Devops Meta - private metadata governing data as context
Contents & topics private metadata Data governance
Patterns as operational constructs.

private metadata, why is it critical?
There are a lot of questions to answer:
📚 Information data is describing?
⚙ Relationships data elements?
🎭 Who is using data for what proces?
⚖ Inventory information being used ?
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.
Contents
| Reference | Topic | Squad |
| Intro | Patterns as operational constructs. | 01.01 |
| Foundation | Why using a private metadata. | 02.01 |
| define private meta | Defining a full domain private metadata. | 03.01 |
| private meta pull | Use full private metadata & derivates (pull). | 04.01 |
| private meta push | Use full private metadata & derivates (push). | 05.01 |
| Pattern chain | Defining the chain - Transformations. | 06.00 |
| | Dependencies other patterns | 06.02 |
Progress
- 2020 week:02
- Set up private metadata as contiunation of the pull push data request pattern.
The concept is generic but not supported by common toolsets.
Duality service requests

sdlc: the naming an description gets either hidden behind user front-ends or are becoming a vocubalary by those that are working more directly with data.
bianl: A complete pull psuh delivery for information is possible having all those elements defined. A descriptions for human readability is going along.

Why using a private metadata.
With a "private metadata" approach, my goal is to have a well defined table having the descriptions for all data elements being used.
This table should be available in the data transforming an data generating process in a way coding efforts are minimised by using generic patterns.
The full process circle transforming and generating information.
Information is input for the process represented by data. The output delivery is also data. The horizontal flow from left to right.
Intermediate data is used during the pull request or push delivery. They are to be found on the vertical axis.
Information / data is processed by code guided by metadata. When code and metadata are cooperating the the structure becomes a standard pattern.
code with the metadata is found on the diagonals. Having four stages it is a circular process.
In a figure:
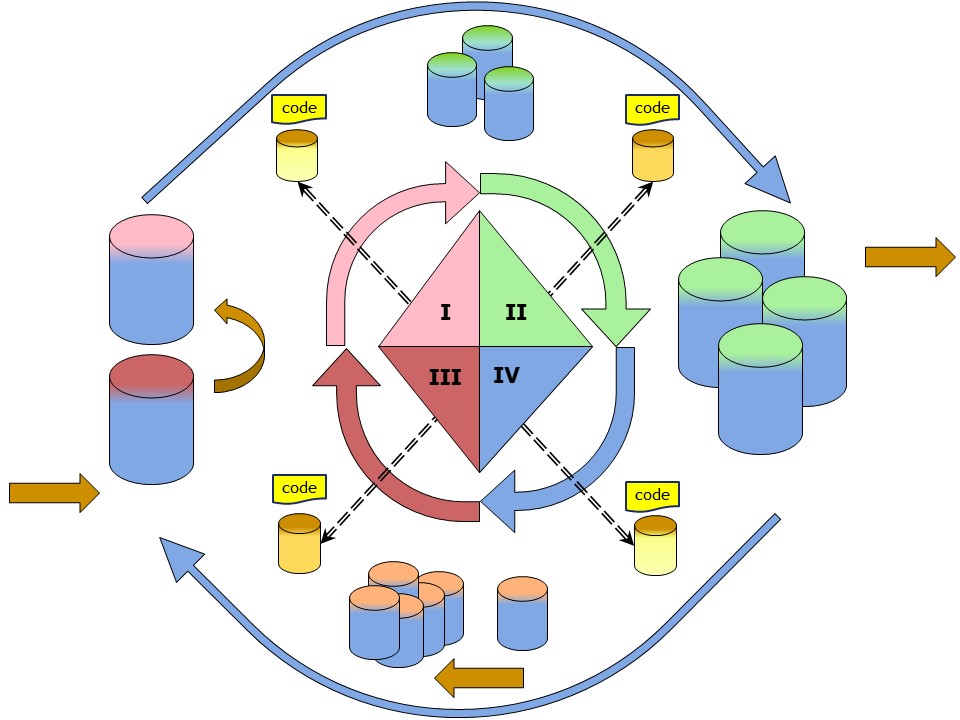
Stage four is the verify and planning of elements that are needed or nice to have.
The model pattern in this figure is acknowledging all four stages.
Standard ERP and DWH solutions are avoiding that stage IV, minimizing balance and checks in III.

Defining a full domain private metadata.
A full domain is having all descriptions with different versions of an element by unit size corrections and time displacements.
This is obvious adding some duplicates that after adjustments in element value and/or key identifiers will disappear.
Using the full private metadata IV III I
Without private metadata all logic must be build using data model structures.
Focussing on the code with cooperative private metadata is directing the thinking on what transformations are needed.
A structure for a metadata model hierarchy is like:
- 🎭 Specification variable definition
- The owner information domain.
- High level subarea within the owner.
- Within the high level subarea an collection identifier for a similar topic and similar interval deliveries.
- Whether it an delivered value or calculated one on what has delivered. (cross check content)
- Rubric indicator(s) valid for the collection identifier
- 🎭 Specification variable definition
- An global element identifier for what the element values is describing.
eg: male - female - human in numbers possible by age groups
eg: booked amounts, estimates, expected total amount.
- Some code preferred reusing those that already are in use. Describing the intention and meaning of the elements.
- 🎭 Specification variable definition
- The goal is making it an unique detailed code for this element.
When there is already some conventions in use that one to copy.
- ⚙ Attributes
- Version type of the element value for unit corrections
- Time (date) displacement used for this element adjusted to time (date) key identifier value of the delivery.
With private metadata supporting logic data models are build in an assembly line to become useful.
There are undefined intermediates that wil be a result of proces transformations. In a figure:
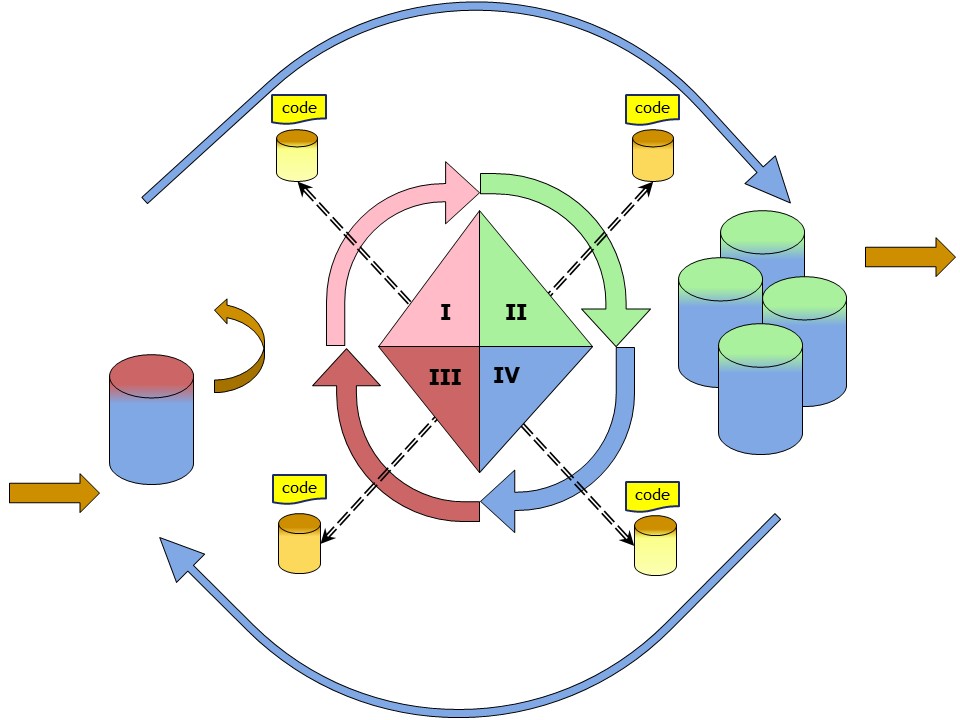
When the input is already having multiple columns the transpose possible is still a needed construct.
This will happen when the taget object analysis in the output is different on what is in the input.

Use full private metadata & derivates (pull).
Having set what the key values for the private metadata table should cover and what the basic four identifiers are, realisation starts.
There are limitations by used tools. In my real life experience SAS Excel and Oracle was used. The examples here are based on that.
There is a limit of 32 characters for a variable name. No limit on the number of columns. Other limits were not relevant.
Making variable naming as simple as is possible is by avoiding spaces and special characters in variable names, only the underscore is allowed.
The underscore is used to make a logical separation in the variable name.
In the program code variable names must be used that are not conflicting with the names in the private metadata. The private metadata table and other tables also needing a naming convention.
Usage for the table columns variables is a three level structure. The connection between levels made by the underscore.
- ($*) variable domain, eg: vcd (private metadata) state (data source)
- ($*) unique identifier, eg: spec spec1 spec2 spec3 attrib type
- ($*) usage type, eg: idvar (variable) idjmd (date content yyyymmdd format)
The full private metadata table
The private metatadata table looks like:
- 🎭 vcd_spec1_idvar $8 , logical key variable
- 🎭 vcd_spec2_idvar $8 , logical key variable
- 🎭 vcd_spec3_idvar $8 , logical key variable
- ⚙ vcd_attrib_idvar $8 , logical key variable
- ⚙ vcd_dsnorder_flt 8 , a number intention: order transposed columns
- 📚 vcd_datatype_txt $2, choice of multiple datatypes stored with the element
- 📚 vcd_format_txt $14 , string intention: content column presentation
- ⚙ vcd_units_flt 8 , a numeric: used to adjust element value by a calculation
- 📚 vcd_units_txt $32 , description of used units, eg: age days ammount
- 📚 vcd_description_txt $256 , description of the element
- ⚙ vcd_validfrom_idymd $8 , element is valid from (date yyyymmdd)
- ⚙ vcd_validthru_idymd $8 , element is valid until (date yyyymmdd)
With an compound index on the key variables and having it sorted in the order of the index, performance will not raise questions.
Using private metadata IV (template)
Required are four columns in an excel table on an reserved sheet with the goal of datatransport.
After the excel table has been retrieved the other columns of the private metadata are joined (key lookup).
The four columns are:
- ⚙ vcd_spec_idvar $8 , logical key variable
- 📚 vcd_value_flt , element value - numeric
- 📚 vcd_value_txt , element value - text
- ⚖ vcd_description_txt $256 , description of the element
Remarks:
- The vcd_spec_idvar is an combination of all four key variables separated by the underscore. As first column the excel VLOOKUP is usable.
- The Excel CEL function is able to deliver the spreadsheet name as text.
This is a marker for the process and filled during upload.
- Some other marker and identifiers are there. The identifiers who has delivered and what template is used are mandatory.
State type with the state moment are two identifiers because the template has possible high variety.
- The description is not really required but for human readability strongly recommended.
Using private metadata III (staging)
There are only two column variabeles having values stored in a row. All other columns are identifiers or markers on when the elements have been processed.
This is a minimized set of what is needed to store and archive any element. The sizing of the dataset can kept small when partitioned on eg years from state_type_idjmd.
- 🎭 state_type_id $4 , delivery type limit to logical domain
- 🎭 state_type_idjmd $8 , delivery type version by date yyyymmmdd
- 🎭 state_entity_id $4 , entity logical key value that has delivered
- ⚖ state_entity_idvrs $2 , indicator delivery updates by corrections
- 🎭 vcd_spec1_idvar $8 , logical key variable
- 🎭 vcd_spec2_idvar $8 , logical key variable
- 🎭 vcd_spec3_idvar $8 , logical key variable
- ⚙ vcd_attrib_idvar $8 , logical key variable
- 📚 vcd_value_flt 8, element value - numeric
- 📚 vcd_value_txt $1024, element value - text
- ⚖ state_digestion_idmut 8, timestamp on when the elements where processed

Use full private metadata & derivates (push).
In the push stage the attribute key must be removed by deduplication. The result is an deduplicated version of the private metadata table (vdc)
Adding calculations (calc) is a new part of private metadata. Adjusting values and adding adjusted keys.
Using private metadata I (semantic)
Before wanted tables are possible to create, adjustments in values and keys are done in an intermediate step.
Selecting ad period reduces the size of data in working process. The table name this element is going to is defined.
- 🎭 state_type_id $4 , delivery type limit to logical domain
- 🎭 state_type_idjmd $8 , delivery type version by date yyyymmmdd
- 🎭 state_entity_id $4 , entity logical key value that has delivered
- 🎭 state_enttygrp_id $4 , entity logical key value that has delivered
- 🎭 state_enttynow_id $4 , entity adjusted valid now value
- 🎭 state_enttynow_idjmd $8 , adjusted element date reference yyyymmmdd
- 🎭 state_tabletyp_id $32 , name of the intended table
- ⚖ state_entity_idvrs $2 , indicator delivery updates by corrections
- 🎭 vcd_spec1_idvar $8 , logical key variable
- 🎭 vcd_spec2_idvar $8 , logical key variable
- 🎭 vcd_spec3_idvar $8 , logical key variable
- ⚙ vcd_attrib_idvar $8 , logical key variable
- 📚 vcd_value_flt 8, element value - numeric
- 📚 vcd_value_txt $1024, element value - text
- ⚖ state_digestion_idmut 8, timestamp on when the elements where processed
- ⚖ state_semantic_idmut 8, timestamp on when the elements where processed
Creating and adding calculation definitions
Additional private metadata is added for adding calculations on the data. A list of possible elements is checked with elements that actually are present, removing the ones that do not exist.
The calculation metatadata table looks like:
- 🎭 vcd_spec1_idvar $8 , logical key variable
- 🎭 vcd_spec2_idvar $8 , logical key variable
- 🎭 vcd_spec3_idvar $8 , logical key variable
- ⚙ vcd_attrib_idvar $8 , logical key variable
- ⚙ vcd_dsnorder_flt 8 , a number intention: order transposed columns
- 📚 vcd_datatype_txt $2, choice of multiple datatypes stored with the element
- 📚 vcd_format_txt $14 , string intention: content column presentation
- 📚 vcd_units_txt $32 , description of used units, eg: age days ammount
- 📚 vcd_description_txt $256 , description of the element
- ⚙ vcd_postcalc_txt $8 , an indicator of what calculation to do
- ⚙ vcd_chkvarlst_txt $1024 , list of elements that should be present
- ⚙ vcd_calvarlst_txt $1024 , list of elements used in the calculation
The result of the metadata table (def) that is created has the same structure. It gets a name of table that will be created with suffix "e.def".
Using private metadata II (delivery)
From staging the goal is delivering tables with columns having elements to analyse and useful key variables for identification and grouping.
This transpose formation in the figure is the logic:
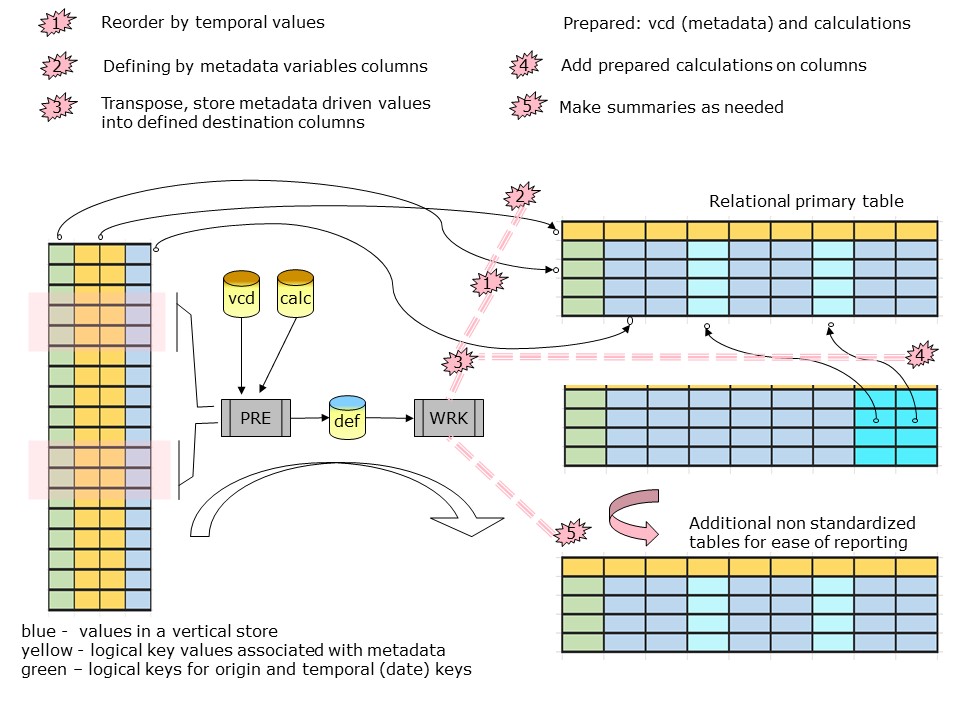
💡 repeating this process for all wanted tables, identification and grouping. The focus is possible on an entity or on elements.

Defining the chain - Transformations.
Pattern: Information private metadata.
Make the logical processing guided by private metadata.
- Define a full private metadata table
- Have all data elements being described by the full private metadata table
- Add another private metadata table for calculations in the push stage
- Let every stage (IV III I II) run under control of the private metadata
- Run the process transforming data with small set of code (sources)
Remarks:
- This approach should be possible with a lot of other tools.
- At stage IV using Excel the values may contain references to other sheets and references with calculations. Those calculations gives the opportunity to validate content strict when dependices are existing.
Required other Patterns.
💡 The Information pull request push delivery is complementary to this pattern.
Conflicting other Patterns.
⚠ The transposing of elements is not an standard transformation. It will work well in an analytics environment. For transactional operational systems it will be not responsive enough.
⚠ This approach breaks with the modelling of the intermediate data (semantic). No star schema or data vault, only well described elements and an minimized set of transformations.
Imagine all data in the following figure is forced by a fixed structure (data model). The transformations can get very complicated. The worst scenario would be using this pattern four times (diagonals) solve that at the four stages.
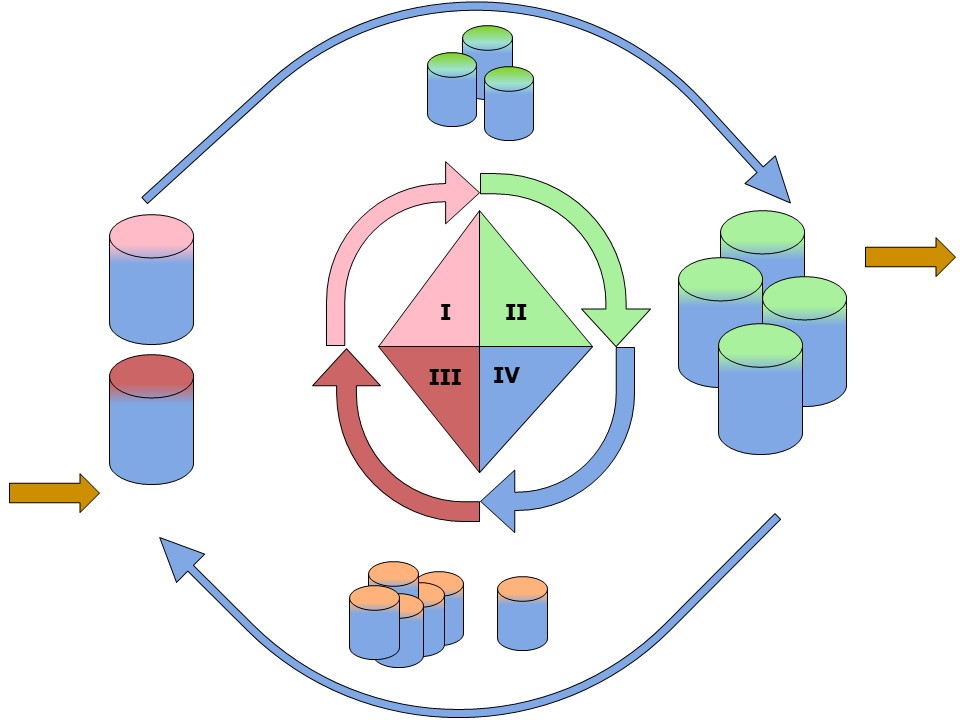
Dependencies other patterns
This page is a pattern on pulling request informations.
Within the scope of metadata there are more patterns like exchaning information (data, building private metadata and securing a complete environment.
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.