Devops Data - practical data cases
Scheduling Plannings
Schedule Patterns as operational constructs.

Scheduling, why is it critical?
There are a lot of questions to answer:
📚 Information data is describing?
⚙ Relationships data elements?
🎭 Who is using data for what proces?
⚖ Inventory information being used ?
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.
Contents
| Reference | Topic | Squad |
| Intro | Schedule Patterns as operational constructs. | 01.01 |
| Plan tasks | Planning task operations, scheduling. | 02.01 |
| schedule code | Scheduling of code units (software). | 03.01 |
| concept scheduler | How does a Scheduler running programs work. | 04.01 |
| smpl-SAS | Building your own scheduling (SAS example). | 05.01 |
| What next | Scheduling - Executing & Optimisations. | 06.00 |
| | Following steps | 06.02 |
Progress
- 2020 week 05
- Page getting filled.
- New content, gathering old samples.
Duality service requests

sdlc: The operational production process is covered.
There are unknown open issues at development and testing.
bianl: A problem exists when not knowing for sure whether it is an operational question, legal reporting, or non critical detailed management information.
Legal reporting requirements have many manual verification steps and deadlines quarterly yearly. No need to be automated.

bpm tiny: When there is not that much work to schedule, not automated manual instructions is an option.
The cost and effort of an complex tool to manage a limited amount of work not the problem to solve.
bpm big: In a big environment running many units of code on many machines with a lot of dependencies cannot go without automated managed schedulers.
All these processes are needing monitoring and communication lines, a service for information consumers.

Planning task operations, scheduling.
Scheduling, planning is for optimizing the work that is to be done.
It all starts and ends with understanding the process going to focus on a small part.
When having the important events in the complete process cycle monitored, analysed for understanding, better choices for improvements are possible.
Planning scheduling, values stream
A full circle of a process is something like the following figure:
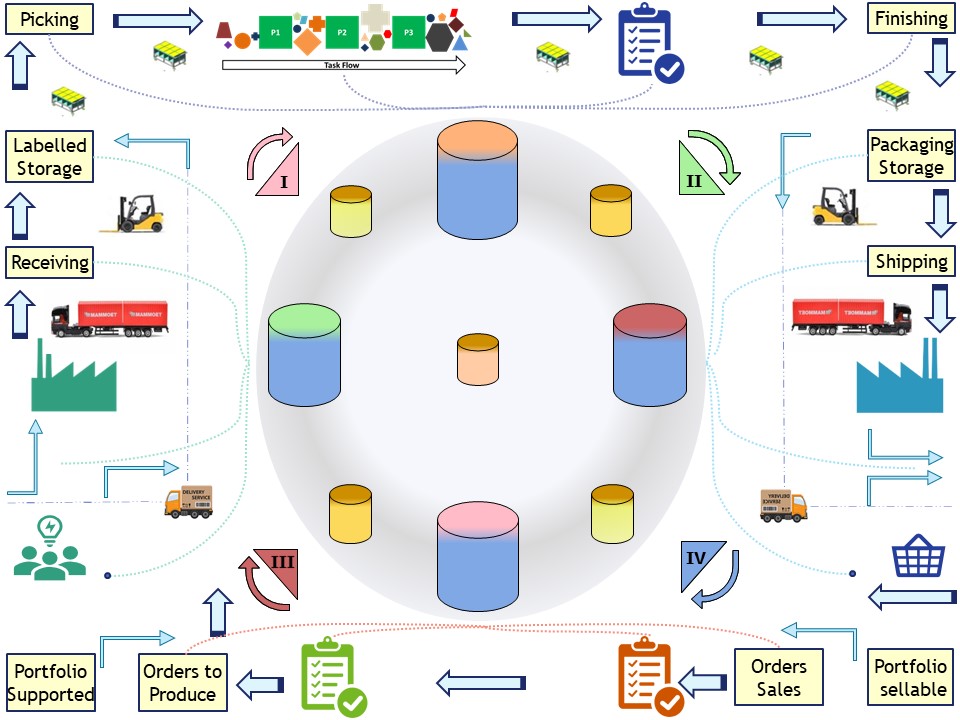
It depends not the real situation how to fit this. A local sub-process is following the same cycle as the overall one.
The communication on administrative and analytics parts is not in scope although they could be used when present and applicable.
Priorities, planning
With a local sub-process a machine
quick changeover or single minute exchange of die (SMED) is an example of planning scheduling tasks of workers.
However, as with any improvement project, the first question you should ask yourself is, "Is this my biggest problem right now?"
As always, you should have an overview of the problems you are facing and have them prioritized. 👓
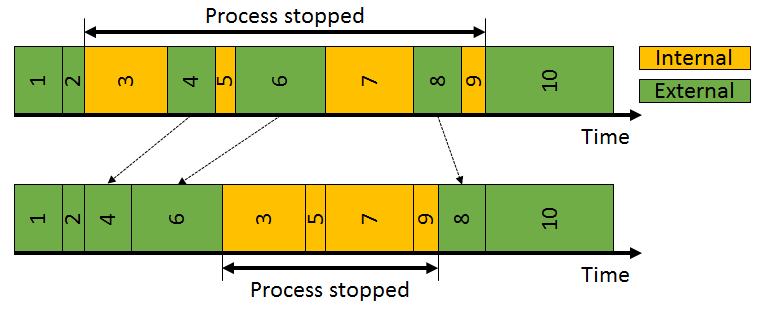
With the machines and human workers having the option of working in parallel, minimizing dependencies waiting on each other can reduce a cycle time.
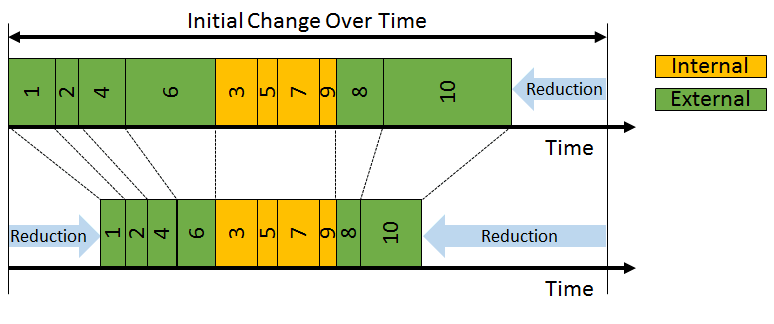
When the processes of each are serialized, the one impacting the total cycle (machine internal) to optimize and the reduction of workload (human external).
👓
A flexible manpower line never works for all possible numbers of workers equally well. I highly recommend not wasting the time of your workers through waiting just to achieve a takt time target!
The scheduling, planning of work has the goal of reduction in cycle time, achieving the expected time of "work done" and reducing the workload.
There are many examples of this in other area´s where something needs to be done in some time.
The goal is not the ultimate solution for a case but an acceptable one that is delivered in time at acceptable cost.
Planning running software processes
When the process is administrative or the business analytics using data and software, the tool for execution is the scheduler.
In a not very complicated situation the running of code could be done manually. The staff doing this is: "operations".

Scheduling of code units (software).
Scheduling is part of running processes, software code units. Confusing:
🤔 Building programs, the word job is used. In this context, code unit.
For building a process flow, having start and end, the word job is used at the operations. The flow is the element, service communicated.
Process steps in a single unit of code.
Instead of letting the operations department do the scheduling, developers are tempted to do all the code in a single program (monolithic).
Having tools that are supporting this avoiding doing manual coding this is even more likely to happen.
Using an Etl tools to build a data flows could look like:
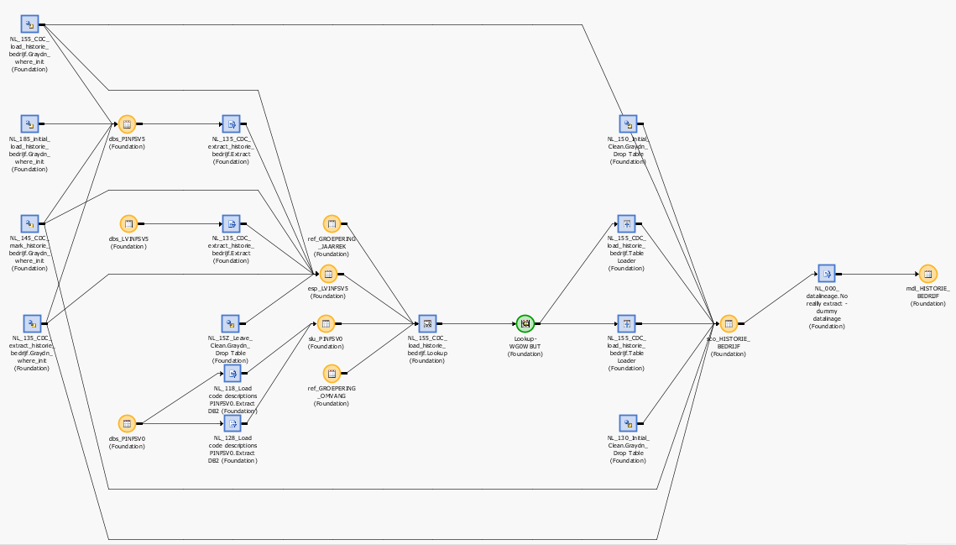
Blue squares are representing processes(transformations), orange circles data tables. In this flow (monolithic job/program) many tables are got processed by transformations.
Behaviour:
- All the processes in this code has to run sequentially.
It is sometimes possible to break this with run parallel loops. This is for not too big datasets with a repetitive type acceptable.
- There is no clear condition code of the job defined nor visible.
- There is no clear initialisation visible.
Dependencies in this job are visible for tables and transformations, between code units not. How the flow of an element, part of an table goes is possible when the tool is supporting an impact analysis on that level.
Process steps in multiple code units.
Building flows of code units is instead of defining blocks of transformations, "the program" or "the job" about defining blocks of programs.
The developing of the flow should go coordinated with the developing of the system developing the code units.
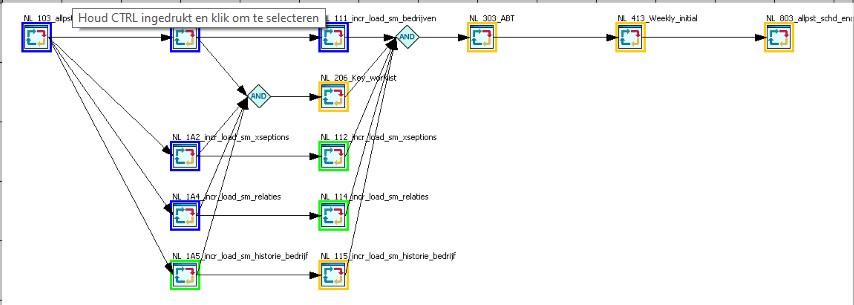
Blue squares are representing jobs in the flow that are ready, green what jobs are running (multiple simultaneous), yellow which ones are waiting and red when there is one in error, awaiting manual intervention.
Develop - operations: Standards.
Acceptance criteria operations - scheduling:
- Every job must have documented dependencies in:
- date-time
- file-data triggers
- other jobs
- Every job must be clear in the return codes being used.
What to do when the system condition code, syscc, is not 0.
The value 0 is indication for a successful process.
- Every job must have a predictable acceptable run-time to end.
- run times for jobs that can run parallel preferable in the same order.
- There must be documented what can parallel and what not.
Updating datasets data will lock out another needing the same data.
- Every job must be restartable without code modifications.

How does a Scheduler, running code units, work.
When understanding how a scheduler works and how you can build your own implementation you can better make use of the advanced features that are found in advanced commercial products.
Functional design of acheduler
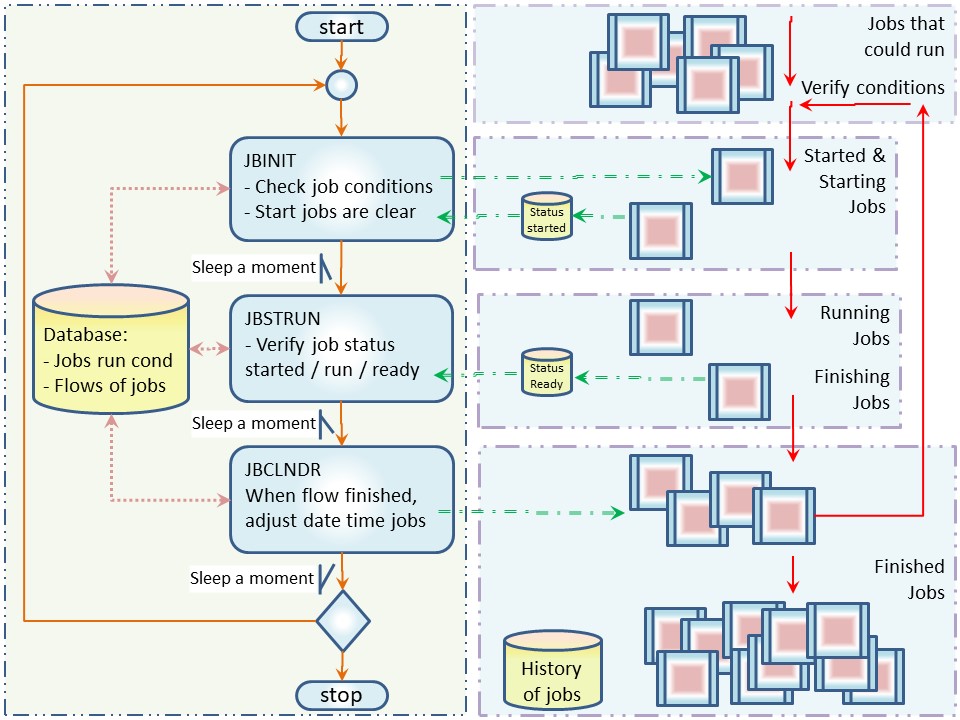
A scheduler as having two area´s of interest, those are:
- the workarea of human operator for scheduling (left) and the scheduler tool.
- The business jobs running an area segregated in tenants with different responsibilies on involved information.
The scheduler controls the life cycle of jobs to run for the business. Communication is possible by a using database, however using flat files is more robust.
A note for supporting the scheduling environment is cleaning up events, flat files when things are having gone out of sync. When the scheduler tool crashes and misses some of the signals it might incorrectly leave files behind.
A commercial scheduler
LSF (IBM) ,
CA-7 (Wikipedia note) are following this.
Sales pitch of LSF:
IBM Platform LSF is a powerful workload management platform for demanding, distributed HPC environments. It provides a comprehensive set of intelligent, policy-driven scheduling features that enable you to utilize all of your compute infrastructure resources and ensure optimal application performance.
Building blocks, assets in scheduling.
The following ✅ is needed and 🤔 for advanced implementations:
- ✅ communication status handling of processes.
- ✅ communication progress of processes.
- ✅ Starting another piece of code unit to run.
- ✅ Options to save information in files and in a relational table.
- ✅ condition checks associated with events.
- ✅ Grouping of jobs in flows.
- ✅ Calendar and time functions.
- 🤔 Balancing usage of system resources.
- 🤔 Prediction on expected end time with repriotize running jobs.
- 🤔 Failover with an usage in cluster, multiple machines - scaling out.
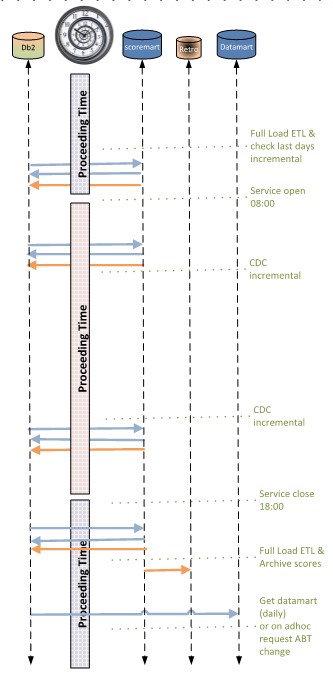
Planning a daily load
Before code and flows was build the requirements for the business has given a plan when what kind informations is needed for who and the which sizes to expect.
The exact how is implemented in the out of office and office hours.
In this example the "out of office" time is used for full loads. They have a not neglectable impact on network traffic.
During office hours at very regular moments there update flows run. The resulting effect is a near real time situation during office hours with this application.
Another flow application having other requirements mostly in office hours.
The big sized data transfers still planned outside office hours.
Having many small an different updates, that must possible corrected in time, all collected before the critical important application flow runs.
The planning scheduling of flows and processes is with awareness of the limitations of available computer resources and performance.

Building your own scheduling (SAS example).
Using a test environment, usage the operational approach will result in having no tests can be done. For tests date - time travelling is required.
Also supporting the parallel work of several teams on projects is having some generic coding guidelines.
A scheduler build in base SAS
1. ✅ communication status handling of processes.
macro variable SYSCC:
SYSCC is a read and write automatic macro variable that enables you to reset the job condition code and to recover from conditions that prevent subsequent steps from running.
A normal exit internally to SAS is 0. The host code translates the internal value to a meaningful condition code by each host for each operating environment.
&SYSCC of 0 at SAS termination is the value of success for that operating environment´s return code.
macro variable SYSRC:
he code returned by SYSRC is based on commands that you execute using the X statement in open code, the X command in a windowing environment, or the %SYSEXEC, %TSO, or %CMS macro statements.
Return codes are integers. The default value of SYSRC is 0.
You can use SYSRC to check the return code of a system command before you continue with a job. For return code examples, see the SAS companion for your operating environment.
Source from the: SAS Macro Language Reference
2. ✅ communication progress of processes.
Adding something to see start and end of a process.
- 01 config: initstmst, termstmt
- 02 autoexec: use of %include for calling the code unit putting some standard code in front and after.
config initstmt:
INITSTMT= specifies the SAS statements to be executed at SAS initialization.
TERMSTMT= is fully supported in batch mode. In interactive modes, ....
An alternate method for specifying TERMSTMT= is to put a %INCLUDE statement at the end of a batch file or to submit a %INCLUDE statement before terminating the SAS session in interactive mode.
Source from the: SAS System Options Reference
3. ✅ Starting another piece of code unit to run.
Starting another piece of code unit has many options:
- 01 calling other code: %include srcloc(codeunit_nnn)
- 02 generating code: dosubl
- 03 mpconnect run code: rsubmit
- 04 Start proces on os: sysexec , pipe
4. ✅ Options to save information in files and in a relational table.
These are the basics of working wiht SAS.
5. ✅ condition checks associated with events.
6. ✅ Grouping of jobs in flows.
7. ✅ Calendar and time functions.
Are all basis functions in SAS.
All technical requirements for building a scheduler are present. Coding work to do a generic realisation is a case having done.
The size of code is not that huge.
SAS code examples private scheduling:
| Code source | Description |
| xwr_start | Loop calling JBINIT JBSTRUN JBCLNDR. |
| xwr_jbinit | JBINIT check conditions, job submit. |
| xwr_jbstat | JBSTRUN verify job status. |
| xwr_jbclndr | JBCLNDR flow adjustment for datetime. |
| xwr_jbcreate | JBCREATE read txt file into WR control dataset. |
Additional addons used in examples private scheduling:
| Code source | Description |
| --- | initstmt giving process started information. |
| --- | termstmt adding process ended information. |
| --- | read text file definitons aboout jobs and flows. |

Scheduling - Executing & Optimisations.
Pattern: Design units of software code suitable to use with scheduling tools.
Developing an application system should align the coding units, scheduling of flows, performance and load of the applications system.
The flow being build and tested during development. Dependencies and performance evaluated during develop and test.
Pattern: Build units of code with a "system return code" - " extit code".
Code units are generating a log with messages by default from a runtime coding environment. These should not be used for the signalling of how the business process was ended, succesful or not.
The system condition code should used for the indication of having succesful procesed.
⚠ Coding guideline for Business: write condition code logic .
Pattern: Plan processing avoiding resource conflicts in locking and capacity.
⚠ Coding guideline for Business: An approach to achieve restartability and avoiding locks is having only one logical unit being updated in a job.
⚠ Coding guideline for Business: Make code units not having that many transformations that they are running unnecessary long. Split code units in parts that are easily run.
Pattern: Use experiences from the past and expectations for the future.
Any application system will change when the business is changing. Having flexibility following the fast changes is by good practice keeping things simple. A big design upfront as the ICT goal is to avoid.

Forgotten history.
Performance & Tuning once upon a time was an important skill. The free lunch by hardware improvements led to ingore those basics at implementation.
🚧 Systems going into a
thrashing behavior not being recognized. Scheduling has many goals, one of them is avoiding this.

Historical outdated habits.
🚧 The operator once upon a time was the only one allowed entering jobs into the computer. He was also the one that did the planning for all flows manual.
Indeed it was the only workable to do things in the hollerith card usage age.
Surpisingly al lot of this is still is practised in working habits and who is allowed to use a tool.
🚧 The operational production system with the scheduler all to often is not implemented with segregation in duties and not with a segregation in tenants.
The escape for that is implementing a machine environment for every application.
This is creating a lot of complexity and overhead in the number of machines.
Dependicies other patterns
This page is a pattern on scheduling.
Within the scope of metadata there are more patterns like exchaning information (data) , building private metadata and securing a complete environment.
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.