Devops Data - practical data cases
Patterns for quick good realizations
Data pipelines Patterns as operational constructs.

Etl performance, why is it critical?
There are a lot of questions to answer:
📚 Information data is describing?
⚙ Relationships data elements?
🎭 Who is using data for what proces?
⚖ Inventory information being used ?
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.
Contents
| Reference | Topic | Squad |
| Intro | Data pipelines Patterns as operational constructs. | 01.01 |
| Business Events | Business oriented process flow. | 02.01 |
| ETL control I | ETL ELT data pipe - Control (I). | 03.01 |
| ETL control II | ETL ELT data pipe - Control (II. | 04.01 |
| BI normalise | BI transformations - data lineage. | 05.01 |
| What next | ETL performance - Executing & Optimisations. | 06.00 |
| | Following steps | 06.02 |
Progress
- 2020 week 08
- Page getting filled.
- New content, gathering old samples.
Duality service requests

sdlc: These are standard processes conforming deadlines and data quality.
bianl: Living in another world. Other challenges to solve as of the operational ones.
Data quality still remains problematic. Adding necessity understanding value stream processes, request to delivery.

bpm tiny: Any tool, even a spreadsheet could give the information that is needed.
When becoming bigger and more complex it goes beyond what is understandable processed that way (analytics).
bpm big: Needing advanced tools with a clear vision to become a succes (analytics).
The tools are note leading the value stream and inforamtion how to manage that is.

Business oriented process flow.
Every business process has an request that delivers something. The request (pull) is the start for a cycle that is having input process and an output process.
There is fulfilment process from input to delivery.
A control process: request to fulfilment.
Generalized process flow
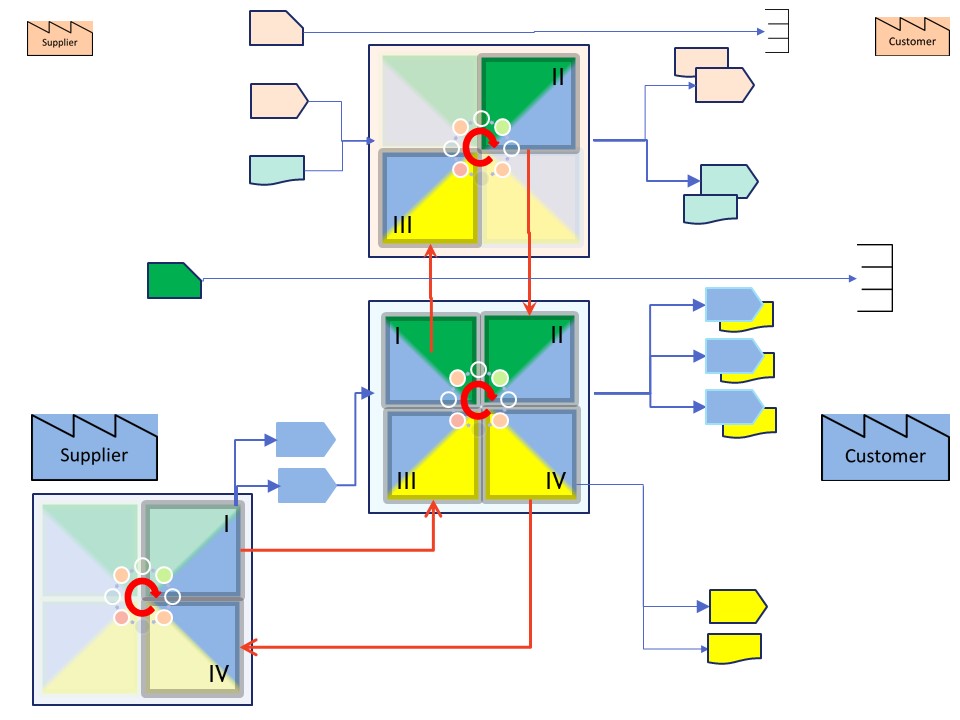
In a very abstracted figure:
🎭 The business proces in the center form supplier to customer
⚙ The needed machines (software tools) at the top.
📚 Objects that are necessary but manafactured elsewhere at the botom
The lines of needed machines and the objects manfuctured elsewhere are distractors for businees process.
Generalized process flow
Going for the business process it is the following figure. The business process steps are around the edges of the rectangle 1 - 9,0.
In the inner circle it starts at IV when the request is coming in, it ends at II with the delivery closing the loop into IV.
The flow of objects being manufactured is left tot right.
In a detailed figure:
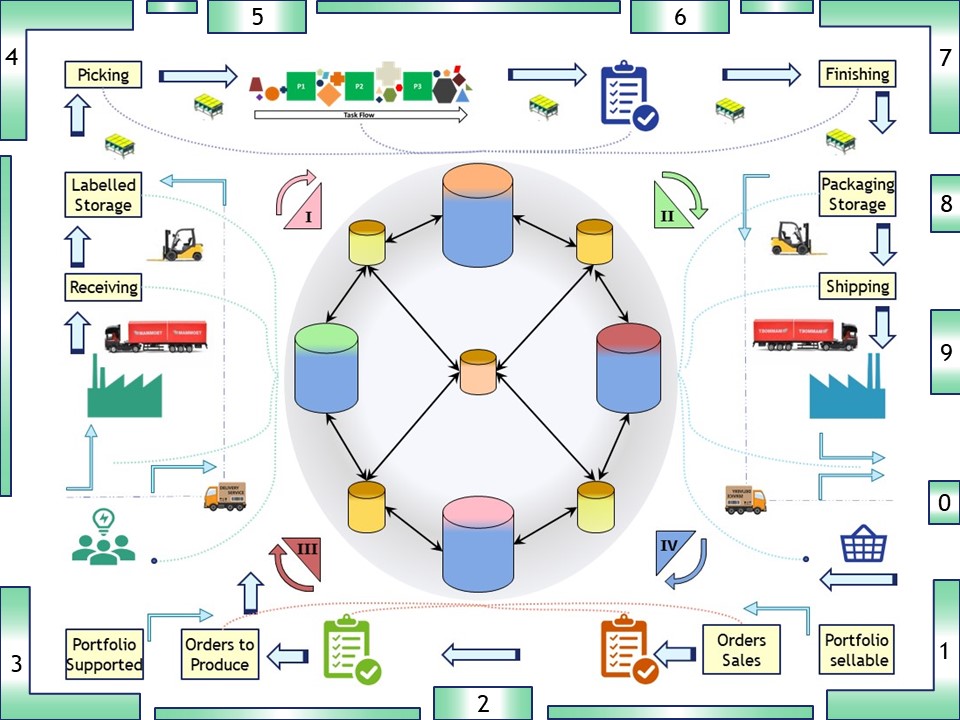
There are four (blue) containers for the administrative support, monitoring, etc four each of the four phases.
Doing analyses on information between those phases it result into eight (8) etl pipeline processes with four (4) warehouses between the phases.
This is breaking up the centralised single analytical warehouse into dedicated ones with just two of the four involved. The consolidation in the middle is the one that involves all four.
Breaking up in smaller parts makes the communications and interactions for each easier. An issue with an enterprise analytics warehouse is that it will become huge, complex and not solve all the demands.

ETL ELT data pipe - Control (I).
For doing Extract / Load processing there are many tools. There is a standard
CWM (Common Warehouse Metadata specification).
However doing that in real life some things are missing. That is control & monitoring of the transformations in the pipe line.
Generalized EL process flow
Standard have ETL tools their focus on are having the focus on the data flow, delivering data. There are two blocks:
- Retrieving data form the other system. (extract)
Changing technology between systems implies data transformation caused by data representations.
⚠ Characters, numbers, dates (datetime) usually have differences.
- Storing data into a permanent location usable for further processing.
Storing intermediate data on permanent storage type makes it restart able.
Knowing when the data size is relative big or small for choosing the best loading algorithms.
What is really missing is the initialisation (010) and closing (090) business logic. Once they were standard with structured modular programming.
Adding another two blocks:
- Logic which data / information should be retrieved.
💡 Time indicator and additional criteria to aligned (to other system).
⚠ generating variable code snippets is business specific.
- Monitoring what has been loaded and how it did finish at completion.
⚠ monitoring functionality is business specific.
Ending a process logic for correct finish or when having an abnormal end (aborted, abend, 0 - non zero)
A figure with those segregations is:
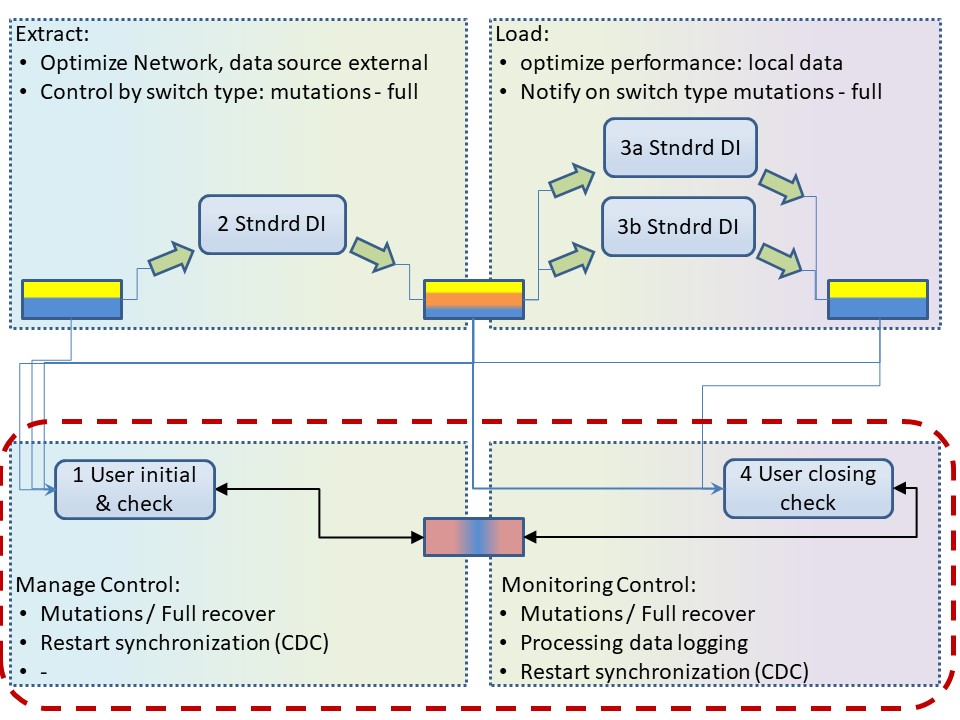
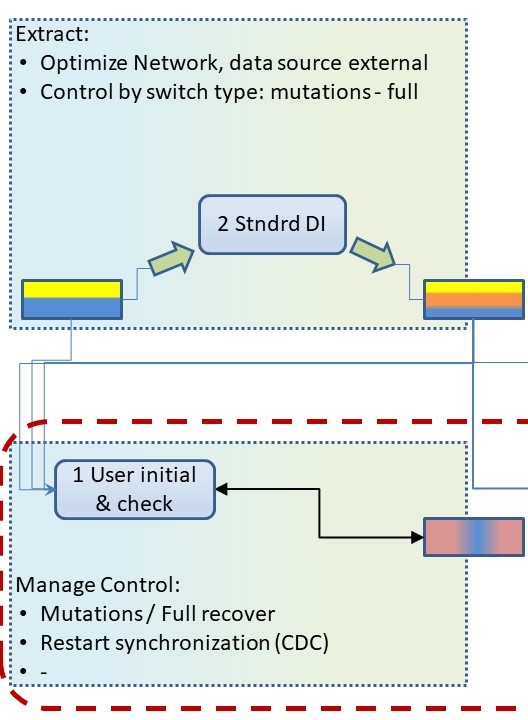
Needed is control on what data is to be synchronized.
✅ "no data" - With a job restart.
✅ "all data" - full load. (Destination not existing.)
✅ "all updates since last run" .
A control data set as input having the last run timestamps and retrieved data timestamps from identified records. The information used in dynamic code.
The combination timestamps and identifiers (records - elements) is specific domain knowledge.
An user snippet simplifies the initialisation coding.
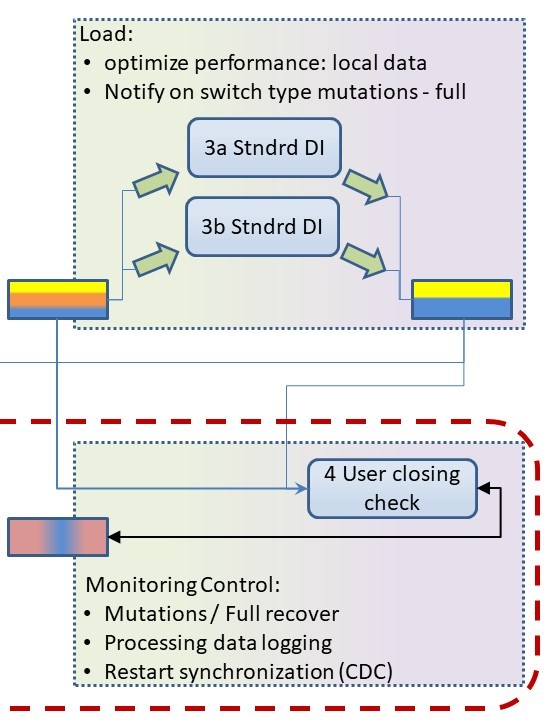
Reading is not having much issues with performance (elapse time), but writing - updating surely is.
What is needed is control on which action should run.
✅ "all data" (huge) - Optimzed sorted load, combined tuning preparation tuning for mutations.
✅ "updates since last run" - sorted mutations, updates and additions. Deletions to take note of.
Results are kept in the control dataset with time stamps, used logic and processed number of records.
An user snippet simplifies the termination coding.

Data Integration - Control (II).
Data integration is done with operations and analytics. When there are seperate operational systems in place, information (data) has to be exchanged.
An analytics enviroment will lead to different technical approaches at the solutions and the processing. Requirements are different.
Operational processes.
An operational system with a DBMS is designed with:
- avoiding storing duplicates of informations:
- normalised data model:
Database normalization is the process of structuring a relational database[clarification needed] in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity.
It was first proposed by Edgar F. Codd as part of his relational model.
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints.
It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design).
- use surrogate keys where business keys could possible change in content with the same meaning.
- Limited historical information, only what is normally needed.
- tuned for small number of updates, writing data, spread in time.
- avoiding deadlocks when two transactions would update the same information at the same moment.
- build with acid (wikipedia)
In computer science, ACID (atomicity, consistency, isolation, durability) is a set of properties of database transactions intended to guarantee validity even in the event of errors,
power failures, etc. In the context of databases, a sequence of database operations that satisfies the ACID properties (and these can be perceived as a single logical operation on the data) is called a transaction.
Operational information exchange.
Using separated systems, information is transferred and validated with deadlines in delivery moment and quality expectations.
Requirements are set for avoiding incidents and problems:
- Strict interface standards that are not allowed to change without consent of all involved parties. Enterprise Service Bus, Api´s.
- Procedures on missed deadlines and failed data quality.
Analytics processes.
None of the requirements of operational usage are really applicable to analytics usage.
A spreadsheet, NoSQL database, Olap, Analytical base tables that are single denormalised datasets are the ones that are used in an analysis.
💣 Connecting to the operational data exchange doesn´t make an analytics environment an involved party for interface changes.
Using interfaces to available data doesn´t imply for analytics the need to copy all columns all data that is there.
A selection of all that information will do.
⚠ The biggest challenge is: analytics is needing production data for developing the insight on what is happening and what to expect.
The classic Business Intelligence is reshaping all data into their own dedicated data models. Star models, 3nf and data vault all go for the RDBMS operational history.
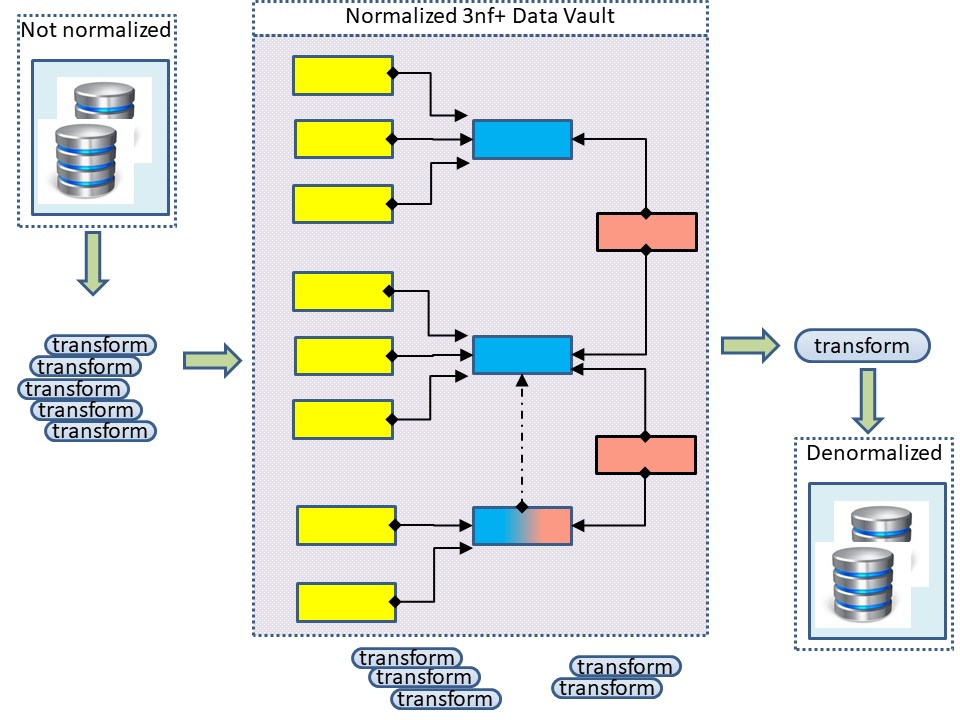
The resulting pipeline from denormalized datasets into a complex model with the goal of delivering denormalized datasets.
An alternative data model is by using "private metadata".
The International Standards Organization (ISO) proposes, in Understanding the Data Dictionary, three categories: Business Concepts, Data Types and Message Concepts.
Business Concepts define a business Metadata layer, as described by Zaino, as the ?definitions for the physical data that people will access in business terms.
Data Types describe formats for data elements to be considered valid. Message Concepts a shared understanding between institutions and companies to ensure business communications are within the same context.
These three Data Dictionary items: Business Concepts, Data Types, and Message Concepts interrelate to one another.

BI transformations - data lineage.
Doing transformations only having a focus on the functions to deliver is forgetting the technical requirements of an environment.
Ignoring those will easily result in a situation that is too complex and having too many issues in operational performance.
Structuring ETL processing coding.
Building coding should done in a way that is well structrured an good for operational usage.
The initialisation and termination is already mentioned as missing in guidelinges.
What more is mssing is structuring all the steps it can easily managed by a scheduler.
It is too tempting building monolithic ETL programs.
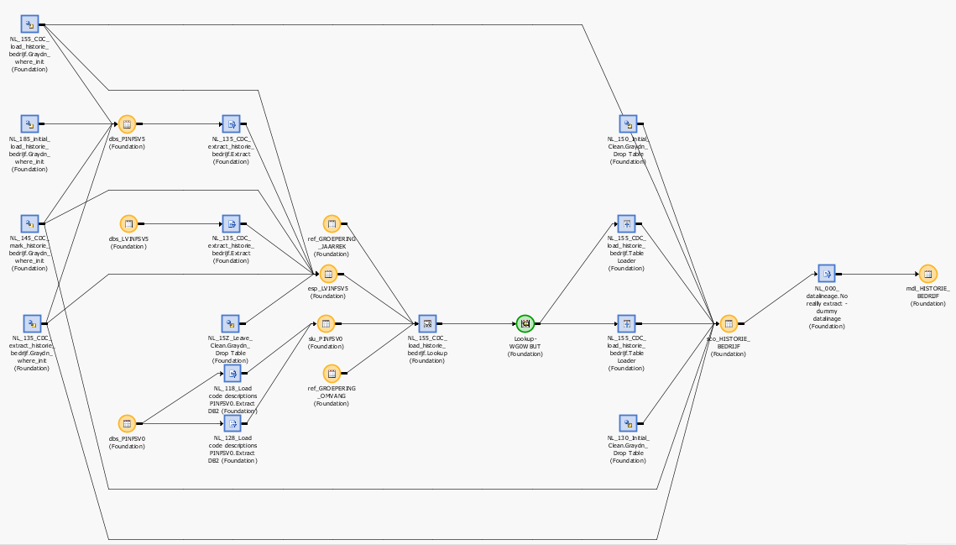
This is an example of a monolitic ETL program.
When doing data transformations following the flow is important metadata. Important to understand impact when changing something.
It is called
"data lineage".
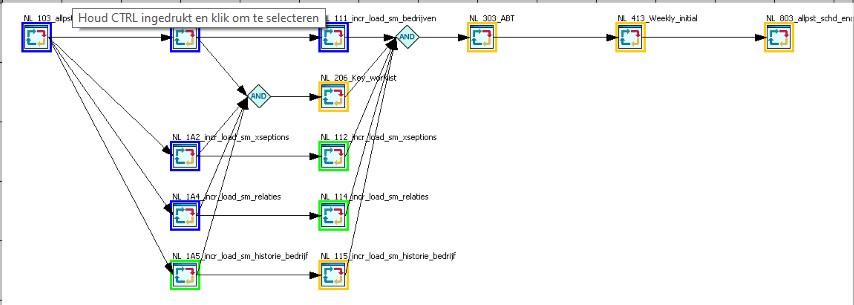
Having scheduling at the developing phase included can lead to this situation of more but smaller programs that run in parallel.
This is a modular structured approach.
Structuring ETL processing transformations.
⚠ ETL tool transformations optimised for a dedicated DBMS are not portable to another DBMS. Even SQL is not a standard language that is the same in every DBMS.
⚠ The data model using keys an datasets tables and the storage locations are not part of any tool in best choices for transfromtions. This is a developer responsibility.
⚖ The data lineage is a standard as long used in the same tool, user transformations are an option to build standards how to code as long it is bound to an organisation.
EL process monitoring.
The user generated initialisation and termination are using and maintaining a control dataset.
It used for logical functionality and for monitoring afterwards.
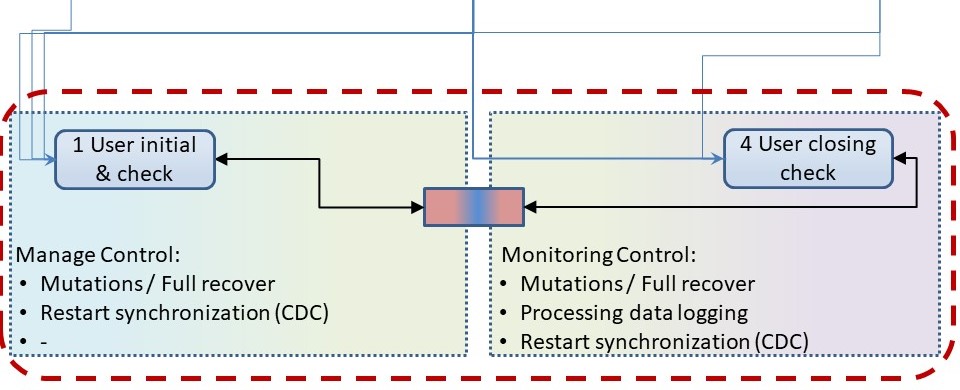
That control dataset is having specific domain knowledge.
Impossible to solve by CWM standards.
The control dataset is dedicated to the used tooling.
The assumption is that the operational source systems have the correct data. Not all data is allowed to be kept.
There are data retention policies that mandatory require to correct and remove data (inforamtion).
Following the sourc system avoids to implement the same mandatory retenion policies in the data warehouse.
Updates Adding data are easy. Deleting data data isn´t existing anymore is difficult.
⚠ Doing regular full loads for analytics applications elminated the need for deletes and verifying out of sync records (CDC mismatch).
⚖ Having that controldataset verifying on growth - shrink expectations can add addtional safety checks in operations.
SAS code examples Initialise monitoring EL:
| Code source | Description |
| --- | Initial Transform. |
| --- | Close validate transform. |
Additional data parsers:
| Code source | Description |
| --- | XML parser goal to split in many XML´s. |

ETL performance - Executing & Optimisations.
Pattern: Break up analytical warehouses in multiple ones.
Breaking up the analytical questions to area´s of involved parties decreases complexity avoiding a big design.
The analytical warehouses for generic support like a SOC (security operations centre) or CMDB (configuration management database) are others outside immediate business flow questions.
Pattern: Build EL process flows conform a structured modular programming.
Breaking up the analytical questions to area´s of involved parties decreases complexity avoiding a big design.
Pattern: Build EL process jobs conform a structured modular programming.
Adding logic for initialisation termination and monitoring in an standardised way can reduce develop time and improves manageability of the processes.
Pattern: EL transformations according limitations & possibilities of the tooling.
Generic tools will use generic coding solutions that will work although they do not need to be a fit in performance or used data model.
With some standards in how to work al lot of overhead in all of the processing can be removed.
Goal removing bottlenecks, decreasing delivery time.
Pattern: Plan a regular full load or verification data quality with source systems.
When the source systems is assumed to have the data as should be, al lot of data quality questions will be removed when that synchronization is controlled and / or validated.

Forgotten history.
Performance & Tuning once upon a time was an important skill. Application systems were designed in every part of the stack to achieve acceptable behaviour.
🚧 A system build without any concept of avoiding bottlenecks will suffer by build in bottlenecks.
🚧 Data - normalized systems.
Data Normalisation once was the standard for operational systems using the relational data model (RDBMS).
Using in memory analytical tools that are at best using denormalised data, the question should be why doing all the effort for that RDBMS operational usage in analytics environmets.
Dependicies other patterns
This page is a pattern on etl performance.
Within the scope of metadata there are more patterns like exchaning information (data) , building private metadata and securing a complete environment.
🔰 Somewhere in a loop of patterns ..
Most logical back reference:
previous.