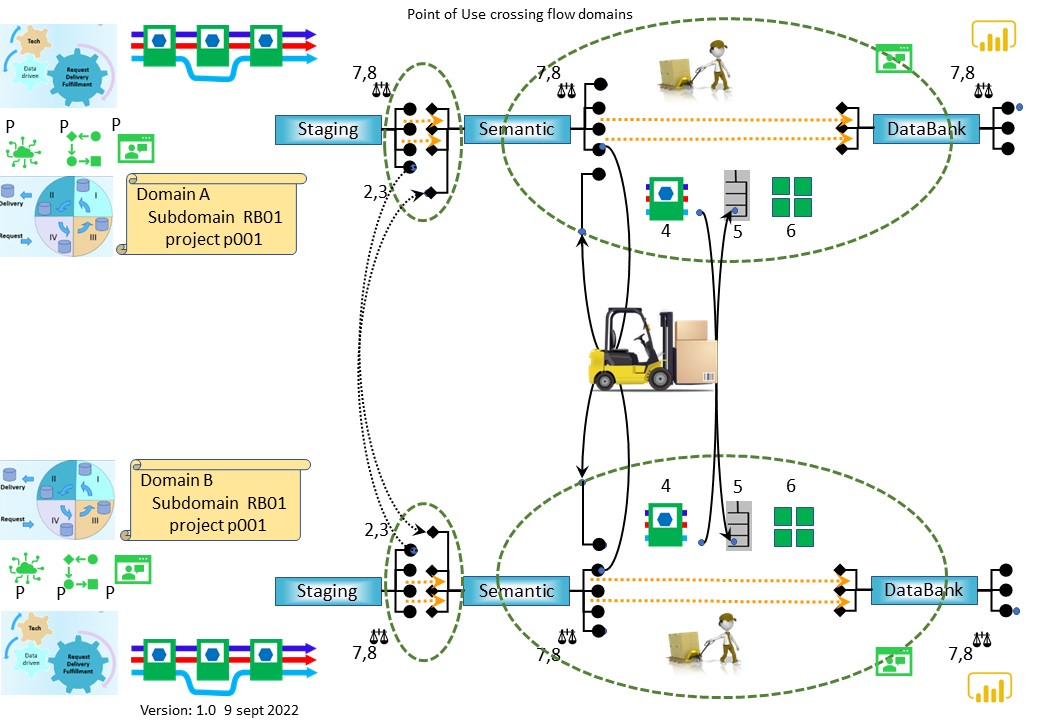
Technical it is: Extract Load Transform (ELT) - selecting types: Extract Transform load (ETL).
Building a DWH, datalake:
- a landing area
- add more meaningfull context in a staging set
- get a semantic area from the staging
- create the valuable knowledge in a databank
❸ Having a generic system (SMF) avoids the need for defining a data pipeline for every subsystem.
It was not complete, not a everything is included in those logging.
Add data, information for:
- Network, firewalls
- System information by retrieving dedicated administrations
- User group authorisations with activity accounting information.
- Business applications with owners and accounting information.
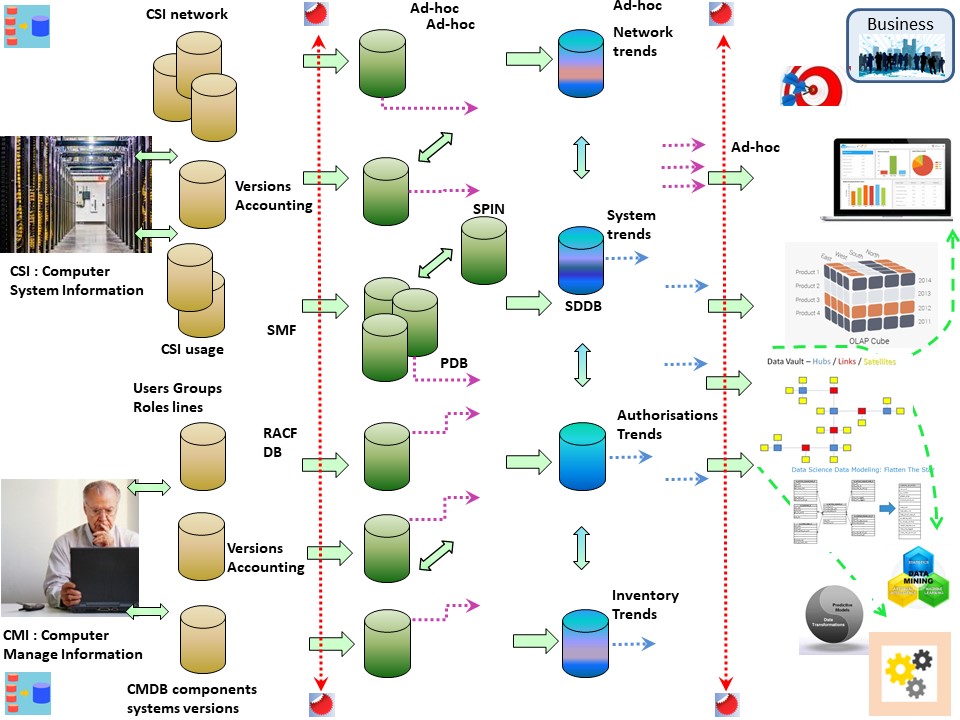
in a figure,
see right side
CSI disintegration due to separation in interests
❹ Security operations Center (SoC) specialized in processing logs for the limited cyber security safety goal.
Logs, events for Windows, log systems in Unix the modern products.
⚠ Issues:
- It does a bypass on the basics questions (the why): what is needed for who.
- It excludes interests of operational technical monitoring & analyses.
- It excludes interests of operational functionality & functioning monitoring.
When words like "operator" are used the functionality and security are easily going into conflicts by different interpretations for usage and goal.
D-3.1.2 🎭 Information processing, DWH 3.0, Data Lake (II)
The warehouse similarity
❺ Business Intelligence analytics (BI&A), EIS - Operational information flow are two complimentary topics.
Common accepted practice: copying from the Operational information flow into a DWH, datalike, for the sake of reporting.
The difference in interest:
- The operational core value stream (flow) is for the mission of the organisation.
- Understanding what is going on in the core value stream is BI&A.
❻ Both of these two complimentary topics use ELT / ETL in four stages:
- a landing area
- add more meaningfull context in a staging set
- get a semantic area from the staging
- create the valuable knowledge in a databank
⚠ Issues:
- The core value streams are unmanaged, not under control.
- BI&A is an operational information copy, not designed for closed loops.
- BI&A being an operational information copy the easy abuse is for operations.
- The information at the BI&A DWH is a potential information safety problem.
💡 A simplified lean design, data lake, data warehouse 3.0
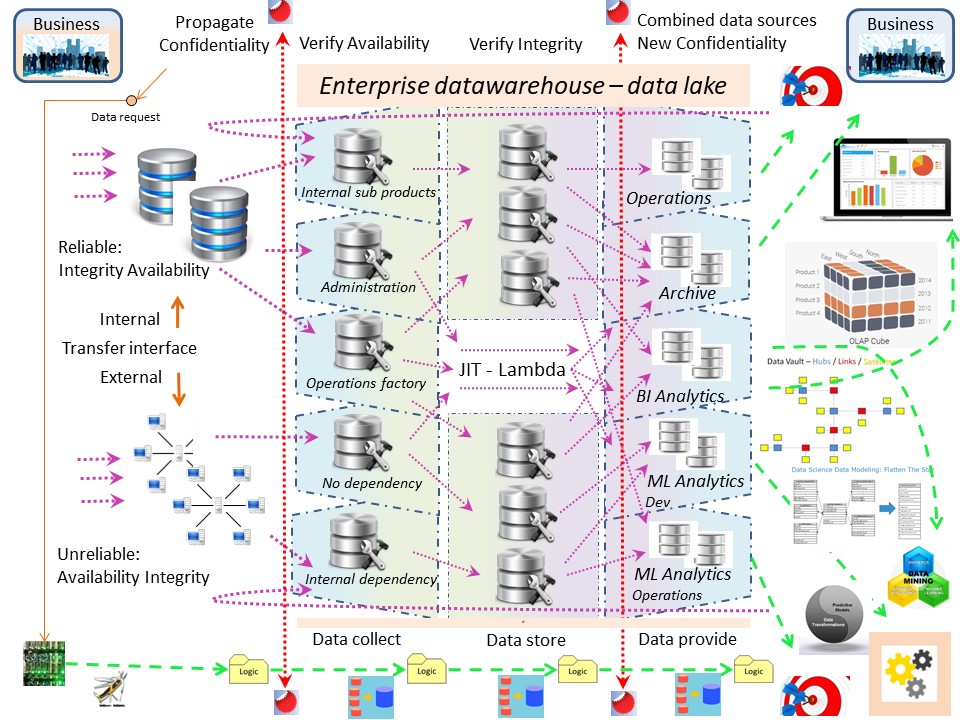
in a figure,
see right side
D-3.1.3 🎭 Lean design: Initialisation Termination, Control
Measurements Operational processes
❼ How to get detailed information monitoring operational processes.
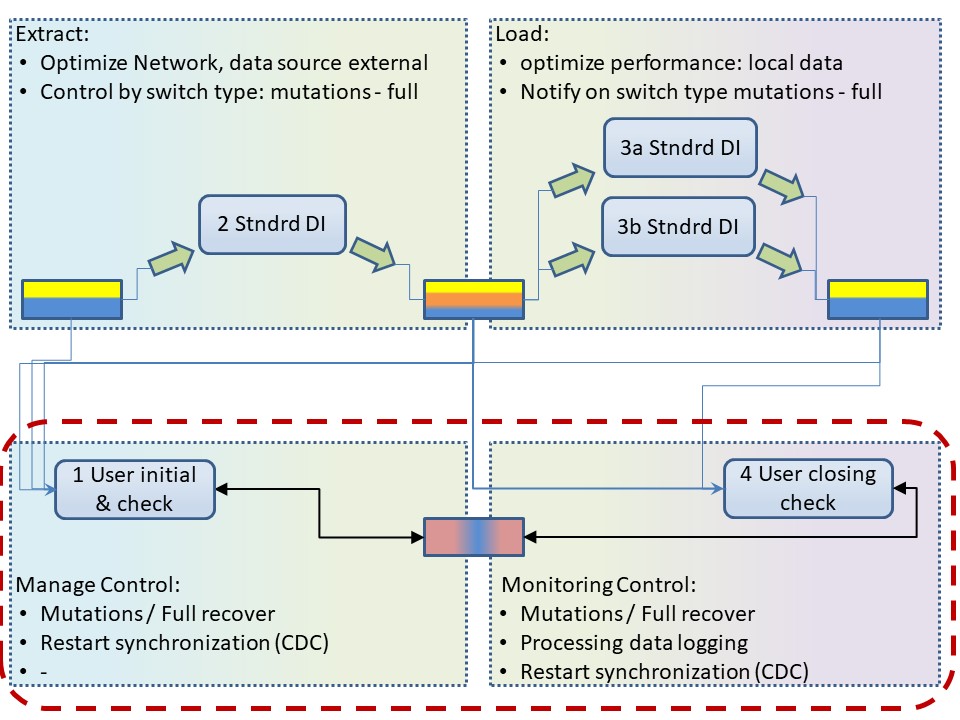
For example how two implement a watchdog on extract, load steps. ( E-L ➡ T )
Extracting information results in one or more datasets, tables.
💡 Detailed control & balance requires addtional knowledge at initialisation and termination logic.
This logic is tailored & configured to the organisation in house process standards. Contains knowledge of the designed functionality.
⚠ 🚧 Mission impossible: expect this getting solved from generic tools.
lean desing, full process control design
❽Any process whether physcial or in the cyberspace is going through a circle.
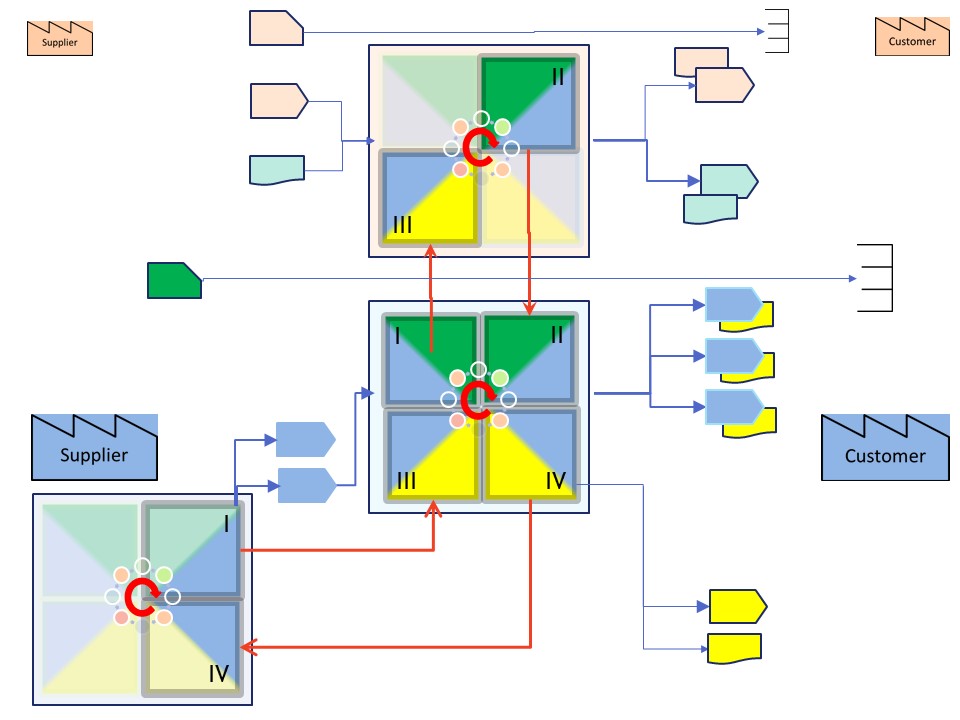
Processing the value stream (LTR):
➡ request: IV ➡ III (pull)
➡ delivery: I ➡ II ➡ (push)
💡 Two supporting processes for control, delivering needed components and another for monitoring usage.
👉🏾 This idea is the same as the "operational plane" and "analytical plane" of Data Mesh.
The experience and cotrol planes are not mentioned but the ones needed in completeness.
⚠ 🚧 Common distraction: from "value stream" into using machines, tools software, cots.
Importance of Naming Conventions, Data Administration
❾ Data Administration or Master Data Management (MDM), the goal is a clear understanding on the meaning context inentions and goals.
Gartner
Master data management (MDM) is a technology-enabled discipline in which business and IT work together to ensure the uniformity, accuracy, stewardship, semantic consistency and accountability of the enterprises official shared master data assets.
Master data is the consistent and uniform set of identifiers and extended attributes that describes the core entities of the enterprise including customers, prospects, citizens, suppliers, sites, hierarchies and chart of accounts.
💡 The importance of a clear naming conventions with the goal of clear understanding and using that for simple technical solutions cannot be overvalued.
D-3.2 Understanding ICT areas (I)
D-3.2.1 ⚒ ML, Machine Learning, Scoring, Explainable AI (I)
❶ The environment was about sensitive information (2016), governmental, big organisation.
The first question was technical one going into functionality support.
In the technical design the assumption was made that
Scaling out was the only possible approach.
📚 Goals:
- Performance gains by parallel processing usage.
🎭
Used technologies:
- SAS, Teradata (parallel dbms), Linux - Unix shell scripting.
⚙
Solutions design and realization:
- Ease in coding being preferred avoiding the need for ICT specialists doing the coding.
- Using a parallel database, Teradata.
- Design thinking: avoiding data transfer between machines is better than coding ease.
- Scheduling strategies using multiple machines in cooperation of one execution flow.
❷
The second question was support and solving functionality for a dedicated purpose.
In the technical design the assumption was made that
Scaling out was the only possible approach.
It should be replaced by updated versions. A generic description.
 📚
📚 Goals:
- Operationalize an existing scoring model that has run manually for a long period manually.
- The Production environment being direct connected for streaming data (message oriented) as input and delivering the results back within that same daily run.
- Delivery to several other production processes with time limits.
- Replace the several old local build solutions within business department with this new approach.
🎭
Technology used and limitations:
- Process the scoring with a limited SAS tooling set: No availablity of a scheduler, no release management tools, no versioning tools, no segregated environments.
- The executing window has a maximum of two hours, the whole proces should run in about an hour to be able solving possible incidents.
- The source data is build up by using multiple flows, several windows:
- weekly proces that is running severals days to complete. Followed by four hours additonal preparations
- Daily updates to complete the too long running weekly proces
- Daily changes as feedback of deliverd scores and feedback of changed adjustment within the production proceedings
- The number of cases to be processed as message delivery can be 300.000 (quarterly peak). The total number of cases apx 2.000.000
⚙
The solution design and realization:
- Build and used a manual coded scheduler in SAS that is having all necessary functionality like triggering on events and monitoring on unexpected behavior.
- The release management issue bypassed in an approach with segregation in duties.
- Achieved a very stable hands off process that could be easily transferred to others.
D-3.2.2 ⚒ ML, Machine Learning, Scoring, Explainable AI (II)
 ❶
❶ The environment use sensitive information.
The company is a public enterprise that had a relation with a bigger financial institute (2017).
Some approach details.
In the technical design
Scaling up was the only allowed approach. No made assumption but a limitation by defined external technical resource support.
📚 Goals:
- Improved performance optimizing usage bare iron.
🎭
Used technologies:
- SAS 9.4, linux shell scripting
- UDB SQl interface
⚙
Solutions and realization:
- Got annoyed by bad performance in inodes.
Bypassed the bad behaviour with planned clean-ups and different way of coding, record updates in SAS coding changed to bulk updates as full datasets.
- Seeing basic tuning issues once solved (80's) at mainframes occuring again.
Bypassed with coding and scheduling avoiding the IO overload.
❷
Patterns are basic building blocks and shoud match some issue to solve.
📚 Goals:
- Operationalise ML scoring models in full DTAP.
- Processing improvements enabling new changes.
- Extend from one operational country by two.
- New Score models should be able to add in a more easy way. Short: refactor - agility.
🎭
Technology used and limitations:
- Scoring in a SAS environment (base 9.4).
- LSF scheduler, DI as data integration tool (ETL ELT data lineage), manual coding (Eguide).
- Scores should reflect reliable the current situation as near as real-time with the known information in the front-end system (IBM I-series).
Incremental updating for data changes is about every 15 minutes
- There are just two physical machines but a logical four DTAP logical segregation has been defined (development machine).
The production processed on one fully isolated machine.
- Information source is gathered from another system (IBM iseries).
- Data should be synchronized for up to 7.000.000 objects as fact (2.000.0000 active) in an ER-relationship with several dimensions for each country.
⚙
The solution design and realization:
- Changed the data synchronisation to a full daily extract from the data source.
- The question on what could be going missed by "Change Data Capture".
- Executing time within 15 minutes but needed to be agreed on the network load.
- Got aware of parallel development / test situation.
- Data deliveries are impacting analysts, modelers.
- Modelling scores is dependent on data delivery.
- The score delivery is dependent on scoring.
Changed to a set up achieved something workable for these dependencies.
- Releasemangement set up full DTAP, testing:
- acceptance (integration, system test)
- shadow production (acceptance and DR) before production.
- Modelling mind switching to ER instead 3nf dimensional.
- Prepared the versioning and releasing using git and bitbucket.
- Added monitoring:
- data change process and
- score process
to stop and get notifications when there are an unexpected number of changes.
It got the nickname "watchdog" (7,8)
D-3.2.3 ⚒ Data governance, variability volatility
❶ I had a period at a healthcare insurance company.
What I learned was several of the interesting information flows for declarations and costs from details into overviews being send to governmental regulators.
❷ I got a project at a governmental regulator for healthcare cost.
The environment is based on sensitive information but fully anonymised by aggregation. Some details in the problem and solutions follows.
📚 Goals:
- Replace existing technology, limited frontend tool and a DBMS in a more simplified approach.
- Have the existing used interface for getting information kept external in place using that simple and reliable strcuture.
🎭
Used technologies:
- SAS 9.4, Eguide with office addin
- Excel being the external interface on a protected datapage referring to excel content controls on other pages.
⚙
Solutions and realization:
- Added to the field on the excel datapage a naming structure unique refering to elements applicable for strcutures tables and categories.
- Stored the naming conventions with some expalanations as a master metadata dataset.
- Converted previous years excels with contents adding while definiing the nameing conventions.
- handed over a working approach with 16.000 defined elements in the masterdataset.
📚Defining, naming all elements was a unique learning.
The challenge of not having that much data, there apx 30 suppliers delivering, but the complexity in the volatiblity and mass number of information elements.
The translation made was doing the request delivery in the same cycle type of doing a request and delivery.
The available information (input) is a fixed layout.
Output, results, having a goal are in a relational format using columns.
Processing the value stream (LTR):
➡ request: IV ➡ III (pull)
➡ delivery: I ➡ II ➡ (push)
💡 Controlling mass in involved elements by using naming conventions in logical names (32 positions).
👉🏾 This idea is supporting using Excel where it has strengths.
Remote validated controlled data using summaries better than uncontrolled CSV or asci files.
⚠ 🚧 Common distraction: from "value stream" into using machines, tools software, cots.
D-3.3 Understanding ICT areas (II)
D-3.3.1 ⚒ XML messages, object life cycle data model
❸ The environment was about sensitive information (2016), governmental, big organisation.
The third very interesting queest was about getting an attempt to process a very complicated data model.
Data modelling is a confusing challenge. The requirement is undertanding how information is delivered and what information is needed. These can be complete differnt worlds of context.
 ❹
❹ The classic DWH approach is based on modelling very detailed elements optimizing the transactional database process and saving as much as possible storage. The disadvantage is the complexity in relationships.
Blockchain is a hyping approach (2018) for archiving and processing al detailed information and all history in chained blocks (ledger).
This complicated model is another approach to process and now changes in time. The ownership of the information by governmental task is the required underpinning trust.
❺ In practice contracts, legal agreements, are describing fully the most recent situation.
Their history in changes is only in special cases relevant.
Those special cases are the most interesting ones when a goal is able to detect illegal activity or fraud.
Use case "real estate":
📚 Goals
- Changed delivery: from database export into XML message processing driven one.
- The size is apx 10.000.000 objects as snapshot on a dedicated moment.
- Updates originating from legal action are up to 10.000 messages daily.
With technical related changes that can grow above 100.000 messages daily.
- Every message is having full details up to 70 record types. Some record types allow repetitions of 10.000.
- Every message is having the "current" and "previcous" situation with a unique key-reference creating a chain for a object.
🎭
Technology used and limitations:
- SAS, Linux scripting, Teradata, XML, modernized SQL (XMLTable)
⚙
The solution design and realization:
- Preprocessing splitting XML and transforming it, is necessary.
- A split up in a tremendous lot of small pieces processing did evntually run.
D-3.2.2 ⚒ Grid computing - performance load balance
❶This is a hot topic for performance reasons effectivity and cost of business solutions.
The question on choices is coming back everytime. Only for simple not distinctive commodity solutions this is not a relevant topic.
 The Free Lunch Is Over
The Free Lunch Is Over :
A Fundamental Turn Toward Concurrency in Software Grid computingframe (Herb Sutter 2001).
The conclusion:
Applications will increasingly need to be concurrent if they want to fully exploit continuing exponential CPU throughput gains Efficiency and
performance optimization will get more, not less, important.
❷ One approach is
scaling out
❸ Another approach is
scaling up
No matter which one, parallel processing, not serial, should be the mindset.
📚 Goals
- Acceptable performance throughput serving the goal of the organisation.
- Have the fucntionality for the organisation high and improving.
- Keep financial costs, investments, risks in operational en capital expense: low.
🎭
Technology, limitations:
- scaling out simplifies environments when it is a logical technology or tenant segreagation.
Advantage is ease in tenant segregation. The disadvantage is cost.
- scaling up simplifies environments when in available commodity limits. Internal memory and cores on cpu's still are increasing.
- Both are limited by network bandwith. Network bandwith is changing but by locations there are always limitations.
⚙
The solution design and realization:
- Ever lasting change by time and by situation.
D-3.3.3 ⚒ Technical & functional support, using a datalake, DWH for analytics
❶ The environment use sensitive information.
The company is a semi public enterprise that has it main activity for healthcare insurance but lso some banking and insurance lines (2020).
❷ Storing objects for use at some later moment is warehousing.
Just collecting a lot of things not knowing whether you will use it, is another approach, data hoarding.
The words "datawarehouse" and "data lake" are confusing in their associations with their physical counterparts. The physical ones are in the operational plane.
The
Datawarehouse (Bill Inmon 1970, Ralph Kimball 1996) is not having a goal in the operational plan but in the analytical plane.
In essence, the data warehousing concept was intended to provide an architectural model for the flow of data from operational systems to decision support environments.
What it is describing is the functional equivalent of a quality assurance laboratories and / or a research laboratory.
The goal for this is allowing JIT (Just in Time) processing, going for lean realisations.
❸ All kind of issues and real problems I have seen from the beginning in the 80's were stacked-up in their environment.
The goals and topics changed by time solving several of those issues while getting some new ones.
📚 Goals (I)
- Understanding the technology implementation, politics, options for change.
- Doing required changes for necesssary technology changes.
- Focus on the complications in the storage solution.
- Handing over knowledge experience to another person(s).
🎭 Used technologies
- SAS 9.4, SAS Viya included LSF (Scheduling) Eguide and Web interfaces
- Spectrum Scale (IBM). A performant software defined storage system (SDS)
- Using teams SharePoint for the documentation and communication
- AD administration, using local admin, resulted in learning and using power-shell
⚙ Solutions (I)
- Collecting the information documentation by camerations conforming the factory cycle.
- Reverse engineered what was necessary but lacking information documentation.
- A not supported functionality was used, this had to get stopped.
- Building data collectors in Powershell using SAS for reporting.
❹ Handing over knowledge resulted in extensively documenting while discussing what BI&A is about.
The question of sharing information in a component approach resulted in the following figure:
 ❺
❺ There was a good fit with the colleague. The SIAR model for agility was without discussion.
A project was running for storage migration, it was started several years before.
Used old hardware old storage was getting obsolete.
📚 Goals (II)
- The storage migration had to get finished. Switching off obsolete hardware.
- An understandabel functioning Backup-Recovery Disaster recovery in place.
⚙ Solutions (II)
- Collaborating and steering in the storage migration as technology service.
- Executed the storage migration for all tenants. Allowed switching off obsolete hardware
❻ The need for an update for the processing servers expected.
📚 Goals (III)
- Collaborate in options for new virtual machines.
- Verify those will do similar to the physicals.
⚙ Solutions (III)
- Requirements, new design planning, verification planning in a structured approach.
- Realising the new design situation, doing verification during progress.
❾ There was time to develop that structured approach in requirements, design plan, verification plan.
Reviewing that while building it the notion is that is very generic and could be an new disruptive product with framework.
👉🏾 Jabes.
D-3.4 Lean linkage: the virtual shopfloor
D-3.4.1 🚧 Situation: analyse the floor for improvement
CPO, chief product officer
When the product service is what it is about, the CPO has a pivotal role.
A CPO is more then just another chief role. It is linking pin for middle management coordination: Product, Proftibality, Quality, Safety for predictable adding value.
X Issues in Control (blue diagonals):
| Accountability | clarification |
| Product Manager | The product managers role is not in place, it is a recovery proposal |
| Quality Control | Quality control is too often missing, it is a recovery proposal |
| Delivery / Safety | Safety for the environment too often isolated, it is a recovery proposal |
| Account Manager | The one for decisions achieving profitability by quantities |
+Issues in advisory & support (green vertical horizontal):
| Advisory&Support | clarification |
| Sales Manager | The well known persons for contacts to external customers | |
| Business Analyst | The well known persons for functional management |
| Water Strider | The ignored person that keeps the processes going |
| Safety Analyst | Safety for the environment too often isolated, it is a relocation proposal |
Change & Control - 3*3 plane visual
Using this C-role existing, recovery, relocation & newbie in a 3*3 plane is changing the Command & Control mindset.
A visual is helpful in understanding.
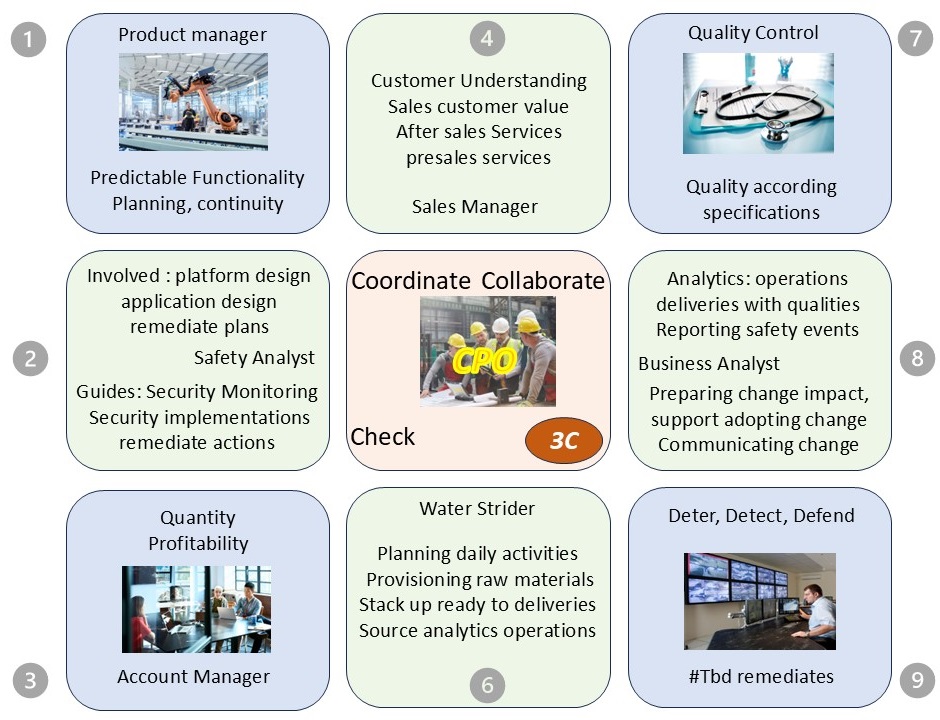
The Fancy 3*3 plane:
D-3.4.2 💡 The Product / Service quantum - floor
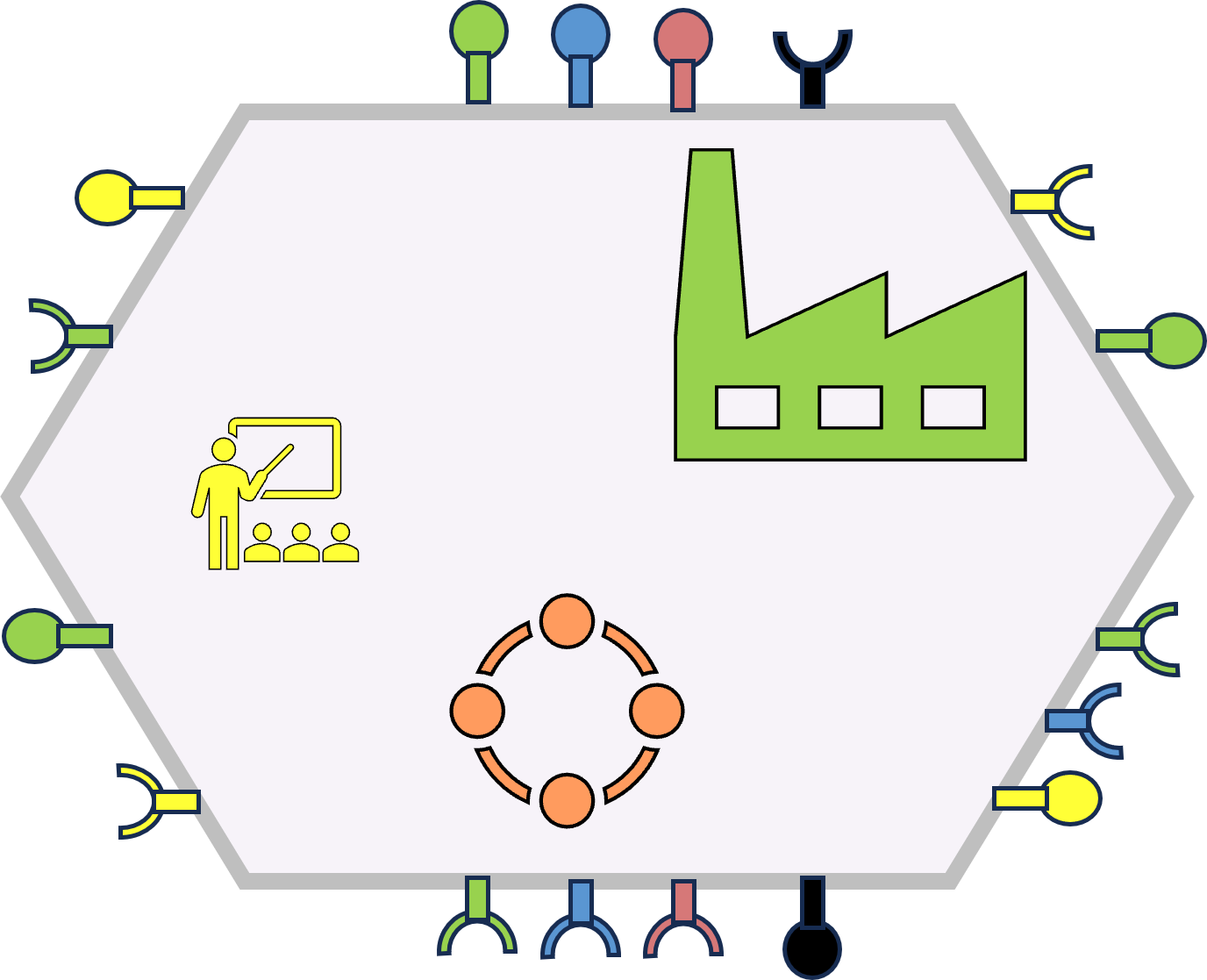
Product / Service flow
When the product / service covered by a vision mission of the organisation a quantum exist with many lines of several types.
See the figure aside.
The Product / Service flow, operational plane:
- Goal: defined quality according specifications, no defects.
- Delivery of a product / service aligned to external customers.
- Safety assurance for the product / service and the manufacturing
- Planning, forecasting: achievable throughput for profitability
Closed loops
There are several closed loops for different stakeholders doing a balancing act.
The PM product manager ha a pivotal role in functionality.
Several roles have multiple tasks:
- Business Analyst:
- Monitoring operations on what is happening at deliveries.
- Coordinating in rolling out approved changes, process updates.
- PM advisory: impact on product- service lines by decisions.
- PM manager informing: progress at change processes safety actions impact.
- Safety Analyst:
- PM advisory: platform, application design, remediation options.
- PM informing: Security monitoring, implementations, remediation actions.
- Monitoring operations on what is happening at deliveries.
- Coordinating in adjustments by changed regulations and controls.
Supply process
There is a positional context change when the product / service is operational executed or under change or in development.
In a figure,
see right side:
D-3.4.3 ✅ Lean, agile, optimizing - floor
Understanding Agile, Lean
The understanding of Agile is limited to what the hierarchy allows to get realised by lean.
Avoiding the tree evils is hardly possible at the floor. Being under control by hierachical constraints is limiting lean options.
Empowering people is often mentioned but micro management is more likely to happen.
In a figure,
see right side:
Going Agile, Lean
What the floor is able to do is understanding the improvement cycles PDCA DMAIC and what is possible for that within their cycle of influence.
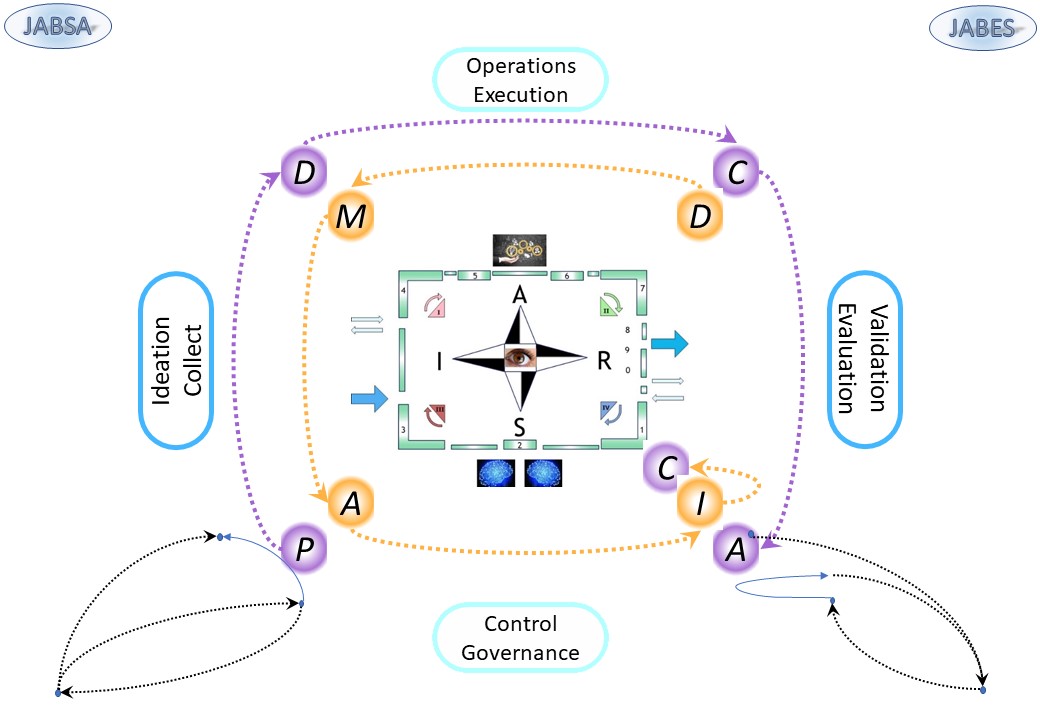
In a figure,
see right side:
D-3.5 Lean linkage: understanding flow value
D-3.5.1 🚧 Situation: analyse the boardroom for improvement
CPO, chief product officer
When the product service is what it is about, the CPO has a pivotal role.
A CPO is more then than the COO (Chief Operations Officer) it is including innovation (Chief Innovation Officer), technology alignment, involving empowered people.
X Issues in Control (Chief _ officer):
| Accountability | clarification |
| CFO finance | The well known one for financial stability and predictiable profitablity. |
| FM/HR facilities | Facilities, working place, human resources and more are essential assets. |
| CRO Risk | Existing, redefine in all kind of risks what is done and what is not done. |
| CEO Executive | The well known one for decisions for the enterprise, organisation. |
+Issues advisory & support (Chief _ officer) :
| Advisory&Support | clarification |
| CAIO A&I | Analytics Intelligence is how about understanding information (new). | |
| CSO Safety | Safety including well known cyber security (new). |
| CTO Technology | Technology attention is at the cutting edges. Continuity is being between those. |
| CDO Data | REdefines into: Human communication, understanding using by shared language. |
Change & Control - 3*3 plane visual
Using this C-role existing, recovery, relocation & newbies in a 3*3 plane is changing the Command & Control mindset.
A visual is helpful in understanding.
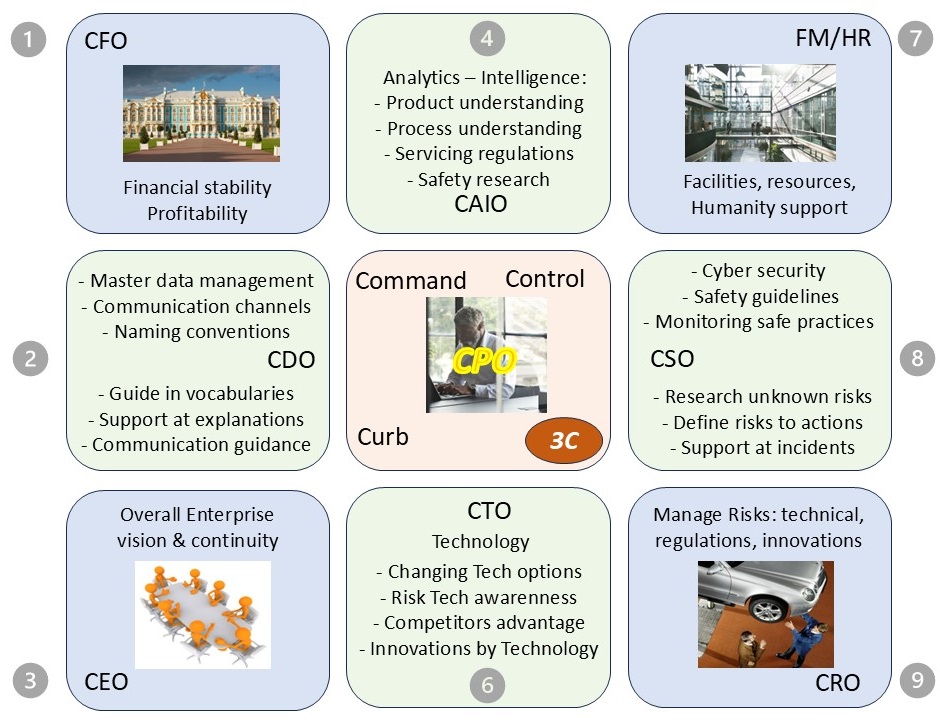
The Fancy 3*3 plane:
D-3.5.2 💡 The Product / Service quantum - strategy
Product / Service flow
When the product / service covered by a vision mission of the organisation a quantum exist with many lines of several types.
See the figure aside.
The Product / Service flow, operational plane (horizontal):
- RTL Green: Product / Service Pull request
- LTR Green: Product / Service Push delivery result
- RTL-LTR Yellow: Operational Changes for the Product / Service
- RTL Blue: Planned design changes innovation Product / Service
Closed loops
There are several closed loops for different stakeholders doing a balancing act.
This is applied analytics, intelligence with the goal of understanding the performance.
The connection lines are in the analytical plane (vertical):
- Green: The level of functioning of the operational plant for the Product / Service
- Blue: The level of functionality of the design for the Product / Service
- Red: The level of purpose for what Product/Service is designed
- Black: external events that can be helpful and disruptive
It would help a lot in simplification of what data, what information and analytics intelligence are important.
How to do the knowledge provision is simplified by a more clear understanding of intended goals.
😉 This would be simple when all was just internal processed and there would be not any external dependencies for a Product / Service.
Supply chain
The reality is different multiple products / services are combined into what is the product / service for the (external) customer, consumer.
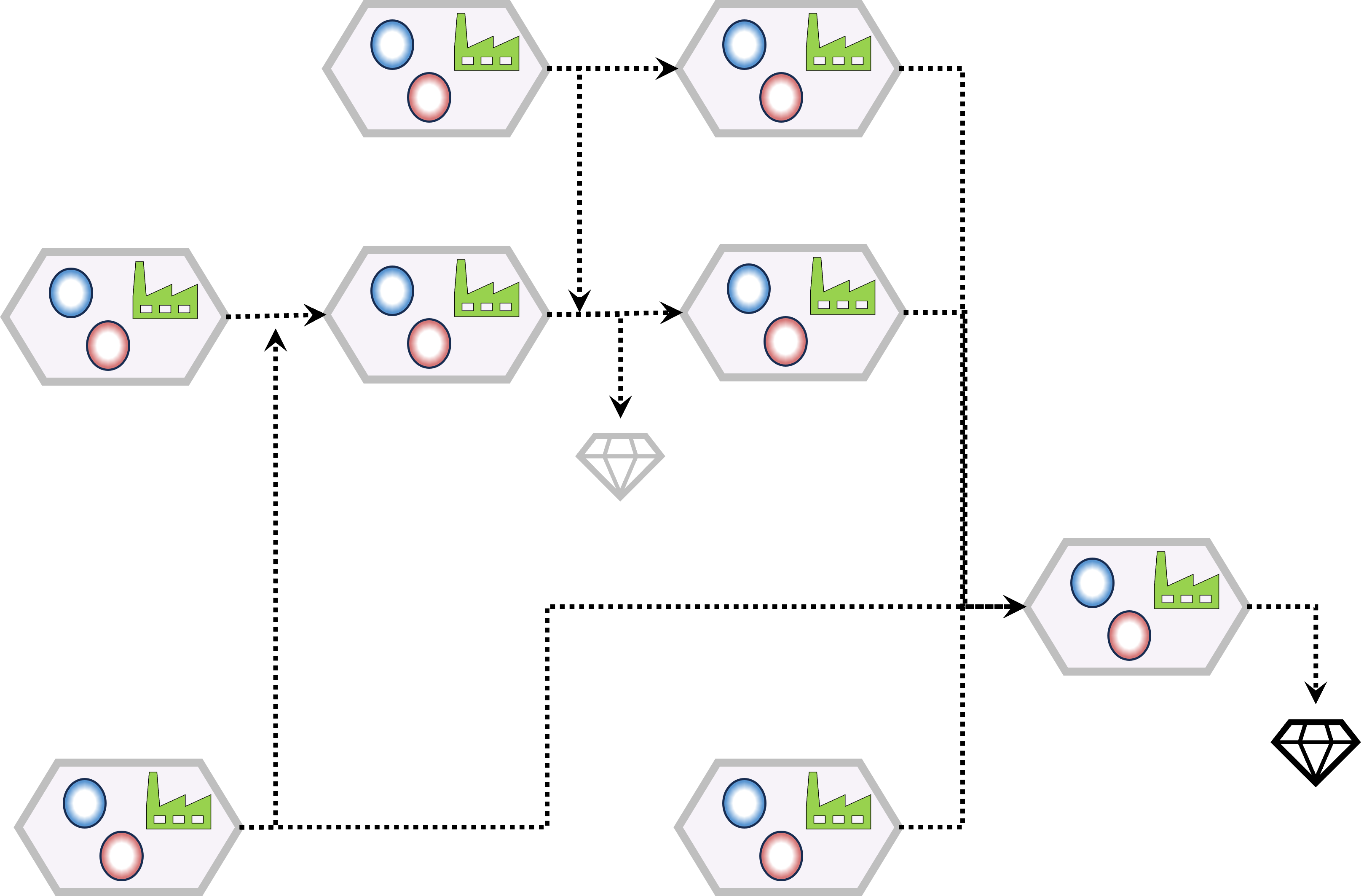
In a figure,
see right side:
The challenge is this:
- Possible multpile parties accountable for the logical design, functionality
- Possible multpile parties accountable in the chain for the products / service purpose
D-3.5.3 ✅ Lean, agile, optimizing - strategy
Going Agile, Lean
Everyone is wanting this, seeing the advantages but at the same time most attempts are failing dramatically. What is going on, why is this happening?
When asking what lean is, agile is there a good generic applicable answer is not found.
Trying to understand how to recognize lean, agile no good generic applicable answer is not found.
There is a famous commercial example trying to be copied by similarities, it is the Toyota Production System (TPS).
This famous example however was not the only one moving in that direction. The Theory of Constraints (TOC) 1984 was build on top of that.
Looking from a far distance it is a natural evolutionair evolvement in the "Information Age".
Understanding Agile, Lean
Trying to understand lean agile and trying to categorize a complicated list of requirements with definitions, technical requirements, behaviour requirements resulted in something that could be helpful in recognizing lean agile.
In a visualisation:
The areas in this 3*3 plane are not at random places, they are positioned for:
- A clockwise PDCA cycle starting with the P bottom left
- The pull request RTL line at the bottom
- The push result - delivery LTR line at the top
The pillars are interesting in understanding lean and what has happened.
- The left vertical pillar is about mindset. The famous TPS example had his place in a culture that did not have many conflicts for that. The Toyoda family had an important role for this
- The middle pillar is about methodology and practices. In the famous TPS example the dissonant Taiichai Ohno was the master for this.
- The right pillar is about measuring, understanding, insight adjust in closed loops. Deming had an important role in this one.
- In the middle there are threats obstacles. When not getting managed they will rip down the others. For the TPS system Eiji Toyoda was the master.
If we accept this as what has happend and accept the why it is happening at least there is way to recognize that big lean elephant. Not being lost anymore in details of the blind trying to understand the elephant.
D-3.6 Notes: Good bad and ugly - wandering - visonary

D-3.6.1 😉 Experienced positivity by activities
Used concepts & practical knowledge
Reconsidering all nice projects, nice because it has that many connections to a diverse set of activities.
Details to connect into this:
- Platform Life Cycle (business).. ◎ Security .. a boomerang topic.
- Data quality assurance .. ◎ Data historical chains operational & analytics
- Data variability far over human acceptable notion
- Software defined storage Life Cycle (infrastructure)
The security association got more obvious. It is embedded in all activities.
- Using segregated environments, similar set up to production usage.
- Lean approaches for achieving goals avoiding the internal policies.
- Understanding and configuring multi tenancy .. a boomerang topic.
Working in a big government environment.
Experiences were positive because:
- Rolling out a new platform was done in a small cooperatieve team with success
- Supporting multiple customers in nnovation for the new platform: functional progress
- Several interesting projects with peculiar constraints to solve in operations and analyses
The three periods were a good, althoug a huge organisation a lot was possible.
- 🙏 Nice good management
- 🙏 pretty an good collegues at the floor

Midlandce construction
Not being an entrepreneur I was at several projects in a mid-lance construction.
I got several projects for longer periods. When issues arose I was kept out of the heat.
The small company changed over time.
- 🙏 Nice colleagues and support when all was new.
- 🙏 The ones open for the new innovative idea.
Not always understood the impact behind the opportunity.
This stopped abrupt when achieving a certain age.
Working for credit scoring
Experiences were positive because:
- Nice and friendly scrum master doing his work well
- Professional good cooperation by collegues in solving many issues in data quality and DTAP challenges. The functionality developed learning from mistakes.
- Several interesting projects with peculiar constraints to solve in operations and analyses
The challenge for better predictable quality was needed in their market competition.
- 🙏 Nice colleagues and support when all was new.
- 🙏 Open for the innovative ideas while building them up.
Working for health insurance
Experiences were positive because:
- Nice and friendly people to work with
- Learning something new about peculiar information health processes.
Working for health regulator
Experiences were positive because:
- Nice and friendly people to work with
- Leering something new about peculiar information health processes.
The challenge for rebuilding the information inquirys was by technical and functional debt.
- 🙏 Nice colleagues & managers to work on something new.
- 🙏 Supporting the new innovative approach in their innovative data process.
Working at technology for a conglomerate including health insurance
Positive experiences because:
- Nice and friendly people to work with
- A collegue curious in learning something new.
Challenge: technical debt, not understanding well fucntionalities while outsourcing tasks.
- 🙏 Nice colleagues, management at supporting what was not understood.
- 🙏 Handing over knowledge and getting into a new idea Jabes.

D-3.6.2 😱 Experienced negativity by activities
Working at big government environment.
❶ There were many internal frictions mostly hidden.
- A department wanting to have access to anything so they can run and delivered reports at requests.
- Regular IT departments blocking facilities for innovations.
- Lack of internal vision: sharing knowledge - information in another pivotal set than the operational administration use.
Those probably escalated at a moment in a public distorted rumour resulting into new reorganizations and regression reverting innovation.
❷ Complexity changing a pivotal orientation, I blew up :
- the file system by the huge number of involved intermediate files
- an advanced DBMS analytics system having a bug in processing XML files
Due those technical challenge is was not possible handing over the knowledge.
Working at technology for a conglomerate including health insurance
A mistake in organisational and political setting in security.
Detect en defend activities having a lot of staff.
Expecting deter, preventing at the same level was wrong.
D-3.6.3 🤔 Ambiguity complex uncertain volatile emotions at activities
Working for health insurance
There was no good fit in working culture, for me it was far too fragmented missing the vision to missions.
Working at technology for a conglomerate including health insurance
Although I am positive in the end there were weird situations - activities
- A reorganisation by external advice breaking up what was done.
- A classic fall back to externals more in panic while continuity became not understandable undetermined problematic.
D-3.6.4 ✅ Lean reflection into the future
Mc-Kinsey 7s model (1970)
Starting point: Overall organisational strategy designed to achieve goals using shared values.
See:
7s
| | clarification |
| Skills | Capabilities, competencies possessed by employees and the organisation as a whole |
| Staff | Human resources, their allocation and deployment within the organisation |
| Structure | Organisational structure and hierarchy |
| Systems | Processes and procedures that govern how work is done and decisions are made |
| Style | Leadership and management style exhibited within the organisation. |

The Information Age
What have we learned not only in our own circle and where is it going to?
From: "power to the edge" Alberts Hayes -2003-:
With the cost of information and its dissemination dropping dramatically, information has become a dominant factor in the value chain for almost every product or service.
As the costs drop, so do the barriers to entry.
Hence, competitors in many domains are seizing on the opportunity provided by "cheap" information and communications to redefine business processes and products." (73)
Organizations that are products of Industrial Age thinking are not well suited for significant improvements in interoperability or agility. (56)
Outputs are the products/services valued and paid for by the business customers.
Mc-Kinsey 7s extende into 12S-9plane
💡 Adding five additionals, managed by a "servant leader" for strategy by shared values.
| | clarification |
| Social-intelligence | the ability to understand one's own and others actions |
| Supply-chain | a network involved in the production and delivery of a product or service |
| Suppliers | is a company or individual that provides goods or services to another company |
| Service/Product | a named collection of business capabilities valuable to a defined customer segment |
| Serving-customers | doing useful work for them |
Service product flow (pull push): 9plane lean model, applicable at each of the 5 rectangles.
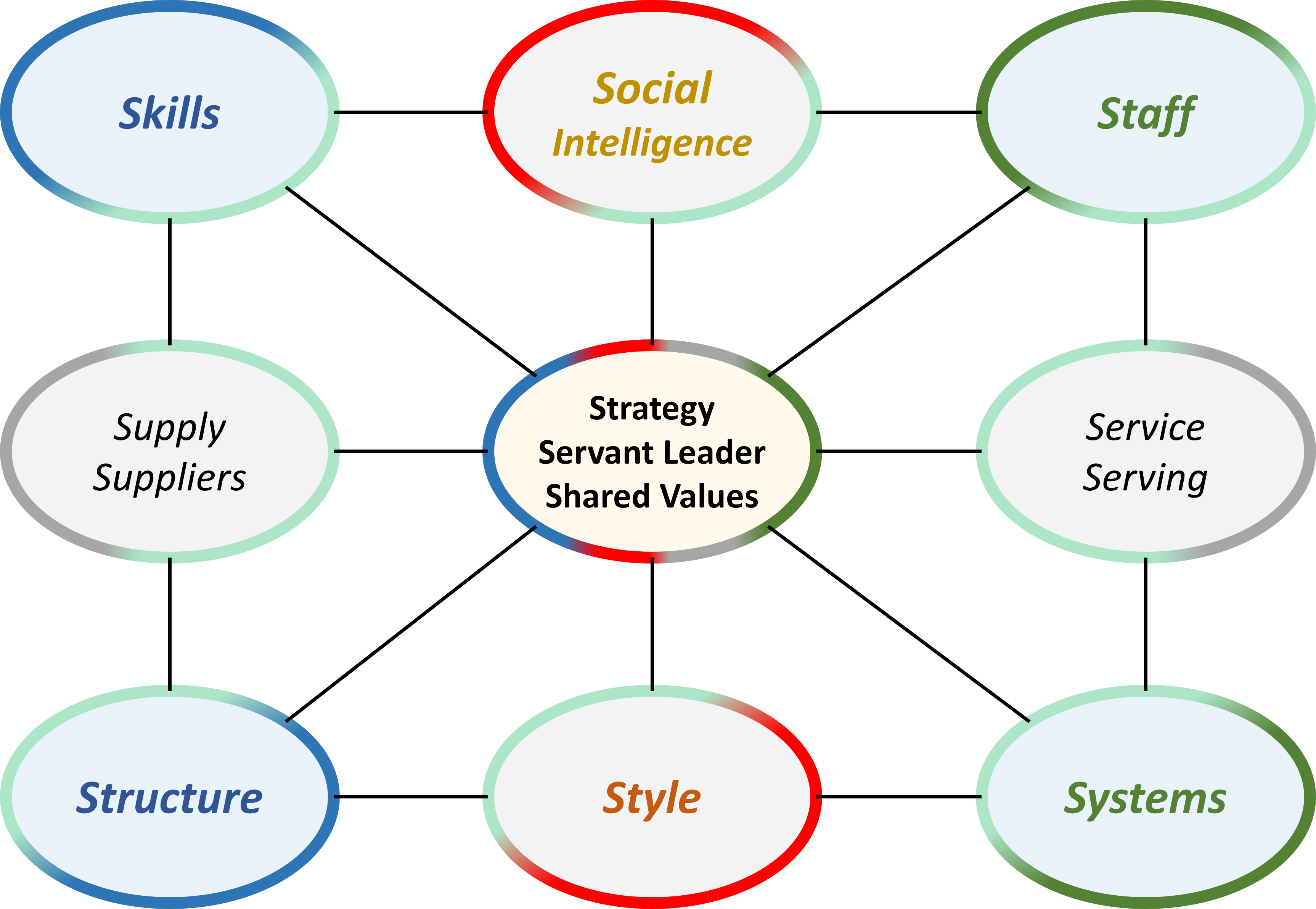
In a figure,
see right side:
© 2012,2020,2024 J.A.Karman