rslt OPS = Value stream, removing constraints
Data modelling, process scheduling.
Defining work of users & colleagues easier.
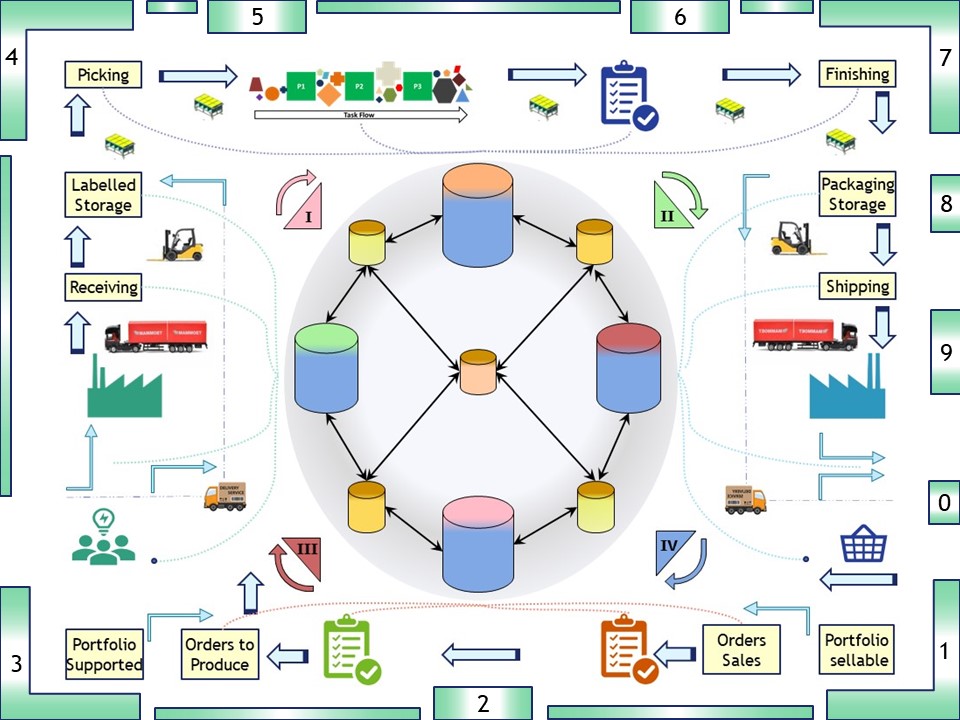
Looking and analyzing what the colleagues are doing, improvements and corrections getting planned (PDCA).
SIAR
S Situation
I Initiatives
A Actions
R Realisations
🔰 lost here, than..
devops sdlc.
Progress
- 2020 week:12
- Control line filled.
- Filled with the sprints moments done at some projects over all years.
- The realisation details as counterpart of this page: finised.
- 2020 week:10
There are four story lines,
- The first dwh for IT operatios Analytics.
- Scoring using ALC type3, connected to a dwh and operational lines.
- Scoring using ALC type3, segregations of datamarts scoremarts conform release trains.
- Information model for high varity. Not a classic dwh, delivering several data flows in a star model.
- 2020 week:12
- The SDLC floor filled with four sub topics.
- Added image map in the control image loops through all control pages.
- Technical detail pages are in the corners.
Contents
| Reference | Topic | Squad |
| Intro | Defining work of users & colleagues easier. | 01.01 |
| Soar CSI | Analyzing Computer System Information. | 02.01 |
| Big data | Big data low variability. | 03.01 |
| ER-star ALC3 | The star ER-model - ALC type3. | 04.01 |
| High-variability | High variability but not that big. | 05.01 |
| Results evaluate | Evaluating results - impact value. | 06.00 |
| | Words of thank to my former colleagues | 06.02 |

The department syssup (system support) was my landing zone. The first usage wiht SAS was analsysing the system (mainframe).
The concepts are still the same. Some task got seperated.
Used terminology events intervals system-source
- System-Source Events An event having a detailed type descriptions and depencicies on other events. The moment measured by time is important.
- System-Source interval A measurement on a technical resourcetype, detailed type and description, over a defined period. The period by starting and ending moment in time is important.
- System-Source Data The (or some of many) dataset where the system is dropping the information for events and/or intervals.
- PDB "Performance Data Base" a collection of the System-Source Data (eg using SMF) having all details for eg the last week.
The word PDB is used in the MXG (SAS code) product with SMF records.
- SDDB "Summary Details Data Base" For reporting aanlsyes on longer periods not keeping all measured details.
Doing this kind of processing is doing analytics. Log management, Siem (Security Information & Event Monitoring) more advanced is SOAPA 👓.
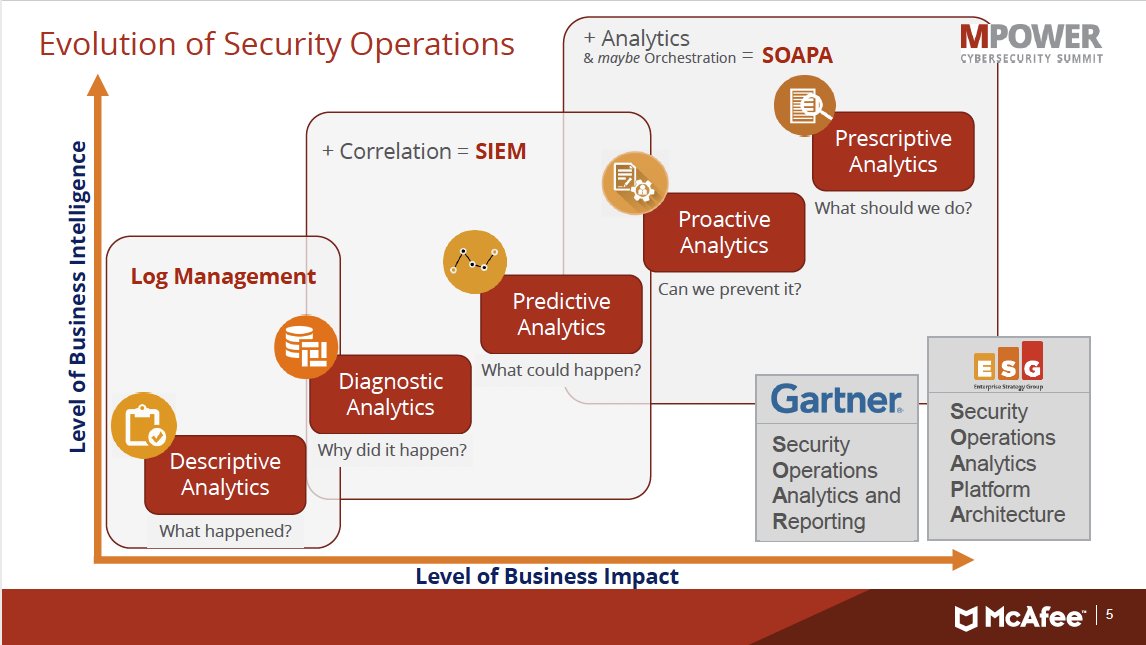 Once a SIEM is in place, organizations need to build a plan that focuses on particular risks or challenges.
Depending on the type of organization, the focus could be on breaches, compliance, or denial of service.
Without a focus, analysts won�t be able to handle all the information that�s being thrown at them by the SIEM.
Once a SIEM is in place, organizations need to build a plan that focuses on particular risks or challenges.
Depending on the type of organization, the focus could be on breaches, compliance, or denial of service.
Without a focus, analysts won�t be able to handle all the information that�s being thrown at them by the SIEM.
SAS was in the lead in those years wiht this. They lost this market, a lot of other tools are in use for this. The most well known now is Splunk.
System Analytics mainframe era, SAS MXG
The situation was:
- Using an expensive computer system.
- change from more batch oriented use into to more interactive usage.
- Lack in knowing of who is consuming the most system resources and when new hardware will be needed. The best guess was by interactive monitoring tools.
- Not able to trace, monitor every type of system usage.
🎭 PDB Performance DataBase getting filled
- Not all subsystems are delivering. New SMF types like IDMS to add.
- SYS-.MAN- datasets: the location where the system is dropping information.
the switch /offload is a nice hook to add SMF processing.
- Running SAS using MXG is an easy way to process SMF needing some configurations.
Goal set: Collect SMF adding on a weekly dataset, archiving weekly versions.
😉 ✅ The implementation went up and data analsyses could get started.
A lot is prepared in MXG for generic life cycle events. The batch jobs are getting completed using spool logic. This logic is for other sybsystems not available.
🎭 SDDB Summary Details DataBase getting filled.
- Spatial summary classes, peak hours worink hours holidays.
- application classes and with departmental cost acccouting.
- Interval peak low distributions.
Goal set: Long term spatial analyses and application cost reporting.
🤔 ✅ Choosing those classifications was an interactive process.
🎭 Adding other subsystems ACF2 RACF security information.
- Simple reports and analyses on these kind of data.
- Relating information managed by security tools, because having user classifications, to resource usage and events.
Goal set: Getting more complete holistic insight on what is going on in the system.
😉 ✅ This works nice in the beginning, a fundamental problem popped up.
The security backup information, password changes (all readable), the most sensitive parts is stored in the same kind of records as system monitoring and system logging.
😱 ❓ Disconnecting the use information managed by security operations from the rest of ICT.
The question who is causing problems in a system got troublesome when cooperation is missing.
🎭 Adding another information type describing all the hardware it would be noted now as a part of the CMDB.
The increased number of hardware got administrated in a new bought software tool. Internal cost administration was asked to connect.
- Defining a new system record source of information.
- Relating that information managed by security tools having user classification to resource usage and events.
Goal set: Getting a complete holistic insight aside system usage also hardware software costs for the system.
🤔 ✅ The connection was made and cost calculations to hardware items added.
😱 ❌ Although information &map calculations correct not what was wanted:
- Investment Budget was done with promises of hardware type. Other investments were done. The mismatch not wanted the be reported.
- Detailed cost assignment directly conforming bookkeeping write-down calculations leading to very weird situations.

A lot of support solving technical questions related to performance in operations was done in the early years.
At a time got involved in some chalenging projects in mass data processing.
Mass data, daily flows, peak deadlines every 3 months
The situation is:
- There are apx 2.000.000 objects.
- Every year and most of them every quarter have to give information using a form.
- The processing is daily. The allowed time frame is 2 hours.
- At the end of a quarter, the number of received messages in a xml format on a single day can top at 300.000.
- A selection result by a ML-model are signals. Output to several destinations.
🎭 Connecting Technical Interfaces
The first activity was getting the interfaces verified working. To solve:
- Autorisations in the connections that should run automated.
- Unicode encoding, sometimes getting in latin-1 and missing urlencode.
- Soap messaging to another system.
Goal set: able to run within an hour and being easily restartable.
Going for a modular system approach of program blocks that are running each for about 1-5 minutes at max.
Small issues are well able to solve within the time-frame.
😉 ✅ Running this without the ML-code most of it worked.
🎭 Changing first group the way delivering signals
- There is already a first group feed with the ML-signals. Al is run manually in a poc, that now should run automated.
- The technical interface is at new point at the business value stream and there are many more of those. The situation is more complex than the manual poc.
Goal set: change the involved first customer group to use signals by the new automated daily process.
Instructions to persons supporting the delivery doing manual actions are changed.
😉 ✅ These changes went well.
🎭 Changing first group to a new user-process
At the users no integrated application for review did exist. That one is build by another department getting those soap-messages.
- The regular new user-process replacing the local build one.
Goal set: When this conversion step is successful other groups can also migrated.
🤔 ❌ The new user-process is not accepted by the users seeing the cases with real production data. This interface technically stopped for a period.
Development & testing was done with simulated data not being realistic enough. Rebuilding and verifying is continued with manipulated real data in a controlled way.
😉 ✅ The rebuild new user-process got accepted.
🎭 Changing functional management to run the new process
The first user group got converted. The daily operations should become regular.
- All old solutions can go now to the new working process.
- The daily process scheduling All old solutions can go now to the new working process.
Goal set: abandoning all old local solutions. The new process regular run.
🤔 ✅ The abandoning old local solutions successful. A regular process running outside ICT responsibilities more challenging.
😲 ❓ Changes in ICT tools - opinions how to run are hitting the new process.
Mass data, streaming coming in at monthly flows
The situation is:
- There are apx 10.000.000 objects.
- Change is not predictable. For normal reasons a 10% yearly mutation change is expected.
- Mutations are of messages type with a before/after and unique key identification.
- A complete situation of all objects as-is on a moment can be requested. This as-is is a split in partial deliveries each sized at 100.000 objects
- Every object is described by possible 70 logical record types.
🎭 Process a limmited number of logical information of an as-is situation
With focus on about 15 elements getting to understand the data and how it can get processed.
😉 ✅ Using the XML table processing using 10 of the partial deliveries he DBMS it looks to get workable.
The additional prerequisite is having key identification tables defined with content that is in the XML-file.
For the sizing reason a xml split program had to get coded. That one luckily enough is able to create that key identification table.
🎭 Sizing up the 15 elements to do all objects.
Sizing up is introducing the problem of size and performance.
😉 ✅ Running mass objects of small XML files runs marvelous. For some there not explainable issues, running outside office hours helps.
🎭 Sizing up to all objects and all elements.
This sizing up is introducing coding issues. Far too much code when running partials
😉 ✅ Generating code out of templates solves size and performance issue.
🎭 Adding the mutations.
This introduces new issues for the number of files messages coming in on a day (up to 100.000) most are updates for technical reasons.
The performance problem getting in on a small number of mutations messages.
🤔 ✅ The archiving (zip) is the unsolvable technical question. It crashes on the number of small files.
😱 ❌ The performance problem got analysed as a problem in the DBMS going into trashing when the message exceeds a size in number records.
🎭 Trying to get the process regular.
Handing over this working solution to other persons was trying to hand over all technical challenges developing testing operating together.
🤔 ❌ Too many technical issues. Not aligned with ICT. All beyond comfortzone.

The business process involved before was doing operationalisation ML model. In a technical smaller environment again going for this.
The diference: a proces was already running. Missing some important phases in the SDLC.
Preparing data for ML, Machine Learning
With ML a statement is made wiht data on some type of object.
- Would the customer buy this product, in what probability?
- Expectations the person would get harmed by doing this type of work?
- Is this tax form correct, what would be the level of dicrepedancies.
- What is the creditability of this company?
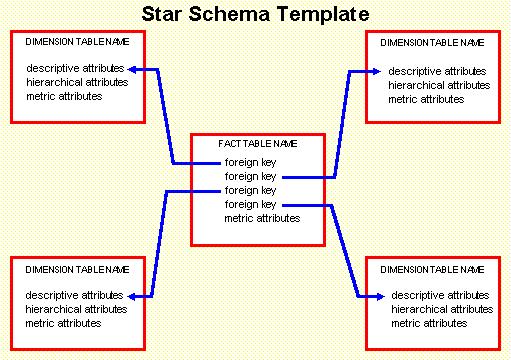
The object that is going to be scored is in a data model in the same position as the fact table in a star schema used in a dwh data model.
There are a lot of differences it is more an ER-model similar to the dwh starschema.
Differences to common dwh star model are:
- Data is not complete consistent nor having complete integrity.
not all elements available are valid for scoring.
- More data pipelines are needed,
Develop with parallel development and the Test Acceptance Production lines.
- Dimensions not normalised,
denormalised dimensions are on topic are sufficiënt.
- When doing partial updates, what objects have been touched.
These differences are a logical result of the goal with a data pipeline for ML.
The situation is:
- There are apx 7.000.000 objects each for different geolocations. About 2.000.000 are really active
- In the dimensions up to 40.000.000 records are expected.
- Change in the scoring is verified daily. For one geolocation during office hours to update every 15 minutes.
- Scores, results by updates and/or messaging in a feed back to other systems.
🎭 Having duplicated pipelines.
Goal set: Enable switch processing over machines, enable software gets upgraded.
Understanding how the live process is run, found a possible synchronisation moment in the early morning.
A fresh new data pipeline using a full load of data was not possible because there too much differences.
😉 ✅ Switching between machines upgrading software successful done.
🎭 Solving data issues enabling the full load.
Goal set: remove all data differences with the origins.
A full load of all data just is just about 10 minutes. Doing that daily is no problem. A full load and identical data frees the options for the DTAP ML score pipelines.
😉 ✅ In cooperation all differences are eliminated step by step. Avoiding too much impact in results as much as possible.
🎭 changing the ML data preparations.
Goal set: remove dependencies in the processing moving to program units that are modular / restartable.
Dependencies are causing changes to be too difficult. The impacted objects by partial mutations is a core dataset for partial update processing.
😉 ✅ In several steps the data preparation changed.
🎭 Adding new scoring logic with a watch dog.
Goal set: make the scoring process manageable controllable when doing changes.
Making some mistakes by accident is casuing too much trouble. Adding a lot of logic for valditing input data and score results that should not change too fast.
The saving of changes score results is adding far more opportunities in a new kind of data model only have those score changes.
😉 ✅ In several steps the scoring process changed.
🎭 Adding new scores aside to old ones.
Goal set: Adding new scores in the modular set up is now doable.
New scores are added in the process, new methods of delivery added.
The relative small dataset of all scores putting them in a database in the fastest way is lasting for about 40 minutes.
😉 ✅ In several steps the new scores are added.
🎭 Two new geo locations added.
Goal set: Duplicate the well run process to use other data-sources delivering scores using another model.
😉 ✅ Duplicating the well running approach got well running other copies.
😲 ❓ Uhh what is up now? Performance issues to dig in. There are unexplainable differences between the development (test acceptance) and production machine.
Deduced to a bad system IO setup that was somewhat improved by adding storage in development. Some coding improved that is sensitive to this bad IO system and doing a scheduling with geo time sliced solved that all.
🎭 All issues solved?.
Goal set: Backup & archiving important information.
😉 ✅ The full load and production scores are solved.
😲 ❓ The training and validation of the ML development is an issue. Models using 60Gb of data to develop code is possible. That kind of source data is not what versioning tools are meant to deal with.
😱 ❌ Explainability Traceability of ML models.
This problem is conceptual because it is not about some code lines what the real source is but it is that data with the used ML tools.

Information is not always needed in mass details. Getting validated summarised in many classes and subclasses is a different valid approach.
In that case the variability for the volatility in questions to answer is the technical problem.
Regulator retreiving information
The situation is:
- There is a process in place using old technology. Technology should be replaced.
- Too little technical knowledge is present in understanding all code and steps. Simplifying is an additional request.
- The data information is coming in at quarterly moments. The templates for those are relative small (Excel apx 1.000 rows).
- When the data is coming in some additional calculations for consistency is an additional request.
🎭 Analyses the technical and logical old situation.
Goal set: The first actions is trying to understand what is running and what the logical information flow is.
It seems an easy technical conversion. The information is not very big, the sizing of all history (15 years) is below 1 Gb
😉 ✅ Getting access and explanation of how they are working well communicated. An very huge basic analyses program does help a lot.
🤔 ❓ ❌ The information flow is technical far too complicated. An easy migration is not doable. A new plan for the migration to invent.
Extension of the situation:
- The datasets are all connected with technical surrogate keys. The real business keys are hardly visible. (Normalisation was done too rigorous).
- All elements have got an unique surrogate key but a unique key with description is missing. That logic is found in that huge program.
- Building a new quarterly template those surrogate keys of elements are to be copied. This is manual work (copy paste) easily introducing errors. No easy validations are possible.
The project changed to an interesting not usual type of information processing.
Usually the process is a push approach I, II. Input data and results are defined.
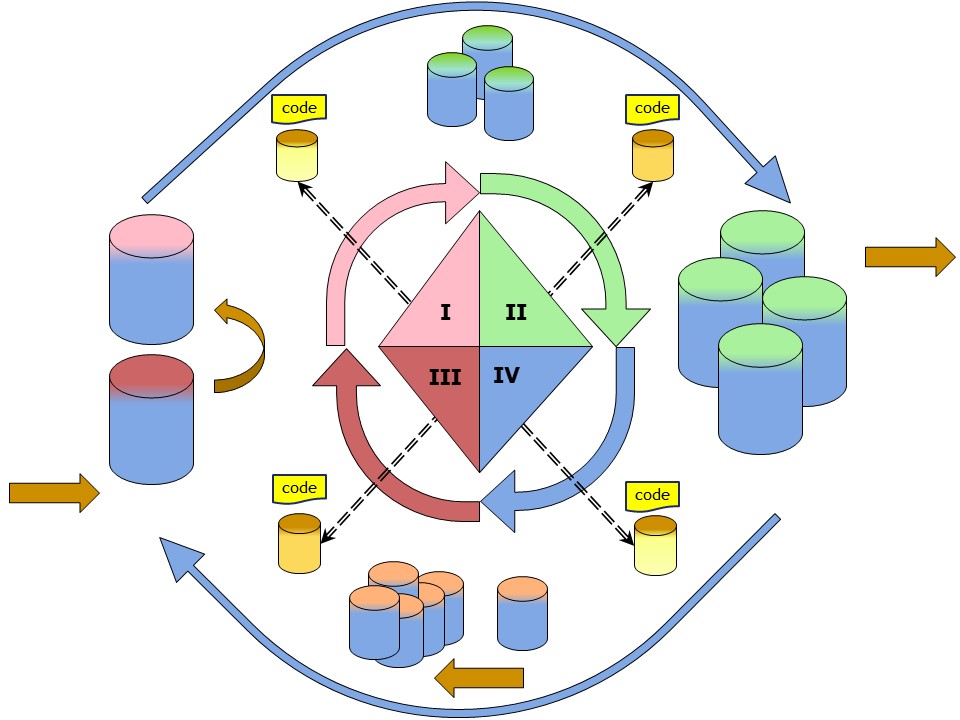
The available information (input) is a fixed layout.
output, results, having a goal are in a relational format using columns.
Adding the information request for what is needed, is the new mind setting.
It is changed into a pull request adding IV, III. A full process circle with validations.
🎭 Replace surrogates into logical business keys, naming conventions on elements.
Goal set: Simplifying data model and data processing. Assure that data delivery is workable.
😉 ✅ Doing this in a small scale "proof of concept" accepted.
🎭 Going for conversion of historical, data validating integrity.
Goal set: Define all elements by a name instead of surrogate key, using that huge program.
😉 ✅ Looking at original sheets and processed data many years are done.
😲 ❓ Uhh what is up? In a verification of results some names and conventions have to change. Calculations having an important reason.
Recoding some parts and doing the conversion during code adjustments is working very fast. Correcting these parts is a minor task.
The variety in record types elements with related period adjustment is complicated. Each solved step by step.
🎭 Defintive partial datasets set, new data to come in.
Goal set: processing of new data using new templates.
😉 ✅ Changed the data-sheet to leading, no surrogates are used anymore.
Using a table with 3 columns and an additional decalartive text makes the template easier to understand and easier to understand.
Showing all this, it is accepted.
🎭 The delivery in a dedicated results format.
Collecting the data and presenting in relational tables is working. Th resist are processed using an other pre-defined layout.
Goal set: How to define a shopping list to deliver the Ha a Define all elements by a name instead of surrogate key, using that huge program.
😉 ✅ Looking at original sheets and processed data many years are done.
🤔 ❓ Some open ends are left for others. What was wanted is done.
The shopping list was setup using a quarterly moment. Not all of them are equal. That shopping list is to change regular.
That process has more optimisation possibilities. Some persons are aware of that, but is not a management priority.

Removing bottlenecks, mass processing or high variety
Streamlining processes is a tedious task. Sometimes missing the intention sometimes targets are changing when some results are deleivered.
The targets and resuslt sometimes are not even aligned to each other when not mentioned goals are in the game.
The examples of experiences are showing all intermediate steps, sprints. No one was an easy prediactable journey.
No one was ended with an ideal end situation, some got outdated (legacy), others didn&actet finish with a handover of knowledge.
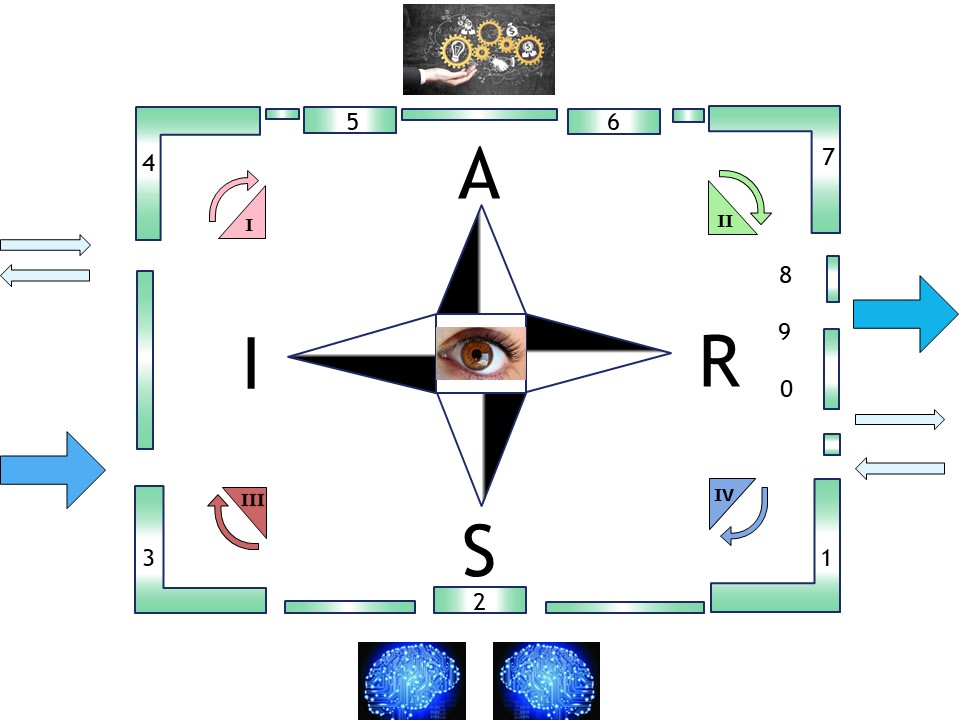
💡 The questions for what to do are done in this cycle.
Understanding the Situation.
Plan Initatives,
Do Actions,
Check Results,
Act on the new Situation
(repeat).
Words of thank to my former colleagues
We had a lot fun in stressfull times working out this on the mainframe in the nineties. The uniquenes and difficulties to port it to somewhere else realising.
A few names:
Not always unhappy by what is going on