Contents & topics Data governance
Patterns as operational constructs.
 Information pull request, why is it critical?
Information pull request, why is it critical?There are a lot of questions to answer:
📚 Information data is describing?
⚙ Relationships data elements?
🎭 Who is using data for what proces?
⚖ Inventory information being used ?
🔰 Somewhere in a loop of patterns ..
Most logical back reference: previous.
Contents
| Reference | Topic | Squad |
|---|---|---|
| Intro | Patterns as operational constructs. | 01.01 |
| pull-push | Why Requesting in a pull before doing the delivery in a push. | 02.01 |
| IV III pull | Defining & realising the pull request. | 03.01 |
| I II push | Defining & realising the push delivery. | 04.01 |
| transpose transform | Transposing information and adding derivated elements. | 05.01 |
| Pattern chain | Defining the chain - Transformations. | 06.00 |
| Dependencies other patterns | 06.02 |
Progress
- 2020 week:02
- The Pull Push data process realisation build as new page.
It is a project experience needing to go back to these fundamentals.
- The Pull Push data process realisation build as new page.
Duality service requests
 sdlc: The variability in information types is that low that a transactional approach with relational physical modelling from start to end is workable for a business process.
sdlc: The variability in information types is that low that a transactional approach with relational physical modelling from start to end is workable for a business process. When the process is retrieving analytical information from other parties, see bianl.
bianl: The variability in information types can be that high that relational physical modelling will a problem itself.
Notes:
The delivery of information for further processing is the best in a relational format.In the project with this information structure the source data was not relational. The reason is the variation in requests and the way of how it is collected. Only at the conceptual layer with naming conventions it was possible to define wat can become relational.
Defining all the unique elements resulted in a table with apx 6.000 rows. Postponing the technical and physical relational model to the moment of delivery made the process workable with very little lines of code.

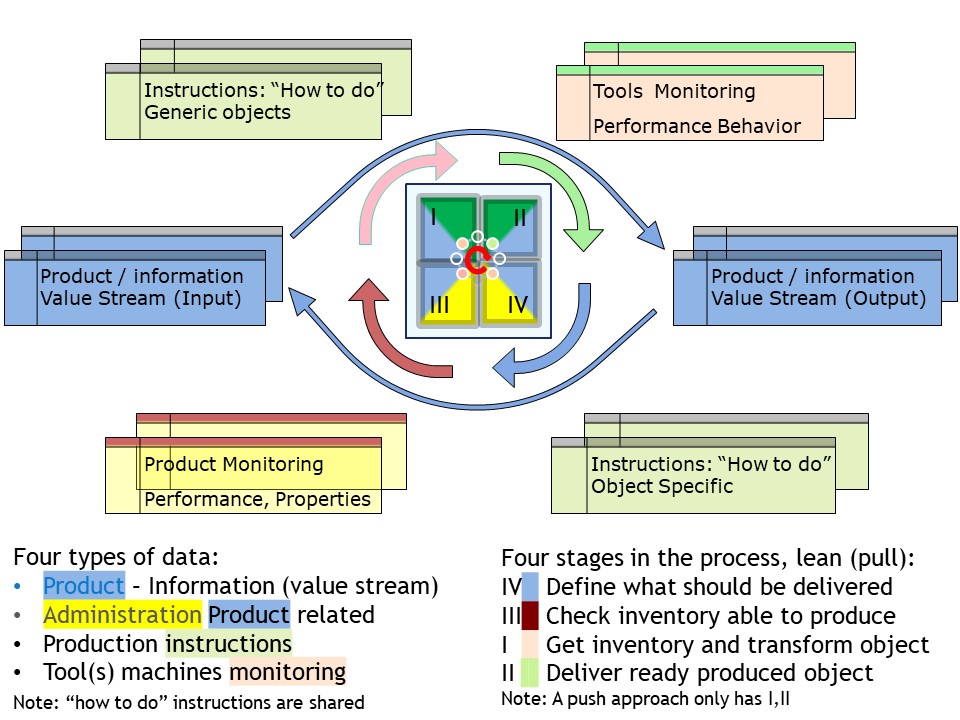
Why Requesting in a pull before doing the delivery in a push.
When the goal for some process has been defined the needed and available information must be inventoried. In a lean - agile mind setting only that information that really matters will be retrieved.
There is a cycle starting from the question what is needed up to the delivery.
It is not the least possible set of elements that are included. Some additional artefacts might be included when the effort to include is minimal and the expectation is they are needed sometime in the near future.
The information flow supported by a process cycle.
The push delivery is following the process flow from input to output.The pull request is analysing wanted output and from that define what is need for the input. Both are having functions to support them. Those support functions have strong relationships.
There are functions for monitoring, logging and performance and there are functions that are describing working instructions. Working instructions can be generic on what is to be expected and detailed when the elements artefacts get processed for delivery.
Using only existing well defined relation tables, the question and what elements are really needed gets easily lost. When the request is done with a totally different technical approach request question is the logical starting point.
For example use a single sheet in a spreadsheet having all elements with an unique logical identification and the numerical and/or character values associated with that. This datasheet is a single technical table storing all elements in a vertical way. The output delivery is expected to be several relational tables having many columns with the focus on each element type.
In an elementary figure:

Defining & realising the pull request.
The information gathering, doing the inventory and getting access for delivery is known as the most time consuming activity.
There two stages within this.
IV 🎭 The communication an organisation on using needed information that should become available.
III ⚙ The technical coding and running retrieving the information.
Data is processed by logic (code) the create new data. When there is a template defined it can be later get filled by recipients.
Those filled templates is the new information to be processed. In the example of a single sheet there will be many sheets to process. In a figure:
When there as a database connection with relational tables as input the usual hard work is decomposing all the information and composing it in some new model. The believe is the new composed model will fit for all requests in the future.
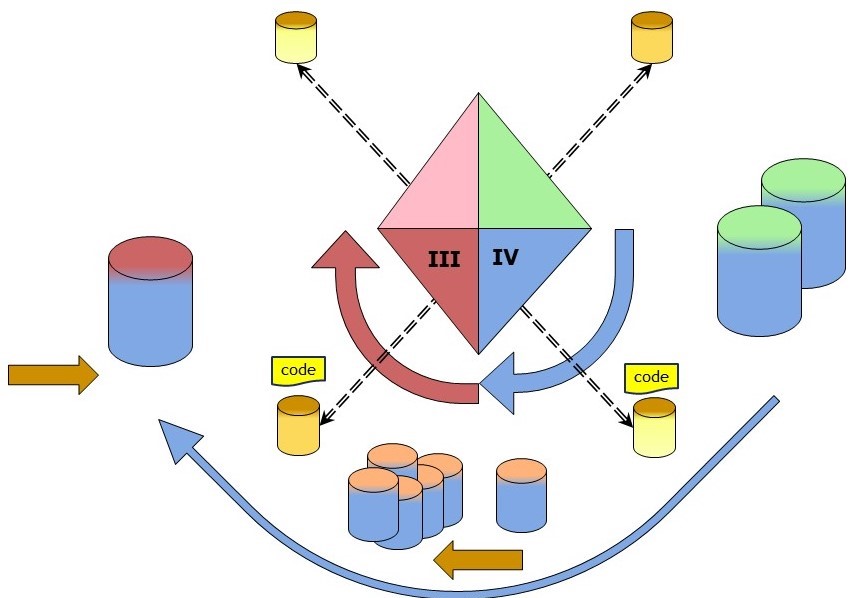
Determining, defining, documenting, template for the needed information. (IV)
Defining a template for what information is needed:
- Verify all elements are defined in a private metadata repository
- Add new elements to the private metadata repository
- Monitor, log events, maintenance of templates
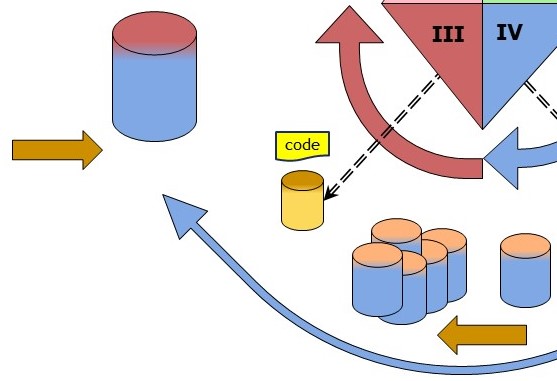
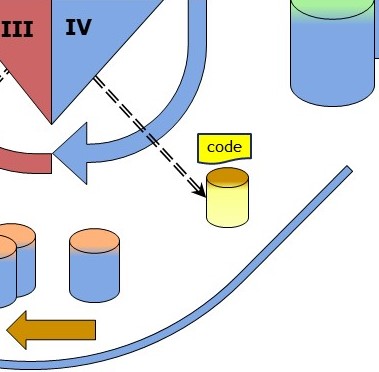
Processing the incoming containers having information. (III)
Processing all filled templates into a working staging store implements:
- Verify all elements are conforming the model template.
- Extract identifiers from the filled template. Verify the recipiënts identifiers.
- Replace element values with all identifiers into the working staging store.
- Monitor, log events, adding information to the working staging store.

Defining & realising the push delivery.
The information processing activity is the part of a process line. The goal is with one or more input containers delivering a one or more output result containers. The process may change in time and by progressive insights.
There two stages within this.
I 🎭 For a defined delivery select the elements and information area.
II ⚙ Delivering information in an easy to use format.
Having the data in the operation permanent store and newer ones in the working store, transforming of information can proceed into another defined area for the defined periods. In a figure:
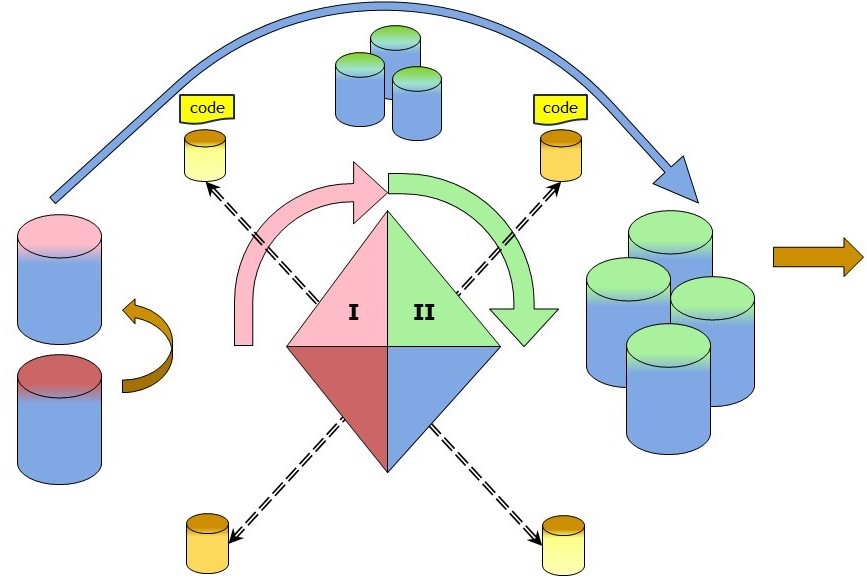
The splitting in segments by periods adds come complexity. It decreases complexity on:
- Correct single segments. Work on smaller parts with controlled replacements.
- Archiving of segments, keeping the environment clean, retention policies.
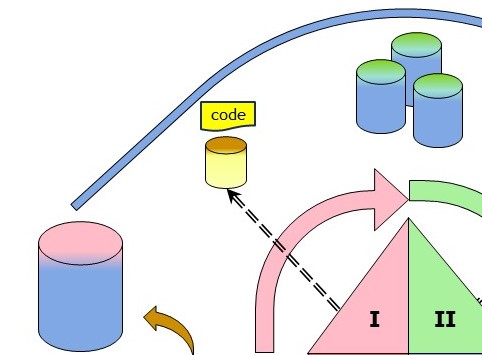
Preparing stored information into more useful representation (I).
Transformation at an intermediate store for selected elements:
- Adjust temporal indicators (dates) when applicable.
- Adjust element values when the version of an element has changed the unit size.
- Connect key values to transformed values, add group and translated historical values.
- Define the destination for tables when elements will transpose into columns.
- keep track on what elements are used marked by origins and date time stamps.
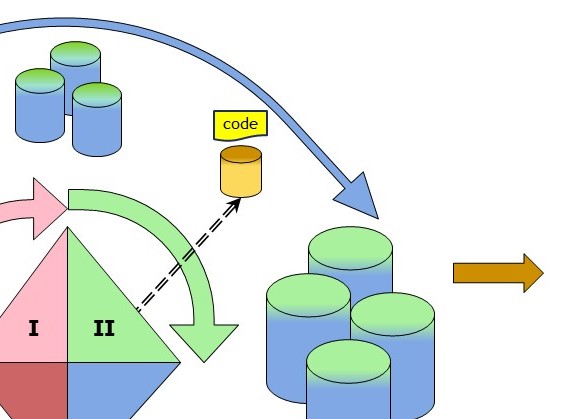
Transforming stored information into useful representation (II).
- Create a derivate private metadata table for each table to deliver, only having valid elements.
- Add to the derivate private metadata table all calculations that should me made on elements when they are columns.
- Create the tables doing a transpose transform in the prepared defined structure.
- Add calculations to the new record order before storing it.
- When some summary values on the new tables are useful create those after having the new tables.
- keep track on what elements are used marked by origins and date time stamps.

Transposing information and adding derivate elements.
Using elements stored with private metadata definitions simplifies the processing in stages IV III and I tremendously. The variability of what elements are valid is not something to bother.
The complexity is in transposing the vertical stored elements into well defined horizontal columns. This process in stage II is the unusual one. This unusual transform needs additional elaboration. This transform doesn't exist in the SQL coding approach. There are no tools supporting this with data lineage.
Solutions:
- The data lineage is solved by using the private metadata (vcd) name space as naming convention for the columns.
- The record column definition is done by defining a grouping (window) from available identifiers.
The grouping window is possible by an using an ordered sorted approach. The performance for running on sorted data storage (1) usually is the best way at realisations when all data will be touched. - Adding calculations is based on a meta data table (calc). Only valid elements of the calculation definition to use. This avoids having empty columns for selected periods when the source elements do not exist and still having he option to use them where they exist.
- The resulting private metadata definition for a table is saved in a table (def).
- Using the private metadata definition for a table that delivery table is created. (2,3,4)
- Aggregated calculations on the new delivery table are created. (5)
In a figure:
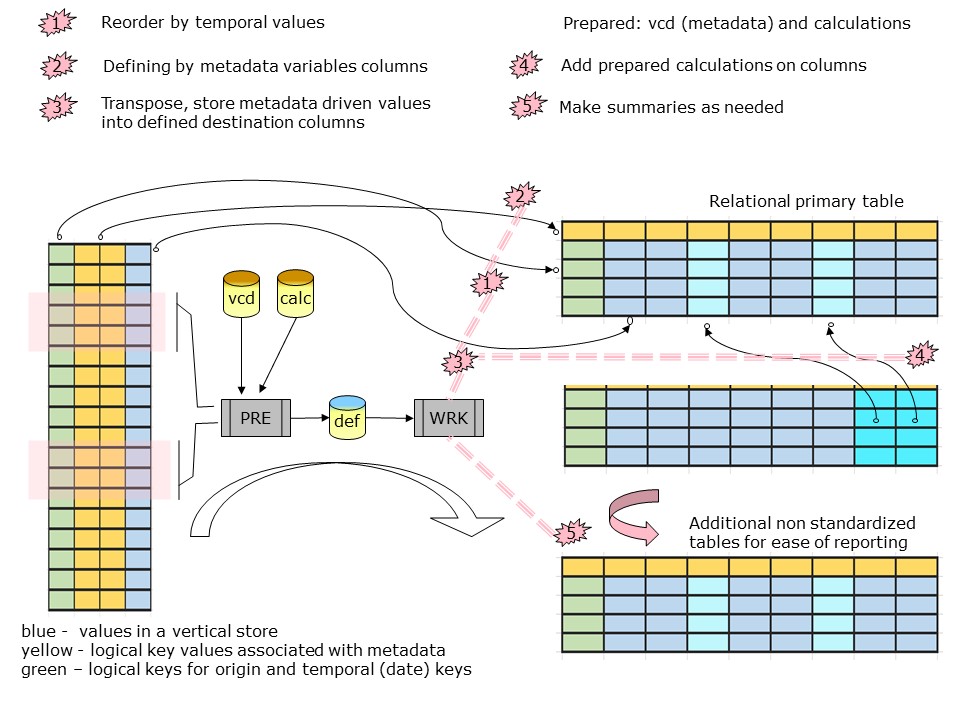
All information in these delivered tables could be not the end situation. For presentation goals some additional steps are needed for other tables and connecting to other tools.
This whole process was successfully implemented using several features of SAS. The code size kept remarkable small in lines of code. Some code is presented for free.
| Source | Description |
|---|---|
| ykwdrnt4 | define template, check elements private metadata, correct. |
| ykwdrnt3 | check delivery with template build up partitioned staging, monitoring activity. |
| ykwdrnt1 | create intermediate selected partitions defining delivery derivates. |
| ykwdrnt2 | Create many tables for the push delivery verify integrity. |

Defining the chain - Transformations.
Pattern: Information pull request push delivery
Four stages in this pattern:IV 🎭 Define what should become available.
III ⚙ Collect deliveries, defined elements, into staging area.
I 🎭 For a defined delivery select the elements with identifiers.
II ⚙ Delivering information in an easy to use format.
Remarks:
- Tools being used can be different in every stage.
- Excel being useful at IV, an SQL DBMS approach in stage II
- An programming environment allowing non conventional transforms in III and I.
- Star schema´s are hidden in the private metadata and key identifiers.
- calculations on columns are easy after an transpose on columns. Using a definition table with metadata elements and their calculations removes the dedicated coding for that.
- a derivate metadata def table to use for what is delivered in relational tables.
Required other Patterns.
💡 Private metadata pattern is used to do most of the logical constructs.💡 Performance consideratations using sorted data partitions (pattern) is used.
Conflicting other Patterns.
⚠ This approach with hidden logical star schema´s is a break with how a star schemas should be implemented using SQL DWH and a relational DBMS as common guidelines.⚠ The transposing of elements is able the create several star schema´s. Elements are the goal for analysesis reporting. Put those in columns, A key identifier or several of them can be the center to review. Usually this freedom is lost by the classic DWH approach thas is focussed on working with a predefined centerpoint.
Dependencies other patterns
This page is a pattern on pulling request information. Within the scope of metadata there are more patterns like exchanging information (data, building private metadata and securing a complete environment.
🔰 Somewhere in a loop of patterns ..
Most logical back reference: previous.
| 👐 | top mid bottom | 👐 |
| 🎭 | index references elucidation metier | 🎭 |