relmg DEVOPS = Value stream, removing constraints
Release mangement, Versions of business logic
Making work of ICT colleagues easier.

Working experiences by some controls. The SIAR cycle is there using the corners 👓, topic cycle in the center.
SIAR:
S Situation
I Initiatives
A Actions
R Realisations
🔰 lost here, than..
devops sdlc.
Progress
- 2020 week:12
- Started with paragraphs copied old main page.
Contents

For the processes the limitations of what is technically available at a moment is important.
Although the technical situation is not important for the concepts of a design, they are defining the options in realisations.
The era authorisation became part of the technical system.
⚙ Early computer processing
In the early day´s of computer processing there was no need for securing resources options. The systeme was operated b operators and no one else did have access.
Delivering what was wanted to get processed on pucnh cards.
This changed when end-users got terminals and OLTP systems were introduced. Some of the activities done by operators moved to end-users. This shift in technology was made in in the 80´s.
The first approaches for securing resources was in doing that in:
- Coding into the business applications. Using user names and the hardwired terminal addresses.
Nothing has changed when this is done these days for web applications. The terminal name similar to an ip address.
- Defining terminals with a name related to a desktop location.
Nothing has changed these days when an ip address has made important in an application or firewall.
- programming (configuring) the middleware validating user input.
Preventing code injection as security mitigation is similar.
- Using some options like user management in a middleware tool like a DBMS.
When an load balancer for remote desktops is used this is similar.
What really new is although from mid 1980:
The system authorization facility (SAF) provides an installation with centralized control over system security processing through a system service called the MVS� router.
The MVS router provides a focal point for all products that provide resource management. The resource management components and RTE ALC type2 call the MVS router as part of security decision-making functions in their processing, such as access control checking and authorization-related checking.
These functions are called �control points�. SAF supports the use of common control points across products and across systems. ...
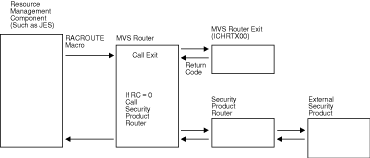 The RACROUTE macro invokes the MVS router. When it is invoked, the MVS router first calls an optional installation exit routine and then calls the external security product (such as RACF), if one is active and installed on the system, as shown in the illustration that follows.
The RACROUTE macro invokes the MVS router. When it is invoked, the MVS router first calls an optional installation exit routine and then calls the external security product (such as RACF), if one is active and installed on the system, as shown in the illustration that follows.
In this concept security interfaces and security management got decoupled from doing scripting. The disdavantage is that those interfaces must get implemented in middelware and business applications.
Monitoring logging is not that technical SAF interface. For monitoring and logging writing all events is SMF. SMF is a generic system facility for all kind of RTE ALC type2.
Events as a change in the database by an end-user or some resource usage eg over the last 5 minutes.
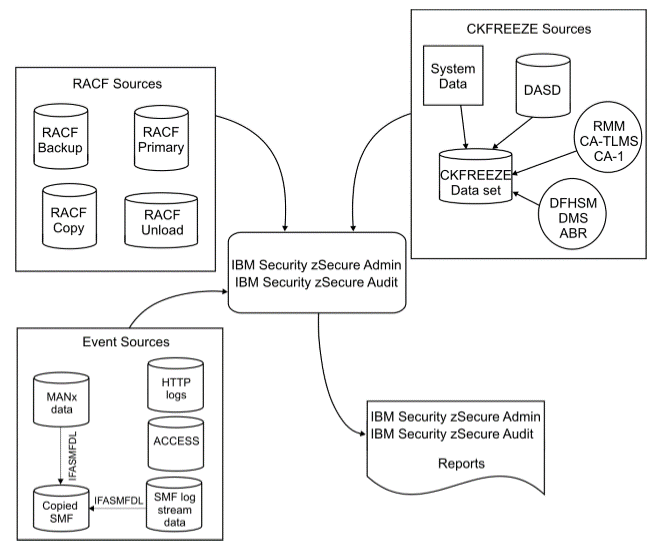
Source: zsec_admaud_racf_gsg.pdf when Racf is the external security product.
Building a secure environment in the release management context using these concepts is far more easy.
Classification of artefact a prerequisite. The most simple implementation is by using naming conventions of the artefacts.

Monitoring, logging, telemetry is a basic information source. Not knowing what is going on, not knowing when something is done wrong,
not able to predict what could happen seeing change in measurements is a business threat.
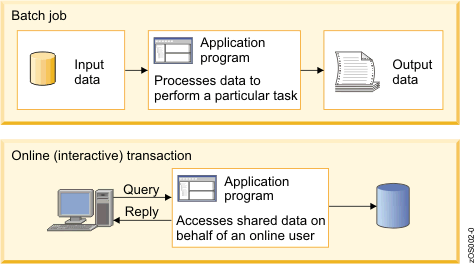
Client Server - distributed processing.
Using a single system (mainframe) is not state of the art. Using distributed systems, client server, web services is.
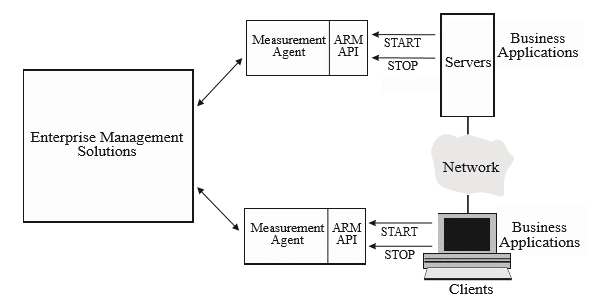 Application response measurement (ARM 1998) , an API jointly developed by an industry partnership, monitors the availability and performance of applications. ARM is an approved standard of The Open Group.
Application response measurement (ARM 1998) , an API jointly developed by an industry partnership, monitors the availability and performance of applications. ARM is an approved standard of The Open Group.
To ensure that requests are performing as expected in a multi-tiered heterogeneous server environment, you must be able to identify requests based on business importance. In addition, you must be able to track the performance of those requests across server and subsystem boundaries, and manage the underlying physical and network resources used to achieve specified performance goals.
You can collect this performance data by using versions of middleware that have been instrumented with the Application Response Measurement (ARM) standard.
Combining ARM calls within your application with an ARM agent, users of your application can answer questions like:
- Is a transaction (and the application) hung, or are transactions failing?
- What is the response time?
- Are service level commitments being met?
- Who uses the application and how many of each transaction are used?
Some new operarting systems.
A not that well known engineer moving from Dec (Digital Equipment Corporation)
Cutler, .., who still comes to his office each day on Microsoft�s sprawling Redmond, Washington, campus, has shaped entire eras:
from his work developing the VMS operating system for Digital Equipment Corporation in the late �70s, his central role in the development of Windows NT - the basis for all major versions of Windows since 1993 - to his more recent experiences in developing the Microsoft Azure cloud operating system and the hypervisor for Xbox One that allows the console to be more than just for gaming.
What he has done is a complete redesign of an operating system. The concepts are there but using open standards is less obvious. LDAP (AD) is one of the best innovations.
What about Unix - linux? It was developped in the 60´s a complete redesign and opens standards for decoupling authorisations is missing or you could say there are too many of those standards.
Security Management Triangle
At project management the following constraint should be well known. Cost (budget), Time, Scope and resluting quality. One (or more) of those is easliy getting lost.
In security there are also several triangles with constraints that are having a balancing act. Those are far more ignored.
- Managing human resources putting them in roles (account keys, groups).
- Functional business management for their business application usage and administration
- Technical solutions (os & middelware) for the technical administration ans realsiation of authorisation interfaces.
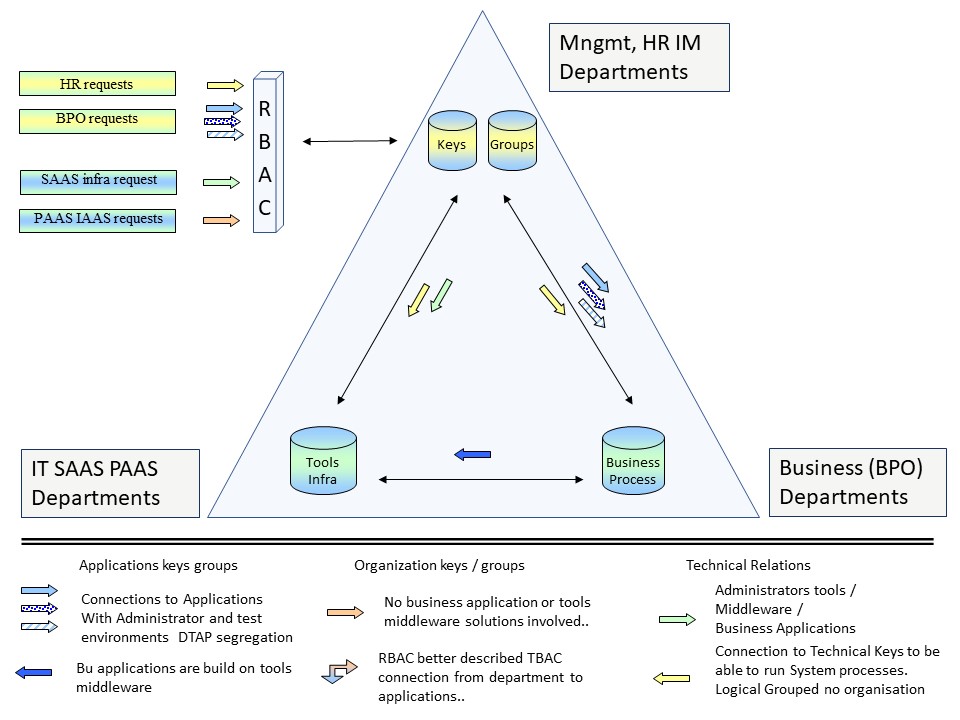
It is very confusing to name middleware software and business logic business data both applications. They are at a very different level of information usage.

It al started when seeing all the manual work, the long time waiting somebody completed his part of work, the same work being repeated over and over again.
That repetition has historical grown because of it was done in several departments not having thoughts on cooperation.
Defining business logical artefacts
When started to do classification for artefacts types. There is:
-
 3GL languages source ➡ compile ➡ executables.
3GL languages source ➡ compile ➡ executables.
This old Cobol C style and java R python or any language using tools like eclipse and git are not different.
Web based OLTP or batch is not different
- Home build tools supporting the development & testing.
- Datasets having some information that are in fact business logic.
-
 Code in an IDE (integrated Development environment) using database storage (IDD).
Code in an IDE (integrated Development environment) using database storage (IDD).
IDMS was the first one. SAS metadata generated code or stored in catalos are conceptual not different.
The problem is copying the original in the not direct accessible storage along with the resulting generated code.
Generating code in production is changing code, not validated code.
- The level in education using systems by humans.
- Business Software product documentation and test reports.
- Middleware tools and more without business logic without business information.
- Hardware components that are the infrastrure for a platform to build.
- Schedule information, flow definitions.
- (not limited to this).
Not all artefacts are easily eligible to put into a generic releasement tool.
You can put documents in it and test reports and offloaded database records. The check for any difference in source code line will not work.
😉 Doing this defining of SDLC lines of artefacts regular. This is how a release train gets done.
When implementing JST, supporting SAS and more having done this over and over again.
Defining types of processess
- Personal interactive processes running at personal accounts as OLTP using an DBMS (IDMS).
- Personal interactive processes running at personal accounts (TSO).
- Batch processes started from a personal account (JES2).
- Batch processes started from a service (non personal) account (JES2) mostly it is regular scheduling but other serverice jobs (offload) are possible.
- Services started by the system. Middleware services like a DBMS, enterpise service bus (ftp), restfull webservice (soap).
- Services started by the system. Resource management for IO CPu memory, Logging monitoring and ohter basic housekeeping services.
There are three naming conventions needed for the needed classifications to group them for managing the security..
- User accounts having those can have a lot of attributes associated with them.
- Batch processes by names (single system), used account associated with business functional management owners.
- Services started by the system either as technical only one or as visible business functionality.
Often naming conventions are already in place. Changing what is in use is more difficult when it is a new green field. Existing naming conventions are sufficient when the needed grouping is easily done.
😉 Doing this enables the SDLC lines of artefacts. This is how a release train gets done.
Without defined logical containers for information at rest (storage locations) and information in transit (being processed) neither the end situation or the development process will be safe.
💣 Stating that every "application" should have his onw dedicate (virtual) machine just is moving the problem wiht the same question in the number of machines.
Take a look in the number of servers that are in use. I have seen numbers of 2.000 10.000 and up with the claim that a very limited number of persons (less ten 10) are needed for that. Ask the question for what?
Defining administrator roles
The practical cases:
- Use different (multiple) accounts for normal usage and admin roles by te same person.
⚠ This conflict with ease of HR roles assuming a person has only one a role and by that should have not more than one account.
- For traceablity actions for every account should be traceable to a single person. Usage of shared group accounts to be avoided when possible.
⚠ This conflicts with ease of use in defining connections between machines running another "applcation".
- Technical solutions (os & middelware) are needing an isolated location to store the software (installation account).
⚠ The conflict is this account cannot be personal. It must be a shared one.
- Technical solutions (os & middelware) are needing multiple accounts (isolation).
⚠ These can not bound to a person. Used tools the same as bound to persons.
😱 I never got these conflicts understood by the responsible accountable ones.

Naming conventions are realisations of grouping of objects, resources, artefacts with the goal to be able to manage those.
It is master data management, MDM, in an localised configuration organisation context. Naming conventions are the fundament for information processing.
naming conventions (transit) for user accounts
🎭
basic user account User account on a mainframe (TSO) did have the limitations of maximum 7 characters. The first character not a number.
A seen convention is to use the first 5 characters extracted from the persons name and 2 digits to make the account unique. The 8-th character is reserved for starting a sub process.
⚙ Windows is using a complex sid schema that is translated for human readliblity
⚙ Unix, Linux did also have that kind of restrictions (maximum length 8), some have changed. Unix is using an id-number for users and gid-number for groups that are translated for human readability.
⚙ Websites do not have those kind of limitations. An email-address or telephone number are other options for identification (not authentication) of the user with a naming convention for his personal account.
🎭
high privileged, admin accounts These are also user accounts with some special authorisations for a dedicated task. One type of usage is the promotion - roll back of business logic artefacts in the release train.
An alternative when admin accounts are not getting passed by IAM (Identity Access Management) departments is to use one person activities not be in conflict with the segregations of duties requirement.
⚖ 😉 By restricted admin accounts, security is easy implemented compliant.
naming conventions (transit) for batch processes
🎭
An adhoc batch process is free when associated with a personal account.
🎭 Running a
defined business application, than following a naming convention for those recognisable for all environments having relases for it is the wasy to go.
The limit in the mainframe era was set by having a mximum of 8 characters.
⚙ An used naming convention done wiht JST is:
- The first 2 characters (1-2) used for the business lines and business applications types.
- The next 4 characters (3-6) a number representing the program (units of hundreds) and modules.
- The next characters (7) a letter that is the DTAP environment indicator.
- The last character (8) free to make duplicates unique.
⚖ 😉 By naming convention the security is easy implemented strict compliant.
⚙ An used naming convention done with JST is:
- Mainframe: "surrogat" class for a restricted services account.
A surrogate user is a user who has been authorized to submit jobs on behalf of another user (the execution user) without specifying the execution user´s password. Jobs submitted by a surrogate user run with the identity of the execution user.
- Windows: "runas, services user" The local system account for services is the default that is possible changed to a restricted service account.
- Unix linux: "su, sudo" switch to a restricted service account (not root).
Sudo (su "do") allows a system administrator to delegate authority to give certain users (or groups of users) the ability to run some (or all) commands as root or another user while providing an audit trail of the commands and their arguments.
⚖ 😉 By restricted service accounts, security is easy implemented strict compliant.
💣 The issue with restricted service accounts is that: defining maintaining is an organisation responsibility.
naming conventions (transit) for system services
A system service is running services, What else would make sense to use service accounts for those.
The DBMS wiht JST got solved to use the surrogat class to switch the user context into the one of a DTAP segregated service accounts.
Supporting SAS and other recent tools this never went into normal accepted at realisations.
⚖ 😉 By restricted service accounts, security is easy implemented strict compliant.
💣 The issue with restricted service accounts is that: defining maintaining is an organisation responsibility.
Not solved by service providers and not by software manufacturers. That wrong assumption is too often made. 😱
naming conventions (at rest) business logic
Just define a technical ownership by a dedicated admin account when access rights are controlled by that dedicated admin account.
With this building block all what is needed for a release train bussiness logic is complete
⚖ 😉 By restricted admin accounts, security is easy implemented compliant.
naming conventions (at rest) business data
Just define a technical ownership by a dedicated admin account when access rights are controlled by that dedicated admin account.
With this building block all what is needed for doing any run on isolated businessdata is complete
⚖ 😉 By restricted admin accounts, security is easy implemented compliant.
naming conventions (at rest) middelware tools
Just define a technical ownership by a dedicated admin account when access rights are controlled by that dedicated admin account.
With this building block all what is needed for installing and running middelware -tools- is complete
⚖ 😉 By restricted admin accounts, security is easy implemented compliant.
😱 I never got understood by the responsible accountable ones why all segregations using dedicated accounts is mandatory by regulations.

The are no real technical issue with the challenge of release management.
There seems to be a disordered sitatuion in the complicated questions on how to implement an accaptable workable solution.
The security model of the intended procution environment is a pre-requisite.
A logical framework for release management (versioning)
A framework for release management used with localisation for the specific situation.
Some generic requirements:
- What version of businness logic is in use P and what versions were in use Z .
- Approvement with a document: What version went to be used A -> P
- Approvement with a document: What went to user-acception T -> A
- The DTAP life cycle wiht an emergency fix and optional parallel development.
Components at rest in a figure:
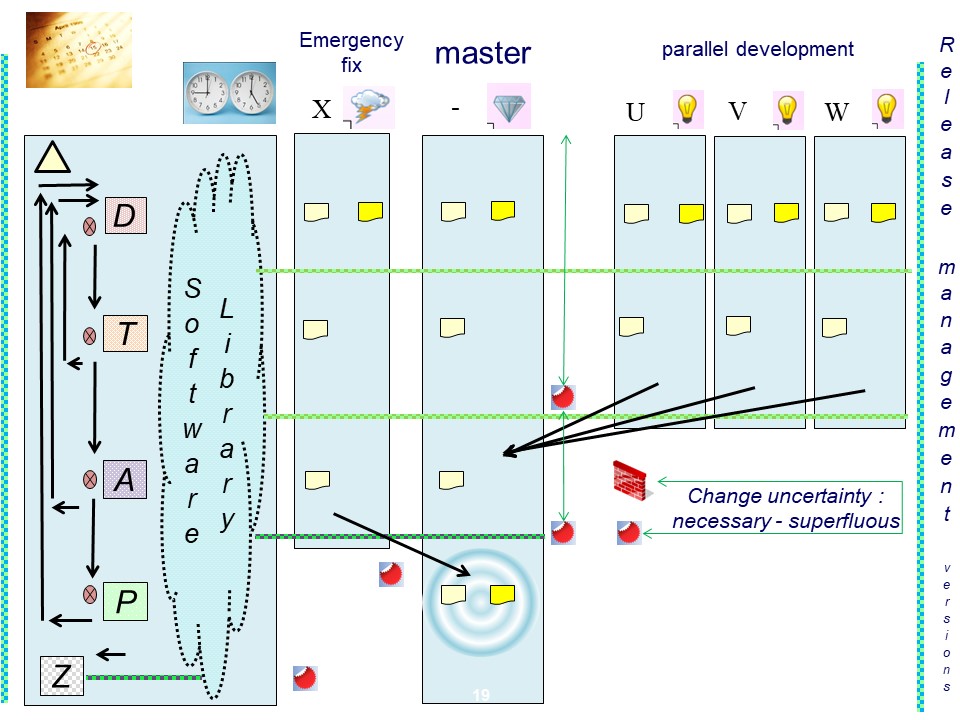
The Develop and Test (integration / system), as similar as possible conform the intended production situation.
💡 Any authorisation model (security) made effective at
T conform P.
The System Development Life Cycle using compinents.
A framework for process pipe lines with localisation for the specific situation.
Some generic requirements:
- What process pipe line is intended at P operational requirements.
- How is the logic for artefacts connected, alc type 2 and type 3 intermixed.
- What is the data preparation (input) and data delivery(output)
- Process monitoring (technical), monitoring of results (logical values).
- Multiple release trains being involved. The D different from multiple TAP lines.
Components at transit in a figure:
The Develop and Test (integration / system), as similar as possible conform the intended production situation.
💡 Any process steps made exactly similar (no changes) at
T conform P.
Questions on how to make the development life cycle lean.
💡 Proposed steps in responding, removing constraints:
- Coding guidelines. Modular, Object oriented, normalized.
- Minimizing interactions with other components. Avoiding possible loop-backs causing an instable chaotic system.
- Naming guidelines. Grouping classification of artefacts ordered in way minimizing interactions at defining releases.
- Using a technical environment as close to the intended target environment. When the target environment is server based, work server based.
Moving artefacts to an other system (pc) is waste and adding unnecessary complexity putting work on integration on the last moment (muda mura muri).>
- Have a plan what to do first and what is to solve later.
Not always unhappy by what is going on

this topic ends here. back to devops sdlc
👓 🔰
Implementing processes.
Guidelines releasemanagment.
Guidelines eg iec/iso 27002, Relese management

12.5.1 Installation of software on operational systems


Those guidelines, mentioned in regulations, are clear. The intention is to know which software version was used on a moment in time in the ⚠ production ❗ environment.
Guidelines Adminsitrator roles
Systems services are processes classified as "high privileged", the security should set with the principle of least privileges ❗
Adminsitrator roles are processes classified as "high privileged", the security should set with the principle of least privileges ❗.
The provider shall design and pre-configure the product according to the least privilege principle, whereby administrative rights are only used when absolutely necessary, sessions are technically separated and all accounts will be manageable.
(enisa Indispensable baseline security requirements for the procurement of secure ICT products and services 2016 )
Lost in the release management triangle.
The project triangle at Sofware Development life Cycles
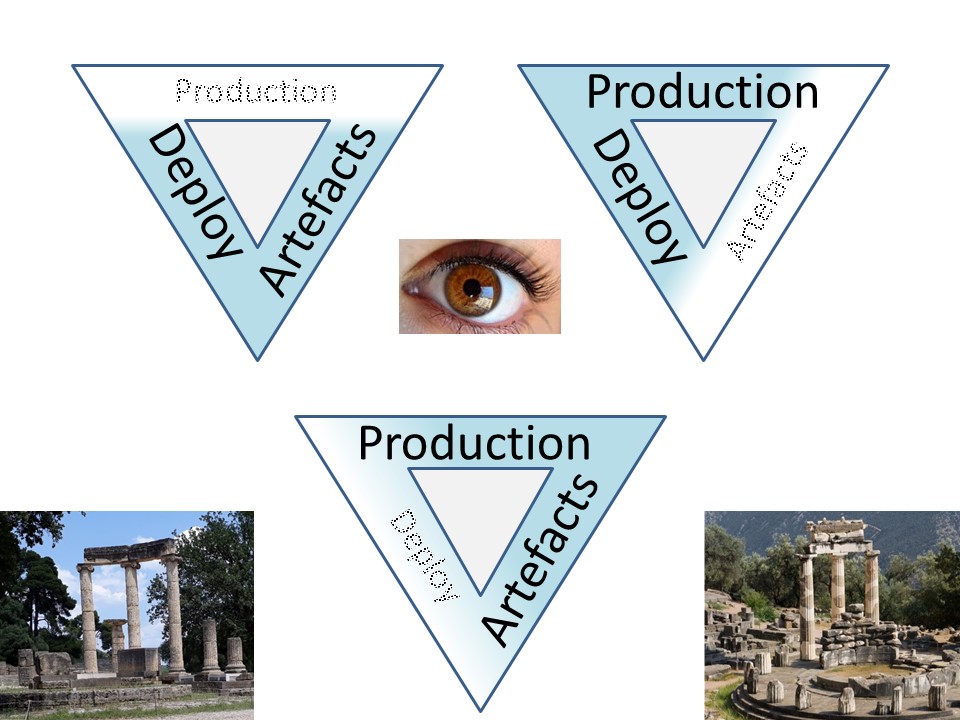
Wanting artefacts deployed, ⬅
💣 forgot the goal at production with the artefacts quality and their impact.
Wanting deployed into production, ⬅
💣 forgetting to have selected verified well functional artefacts.
Wanting at production artefacts, ⬅
💣 forgetting deployment, lifecycle.
Missing the goal of a Sofware Development life Cycles
Words are often not covering the intentions and meaning in the given context. One of the abused ones is "versions".
release management with SAS artifacts is confusing when not knowing how every artifact is behaving. Problematic is that every approach is happening.
Code can be interpreter like, that is there is no source location as the runnable code is the source code.
be generated from a database metadata (5-gl), that implies there is a source database, not source code. Only export/import to containererd objects to promote is doable.
Missing the goal of what artefacts to put in a SDLC

Assuming you can put a data mining project into git for versioning, will cause big issues.
A data mining project using real easily grows above many Gb's. Have seen them using 60Gb and more.
The sizing limit with version-tools like git is based on 3-gl languages. Detecting differences is based on a 3-gl, manual source getting compiled, assumption.
Bitbucket from Atlassian repository limit (total of all historical versions) of 1 Gb.

Missing the role of approvements
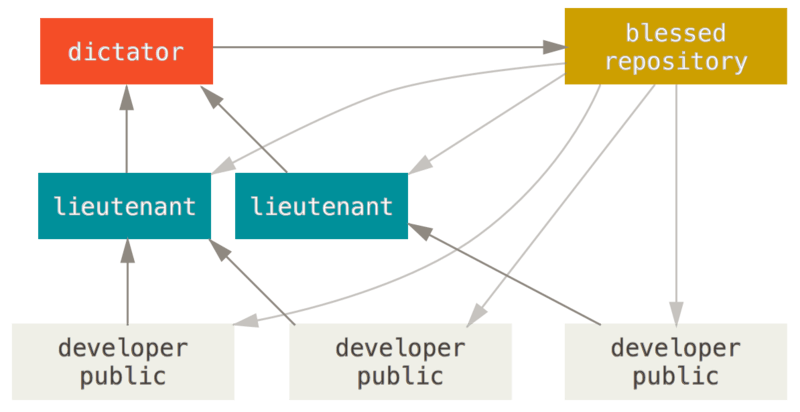
The
git reference. Used with os shell (xcmd) commands.
Using any releasement tool is always requiring an ulitmate approver,
git name: "dictator".
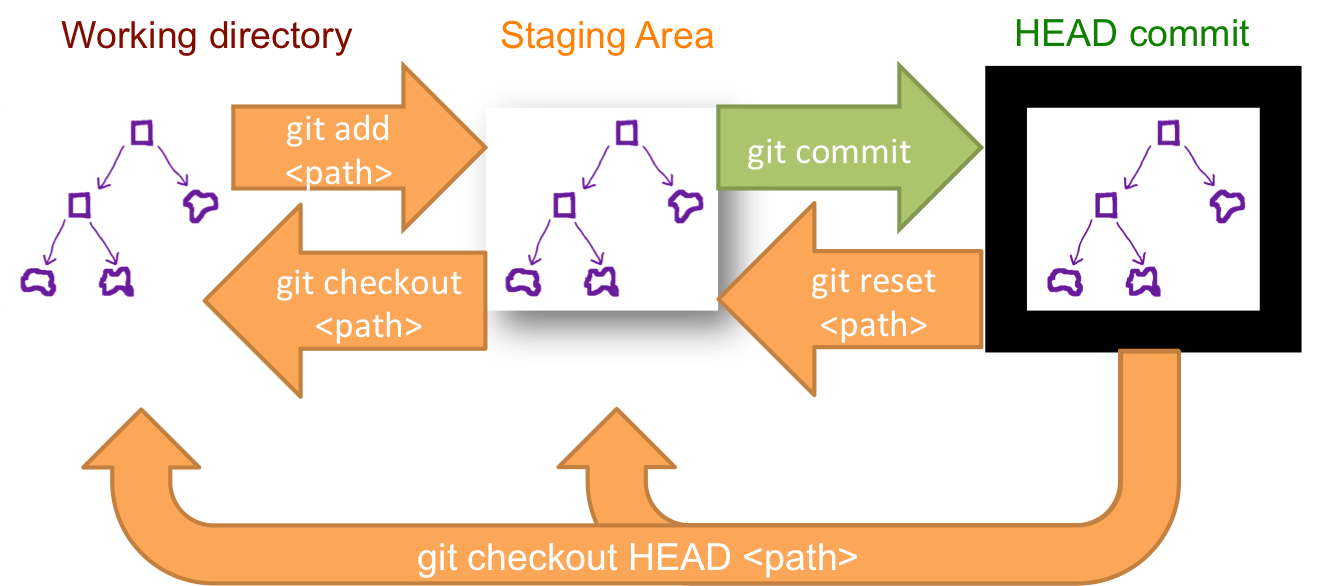
Git uses a local repository that copies locally all files in an os-directory structure. These are the daily working actvities.
A central repository to be connected. All artifacts are verified on incremental changes, blocking when something is out of order.
Recent versioning tooling - old concepts.
The project triangle at Sofware Development life Cycles
Wanting artefacts deployed, ⬅
💣 forgot the goal at production with the artefacts quality (not good).
Wanting deployed into production, ⬅
💣 forgetting to have selected verified well functional artefacts (not cheap).
Wanting at production artefacts, ⬅
💣 forgetting deployment (not fast).
Git Generic usage
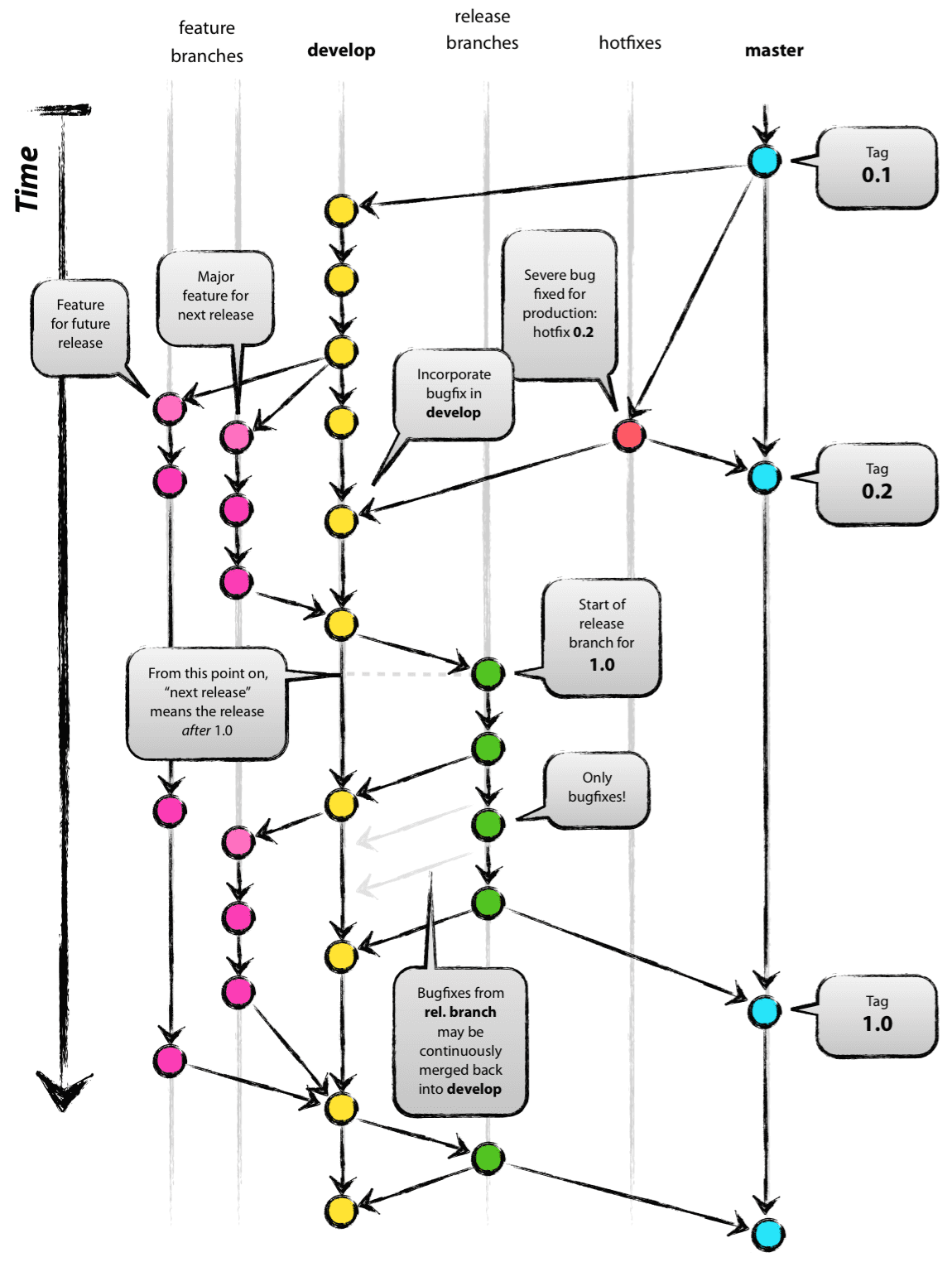 Nvie
Nvie is often referred as a succesfull approach using git.
The picture at the right is Git nvie.
It shows branching lines features (develop), develop (integration), Release barcnches (acceptance), hotfixes , master (P).
It isn´t showing the release management and archiving.
It doesn´t solve anyting on the requirement for versioning for production environments. It doesn´t solve a complete previous version CMDB information.
Focus: developing software (3gl).
Classic life cycle model DTAP
The classic approach is having clear stages for relases with their versions and archiving.
The development lines are the same.
The software library is the central location having all possible future, current, and previous versions of production software.
Classic life cycle using more recentnew tools
CA Endevor SCM
an example of a complete service doing release management.
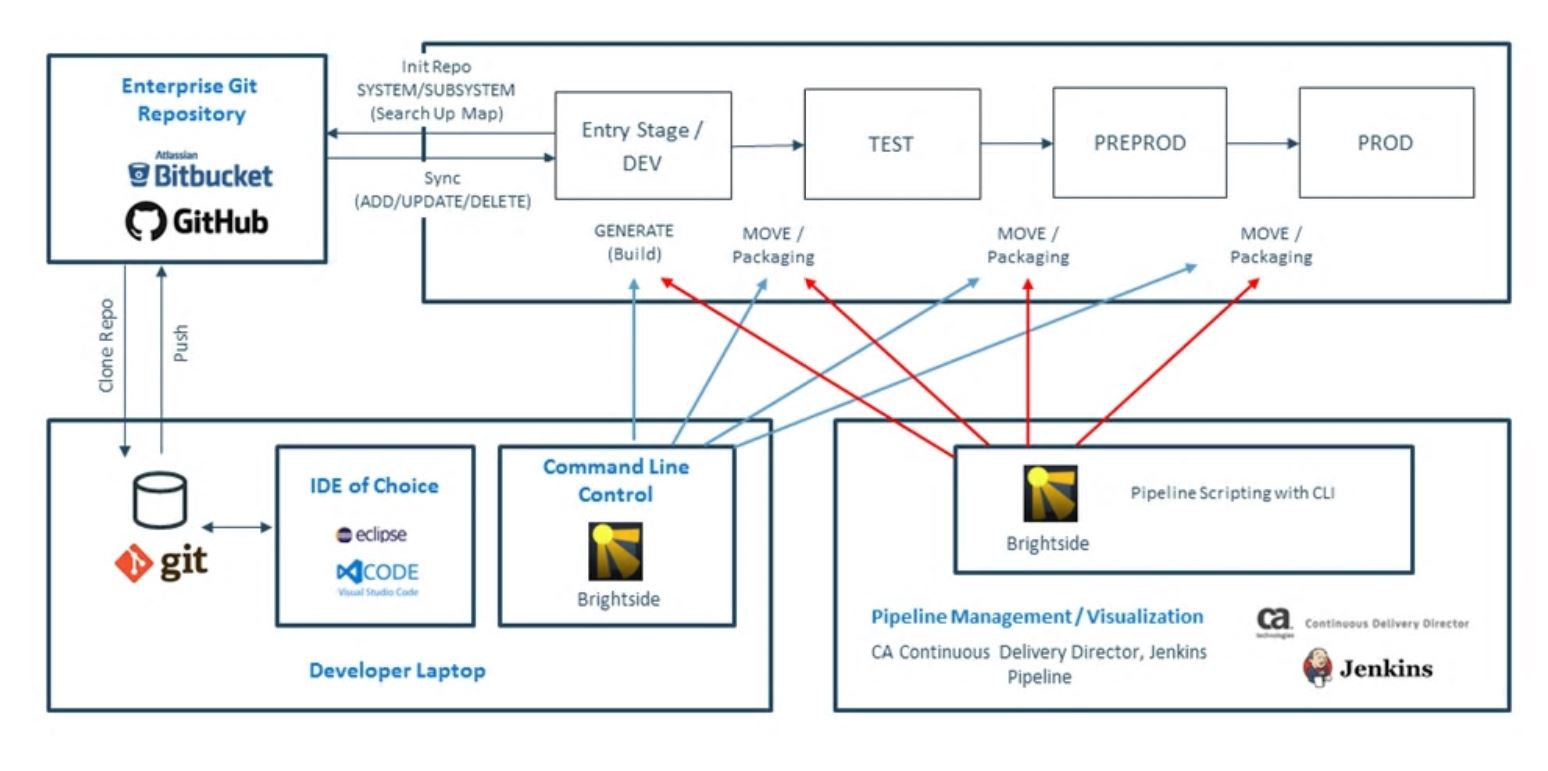
Note the flow by lines of the master, parallel development, an emergency fix.
Nothing has really changed. There is a heavily focus on getting some tool. Not seeing the questions what business problems the tool should solve.
The focus on the goal to achieve, release management, is missing.
ALC model-2
⚙ 🎭 SAS Usage ALC type 2
In the basic approach, analysts are needing data, the code they build should run predictable repeatable.
The support is for interactive and operational batch similar, solving the same issues. Accpetable runtime performance is important considering choices.
The following questions solved and implemented:
- Avoiding using the system data but instead of that using an exterenal modifiable one that defaults tot the system date.
💰 Goal: enable time travelling, jobs using business logic and business data
Methods:
- Changing autoexec.sas config.sas at the best most central place, "sasapp servers", files hierarchy.
- Supplying SAS macro-variables and macro-s, having determined the most common secondary dates and intervals by periods.
- Defining user defined calender functionality so that SAS "working days" are according the business "working days".
- Removing all hard coded physical names for datasets artifact type: business data - information.
💰 Goal: enable release management doing all kind of tests, enabling umchanged runnable artifacts for business logic.
Methods:
- Changing autoexec.sas config.sas at the best most central place, "sasapp server", files hierarchy.
- Using SAS macro definitions for variable parts in the physical name definions. Allowing a variable part for using parallel testing.
- Defining and maintaining the SAS metadata objects associated with business data.
These associations being an input for code generation (ETL-ELT) DI-studio having data lineage support.
- Adding services (xcmd) for making a backup or doing a restore. This being applicable for business data -information.
- Defining a strategy for release management and versioning for artifacts of type business logic. Avoiding hard ooded physical locations within the business logic.
💰 Goal: enable release managment, defining the versioning and releasing versions of software.
Methods:
- changing autoexec.sas config.sas at the best most central place, "sasapp server", files hierarchy.
- Using concatenation for runnable code with filename and libname definitions with the appropiate SAS options settings.
⚠ The supplier promoted file structure "sasapp" is not a solution for all guidelines : developping testing & release management. See #smta global mandatory policies.
- Defining and maintaining the SAS metadata objects associated with business logic.
These associations being an input for code generation (ETL-ELT) DI-studio having data lineage support.
-
With all the SAS business logic type artifacts defining for each of them the best strategy for the runnable part.
 For the real orginal source, no matter the type of that source (4 gl, 5 gl) how to get it along with the runnable one.
For the real orginal source, no matter the type of that source (4 gl, 5 gl) how to get it along with the runnable one.
- Having the business logical artifacts well defined, than align them with the proces: release management.
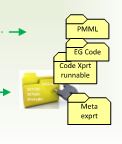
⚙ ⚖ Concatenation, metadata packaging, post deployment
With the surprising big variation in artefacts, every type is possible handled different.
Every artefact type having his own technical solution to implement in achieving release management.
💣 Concatenation is very difficult for the ones not used to cooperate but wanting to have all on a personal location.
⚠ SAS is using "Applications" without the mandatory logic and data segregation in their "Server configuration"
A limited list of artefact handling:
| Artefact description | release approach |
| base code | Embedded Eguide. Requiring to store in an external source repository. |
| base code | Concatenation is the most appropriate approach. |
| macro function | Interactive compiled, same approach as base SAS code. |
| formats | Interactive compiled, same approach as base SAS code. |
| compiled function | Interactive compiled, same approach as base SAS code. |
| SCL | SAS catalogs using concatenation. |
| user-calendar | base sas code creating datasets. |
| Data Integration | Metadata, package & unpack sas code. |
| Miner project | OS:directories, metadata references. |
| Miner metaobject | Metadata result package & unpack into metadata. |
| LSF jobs (repo) | Metadata. Redefine repositories for target SAS code once |
| LSF jobs (flows) | Metadata &and LSF DBMS. Metadata package & unpack into LSF. |
ALC model-3
⚙ 🎭 SAS Usage ALC type 3
What is done for mdl2 being extended to what the Application Life Cycle, Analytics Life Cycle, is needing.
The support is for interactive and operational batch similar, solving the same issues.
The following questions solved and implemented:
- Adding the "eStructured Programming" into the development and operational lines of ALC model3.
💰 Goal: reliable predictable repeatable processing of the software components got split up fucntionality.
Methods:
- Adding input validation job (SAS eguide) after retrieving data and an ouput validation before delivery in the proces flow (LSF).
- Isolating the data retrieval (SAS DI) to a dedicated stage. Optimized SAS DI code for getting acceptable best performance.
- Isolating the ML internal data preparation (SAS EGuide) and scoring stages (SAS Miner). Adding score monitoring and archiving (SAS DI).
- Connecting all artifacts, SAS and others, in the DTAP setting into release management creating the version definitions at production deployment.
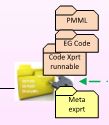
- Supporting other kinds of artifacts, not existing in ALC model2. Allowing parallel development as required by dependicies in teams and actvities.
💰 Goal: enabling ML (Machine Learning) tools.
Methods:
- Support: moving maintaining SAS metadata miner objects. Support: archiving & restoring miner projects by zipping unzipping them in operating system directory structures (xcmd). Includes all training validation test data.
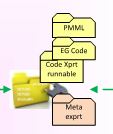
- Splitting the SAS metadata folder strcuture to the intended proces flow steps so the disconnection by teams in step-flow responsabilities is clear.
- A clear step-flow segregation, connecting that to the release management, doing export-import using SAS objectframework tools.
⚙ ⚖ Big variation in SAS artifact types
The variaton in artifacts is surprising big, every type being used to manage in release management.
Every artifact type having his own technical solution to implement in achieving release management.
A list (limited) of artifacts:
| Artifact description | source location | config | runnable |
| base code | Embedded Eguide | export | OS: <name>.sas |
| base code | -na- | -na- | OS: <name>.sas |
| macro function | -na- | macro-search | OS: <name>.sas |
| formats | OS: <name>.sas | format-search | OS: <name>.sas7bcat |
| compiled function | OS: <name>.sas | fcmp-search | OS: <name>.sas7bitm |
| SCL | SAS catalog | compile scl | OS: <name>.sas7bcat |
| user-calendar | OS: <name>.sas | calendar-set | OS: <name>.sas7bdat |
| Data Integration | Metadata | compile generate | OS: <name>.sas7bdat |
| Data Integration | Metadata | export-import | Metadata |
| Miner project | OS:directories | -na- | Metadata |
| Miner metaobject | Metadata | -na- | OS: <name>.sas |
| LSF jobs (repo) | Metadata | job deploy | OS: <name>.sas |
| LSF jobs (flows) | Metadata | export-import | Metadata |
| LSF jobs (flows) | Metadata | -lsf Manual modify- | LSF repository |
| ... | ... | ... | ... |
⚙ 🎭 Generic ALC type 3 Usage
Before going to work dedicated with the SAS tooling I did the "system programmers" role using a lot of tools.
Still doing a lot of tools when opening up what is behind delivered technology and adjusting that for a better fit.
The support and implementation of JST was a good fundament for seeing the business processes. The good experiences to reuse over and over again.
Evaluating realistions.
Any conclusion from experiences is that no one will be happy wiht any situation.
In the devops sprint goal, releasing artefacts in the end of any sprint is a deadline with frustrations.
CI / CD Continuous Integratation Continous Delivery
CI / CD a goal where the business goal is not mentioned.
What is the idea?
CI and CD are two acronyms that are often mentioned when people talk about modern development practices.
CI is straightforward and stands for continuous integration, a practice that focuses on making preparing a release easier.
But CD can either mean continuous delivery or continuous deployment, and while those two practices have a lot in common,
they also have a significant difference that can have critical consequences for a business.
Atlassian Sten Pittet
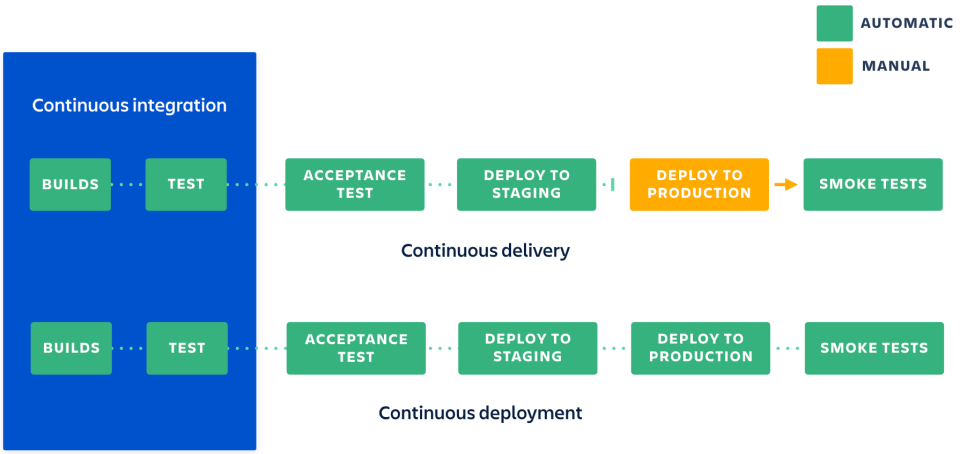 Developers practicing continuous integration merge their changes back to the main branch as often as possible.
The developer´s changes are validated by creating a build and running automated tests against the build. By doing so,
you avoid the integration hell that usually happens when people wait for release day to merge their changes into the release branch.
Developers practicing continuous integration merge their changes back to the main branch as often as possible.
The developer´s changes are validated by creating a build and running automated tests against the build. By doing so,
you avoid the integration hell that usually happens when people wait for release day to merge their changes into the release branch.
Continuous integration puts a great emphasis on testing automation to check that the application is not broken whenever new commits are integrated into the main branch.
Continuous delivery is an extension of continuous integration to make sure that you can release new changes to your customers quickly in a sustainable way.
This means that on top of having automated your testing, you also have automated your release process and you can deploy your application at any point of time by clicking on a button.
Why is the business not involved in acceptance and should wait to see it when has deployed into production? Many business applications have a release date for business reasons.
Just adding some products in a shop should not done by changing logic but by changing business data.
Release mangement is a frustrating topic
Release management (at rest), process pipe lines (in transit), is suffering from just focussing on two of the three important aspects.
⚠ Versioning, deploing releases, should be fast good and cheap, choose two.
⚠ Managing processes (production), should be fast good and cheap, choose two.
⚠ Artefacts servicing business, should be fast good and cheap, choose two.
⚠ managing component at rest (software versions), managing process pipe lines (in transit), servicing customers should be fast good and cheap, choose two.
Working experiences by some controls. The SIAR cycle is there using the corners 👓, topic cycle in the center.
SIAR:
S Situation
I Initiatives
A Actions
R Realisations
🔰 lost here, than..
devops sdlc.